テスラ AI DAY スーパーカット
テスラのAIデーの、ニューラル・アルゴリズム及びシミュレーション部分のスーパーカットです。
ここで解説されている手法は実務でも利用されているものもあり、その点にモートがあるわけではありません。しかしそれらをすべて統合し、人間の視覚野のシミュレーションともいうべきシステムを構築してしまったこと、それを用いて大規模にトレーニングするためのデータおよび演算環境をそろえてしまっていること。
これは他社では絶対に真似できません。
テスラに唯一近いアプローチを採用している企業は、ジョージ・ホッツのC3.AI (シンボル $AI)ですが、フォーカスしている市場が異なること、データ収集においてはお話にならないことなど、自動運転に関してはテスラに大きく引き離されています。
また、とりわけLiDARを利用して3Dマップを作っているそれ以外の無数の他社のエンジニアは「とりあえずデモを出して何も知らない役員をゴマかしているけど、この技術の先に本当に自動運転が実現できる未来があるのか?」と自問していることでしょう。
その他社の役員は、自社の自動運転の「デモのためのデモ」を見て悦にいっているとともに、それを使っていかに顧客を目くらましするかを日々考えていることでしょう。
①アンドレイ:アーケティクチャー全体:ベクタースペースの生成
②アショック:オートラベリング
③アンドレイ:データ収集
④アショック:シミュレーション
の順番で話が進みます。
トピックは以下です。
〇イーロンが登壇

what we want to show today is that tesla is much more than an electric car company that we have deep AI activity in hardware on the inference level on the training level
we're arguably the leaders in real world AI as it applies to the real world those of you who have seen the full self-driving beta i can appreciate
the rate at which the tesla neural net is learning to drive this is
a particular application of AI but there's more
there are applications down the road that will make sense
i want to encourage anyone who is interested in solving real-world AI problems at either the hardware or the software level to join tesla or consider joining tesla
〇ANDREJが登壇
i lead the vision team here at tesla autopilot and i'm incredibly excited to be here to kick off this section
giving you a technical deep dive into the autopilot stack and showing you all the under the hood components that go into making the car drive by itself in the vision
component what we're trying to do is we're trying to design a neural network that processes the raw information
which in our case is the eight cameras that are positioned around the vehicle and they send those images and we need to process that in real time into the vector space
and this is a three-dimensional representation of everything you need for driving
so this is the three-dimensional positions of lines edges curbs traffic signs traffic lights cars their positions orientations depth velocities and so on
〇これをやりたいんですけどね。

here i'm showing the video of the raw inputs that come into the stack and then neural net processes that into the vector space
and you are seeing parts of that vector space rendered in the instrument cluster on the car
what i find fascinating about this is that we are effectively building a synthetic animal from the ground up
the car can be thought as an animal.
it moves around it senses the environment and acts autonomously and intelligently
we are building all the components from scratch in-house
so we are building all the mechanical components of the body the nervous system which is all the electrical components
and for our purposes the brain of the autopilot and specifically for this section the synthetic visual cortex
now the biological visual cortex actually has quite intricate(入り組んだ) structure and a number of areas that organize the information flow of the human brain
in your visual cortexes light hits the retina(網膜)
it goes through the LGN all the way to the back of your visual cortex
then goes through areas v1 v2 v4 the IT
the venture on the dorsal streams and
the information is organized in a certain layout
when we are designing the visual cortex of the car
we also want to design the neural network architecture of how the information flows in the system
〇視覚野のアナロジー
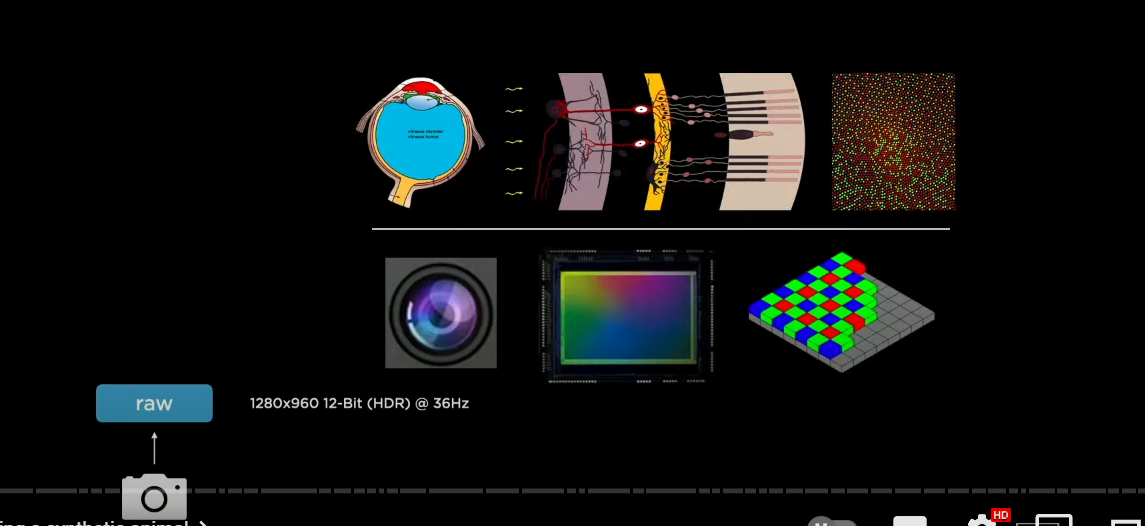
the processing starts when light hits our artificial retina and we are going to process this information with neural networks
now i'm going to roughly organize this section chronologically(年代順に)
starting off with the neural networks
what they looked like four years ago when i joined the team and how they have developed over time
four years ago the car was mostly driving in a single lane going forward on the highway
and it had to keep lane and it had to keep distance away from the car in front of us
and at that time all of processing was only on individual image level
so a single image has to be analyzed by a neural net
and make little pieces of the vector space
process that into little pieces of the vector space
so this processing took the following shape
we take 1280 by 960 input and this is 12 bit integers streaming in at roughly 36 hertz
now we're going to process that with the neural network
〇レジデュアルNN→レグネッツ
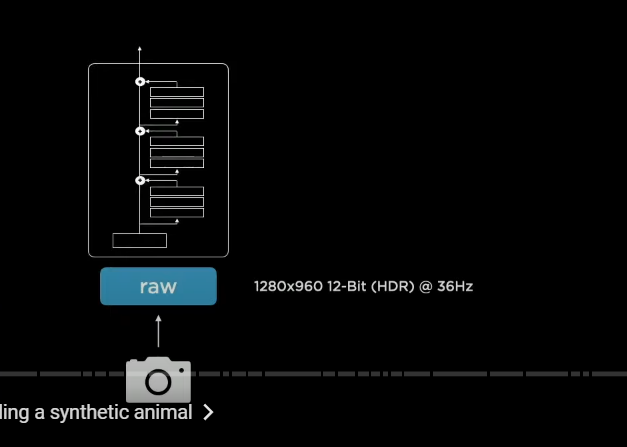
so instantiate(インスタンス化する) a feature extractor backbone
(レジデュアルNNを使った特徴抽出バックボーン)
in this case we use residual neural networks
we have a stem and a number of residual blocks connected in series
(ステムとレジデュアルブロックス)
now the specific class of resnets that we use are called regnets
regnets offer a very nice design space for neural networks
(レグネッツによるNNデザインスペース)
because they allow you to nicely trade off latency and accuracy
(レイテンシとアキュラシのトレードオフ)
〇REGNETS

now these regnets give us a number of features as an output at different resolutions in different scales
so in particular on the very bottom of this feature hierarchy
we have very high resolution information with very low channel counts
ボトム(160*120*64)→ディティール把握
and all the way at the top we have low spatial,low resolution but high channel counts
トップ(20*15*512)→概要とコンテクストを把握
so on the bottom we have a lot of neurons that are really scrutinizing the detail of the image
and on the top we have neurons that can see most of the image and have a lot of that scene context
〇BiFPN

then we like to process this with feature pyramid networks(フィーチャーピラミッドネットワーク:FPN)
in our case we like to use BiFPNs
residual NN = Regnets
feature pyramid networks = BiFPNs
and they get to multiple scales to talk to each other effectively and share a lot of information
so for example if you're a neuron all the way down in the network
you're looking at a small patch and you're not sure this is a car or not
ihelps from the top players are useful
like hey you are actually in the vanishing point of this highway
and so you can disambiguate that this is probably a car
〇検出を担当するヘッドでの、車両の検出ケース

after BiFPN and a feature fusion across scales
then we go into task specific heads(単体のヘッド)
so for example if you are doing object detection
we have a one stage yolo like object detector here
where we initialize a raster(ラスターイメージ) and there's a binary bit per position telling you whether or not there's a car
and then in addition to that if there is a car
here's a bunch of other attributes you might be interested in
so the x y with height offset or any of the other attributes like what type of a car is this and so on
so this is for the detection by itself
〇単体のヘッドとハイドラネットの違い
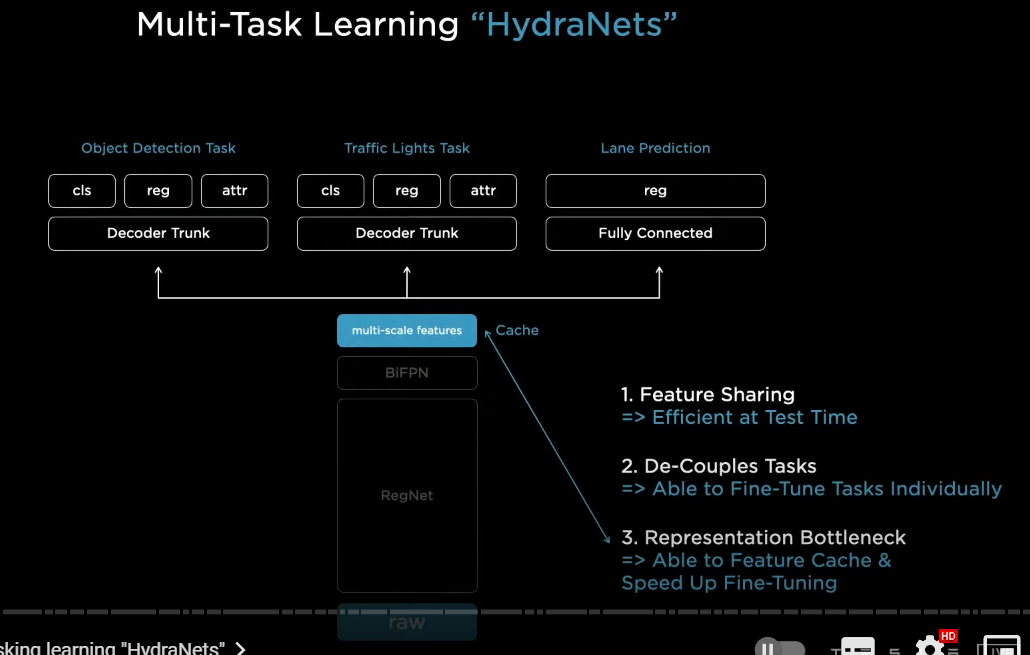
now very quickly we discovered that we don't just want to detect cars
we want to do a large number of tasks
for example we want to do traffic light recognition and detection a lane prediction and so on
quickly we converge in this kind of architectural layout
where there's a common shared backbone and then branches off into a number of heads
so we call these therefore hydranets and these are the heads of the hydra
this architectural layout has a number of benefits
以下はハイドラネットの利点
1
number one because of the feature sharing we can amortize the forward pass inference in the car at test time and so this is very efficient to run
because if we had to have a backbone for every single task that would be a lot of backbones in the car
2
number two this decouples all of the tasks so we can individually work on every one task in isolation
and for example we can upgrade any of the data sets or change some of the architecture of the head and so on
and you are not impacting any of the other tasks and so we don't have to revalidate all the other tasks which can be expensive
3
and number three because there's this bottleneck here in features
so we cache these features to disk and
when we are doing these fine tuning workflows, we only fine-tune from the cached features up and we only fine tune the heads
in terms of our training workflows
we will do an end-to-end training run
once in a while where we train everything jointly
then we cache the features at the multi-scale feature level
and then we fine-tune off of that for a while
and then end-to-end train once again and so on
〇画像上(2D)でのラベリング
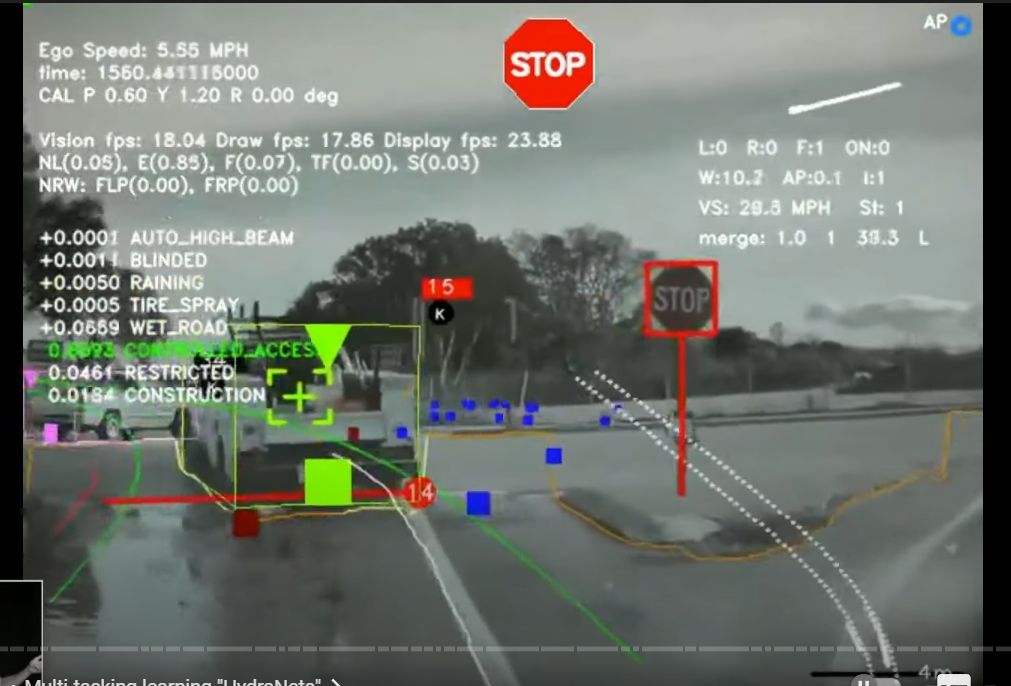
so here's predictions that we were obtaining several years ago from one of these hydro nets
again we are processing individual images and we're making a large number of predictions about these images
here you can see predictions of the stop signs the stop lines the lines the edges the cars the traffic lights the curbs whether or not the car is parked all of the static objects like trash cans cones and so on and
everything here is coming out of the Hydra net
so that was all fine and great
but as we worked towards FSD we quickly found that this is not enough
where this first started to break(ほころび始めた、破綻し始めた) was when we started to work on smart summon(スマート・サモンで)
i am showing some of the predictions of only the curb detection task
and i'm showing it for every one of the cameras
so we'd like to wind our way around the parking lot to find the person who is summoning the car
now the problem is that you can't just directly drive on image space predictions (カメラ画像により表示されている映像(2D)、その中をドライブしていくやり方ではうまくいかなかった。)
you actually need to cast them out and form a vector space around you
〇 オキュパンシートラッカー(ダメ)
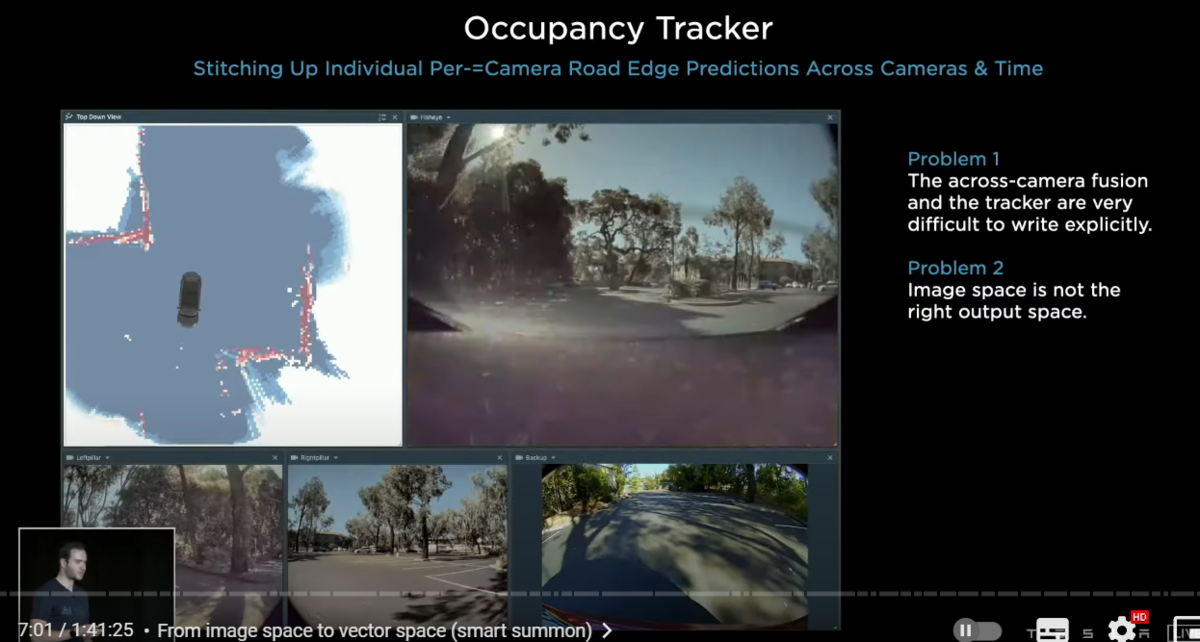
we attempted to do this using c++ and developed the occupancy tracker(オキュパンシー・トラッカー) at the time
here we see that the curb detections from the images are being stitched up across camera scenes across camera boundaries
and over time there have been two major problems with the setup
以下問題点
1
number one we very quickly discovered that tuning the occupancy tracker and all of its hyper parameters was extremely complicated
you don't want to do this explicitly by hand in c++
you want this to be inside the neural network and train that end-to-end
2
number two we very quickly discovered that the image space is not the correct output space
you don't want to make predictions in image space
you really want to make it directly in the vector space
〇2Dラベリングを、ベクタースペースに投影してみると。。。

here's a way of illustrating the issue
i'm showing on the first row the predictions of our curves
and our lines in red and blue they look great in the image
but once you cast them out into the vector space
things start to look really terrible and we are not going to be able to drive on this
you can see how the predictions are quite bad and the reason for this is because you need to have an extremely accurate depth per pixel in order to actually do this projection
(この方式だと、1ピクセル毎の超正確な深度が必要→それは無理)
and so you can imagine just how high of the bar it is
to predict that depth in these tiny every single pixel of the image so accurately
and also if there's any occluded area where you'd like to make predictions
you will not be able to predict it because it's not an image space concept
〇カメラごとに検出して、フュージョンする問題点

2
the other problems with this is also for object detection
if you are only making predictions per camera then sometimes you will encounter cases like this
where a single car actually spans five of the eight cameras(8カメラ中5カメラをスパンする車両)
so if you are making individual predictions
then since no single camera sees all of the car and you're not going to be able to do a very good job of predicting that whole car
and it's going to be incredibly difficult to fuse these measurements
〇マルチカメラ画像をどのようにベクタースぺースに統合していったのか
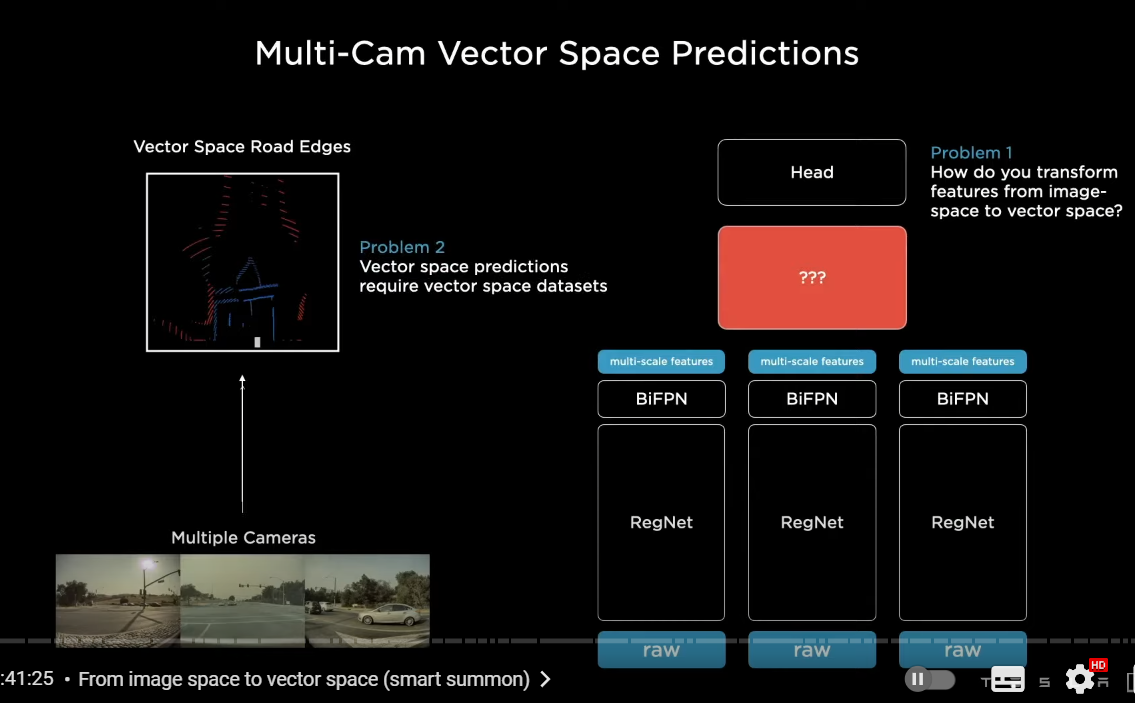
so instead we'd like to take all of the images and simultaneously feed them into a single neural net and directly output in vector space
now this is very easily said much more difficult to achieve
but roughly we want to lay out a neural net in this way
where we process every single image with a backbone and then we want to fuse them
and we want to re-represent the features
from image space features to directly vector space features
(イメージ空間フィーチャーズとベクトル空間フィーチャーズの違い)
and then go into the decoding of the head
(それを各ヘッドでディコーディング)
2-1 トランスフォーマー(今流行りの手法)
so there are two problems with this problem
number one how do you actually create the neural network components that do this transformation
you have to make it differentiable so that end-to-end training is possible
2-2 ベクトル空間向けの特徴量の抽出
number two if you want vector space predictions from your neural net
you need vector-specific based data sets
just labeling images and so on is not going to get you there
you need vector space labels
for now i want to focus on the neural network architectures
i'm going to deep dive into problem number one
〇BEVのある部分と、各カメラ画像のどの部分が対応しているのか
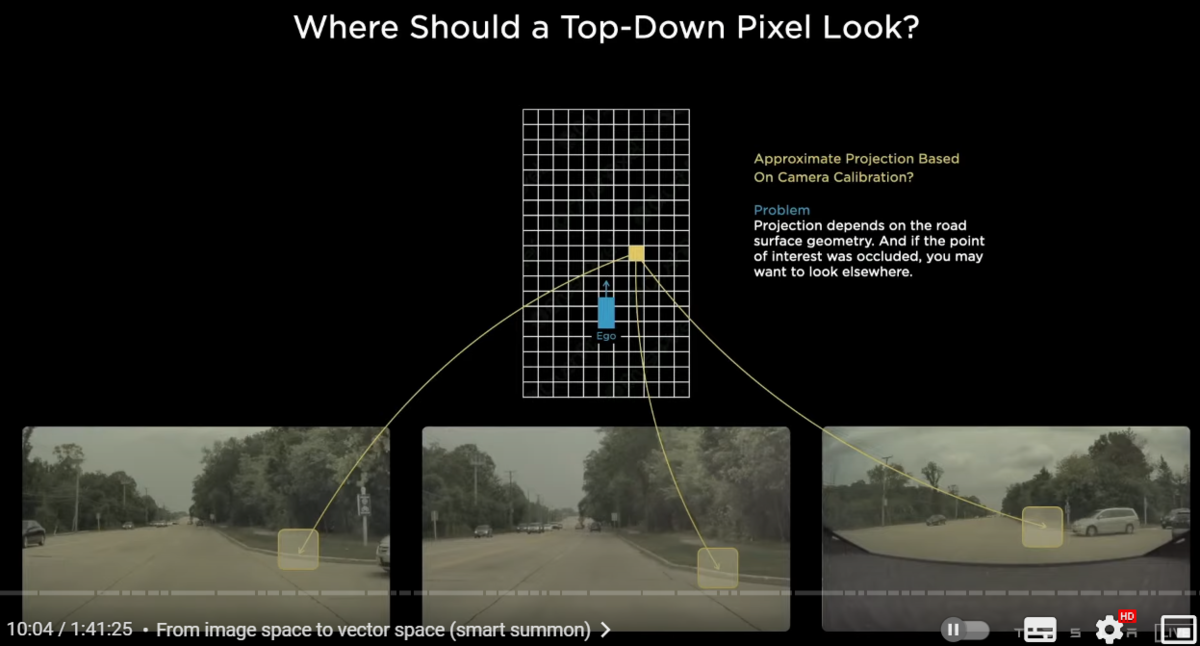
we're trying to have this bird's eye view prediction instead of image space predictions
for example let's focus on a single pixel in the output space in yellow
and this pixel is trying to decide
Am i part of a curb or not
where should the support for this kind of a prediction come from in the image space
we know how the cameras are positioned and
they're extrinsic and intrinsic so we can roughly project this point into the camera images
and the evidence for whether or not this is a curve may come from somewhere here in the images
the problem is that this projection is really hard to actually get correct
because it is a function of the road surface and the road surface could be sloping up or sloping down
also there could be other data dependent issues for example there could be inclusion due to a car
so if there's a car occluding this part of the image
then actually you may want to pay attention to a different part of the image
not the part where it projects
and because this is data dependent it's really hard to have a fixed transformation for this component
〇トランスフォーマーの使用
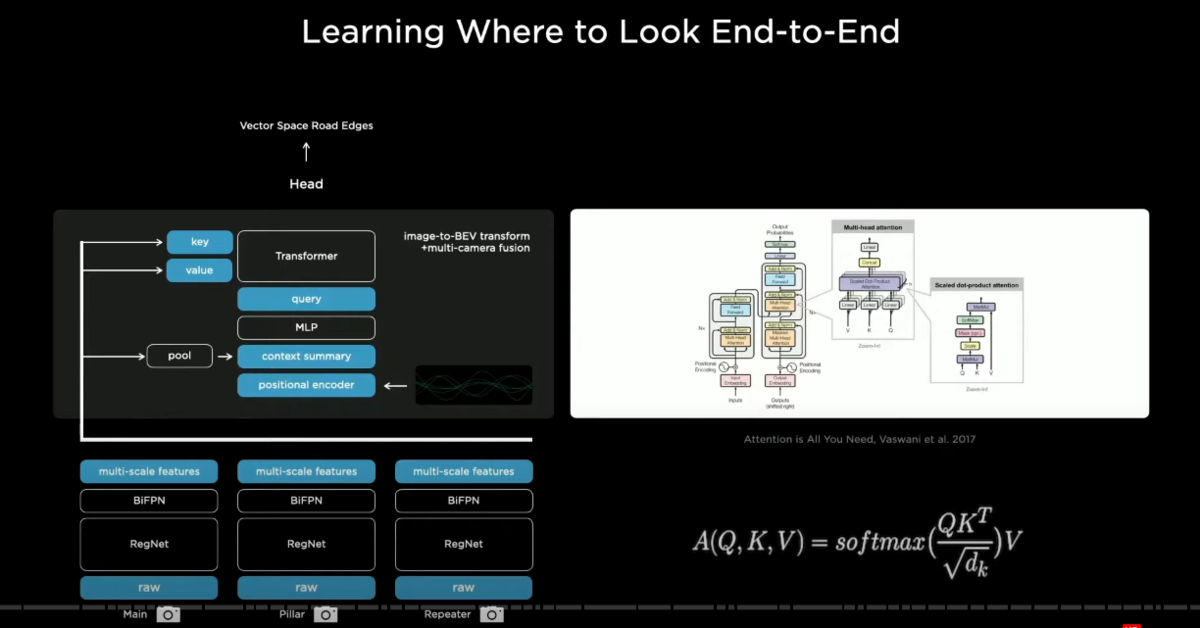
so in order to solve this issue we use a transformer(トランスフォーマー) to represent this space
this transformer uses multi-headed self-attention(マルチヘッド・セルフアテンション)
and blocks off it in this case
we can get away with even a single block doing a lot of this work effectively
what this does is you initialize a raster(ラスターイメージ) of the size of the output space
and you tile it with positional encodings(ポジショナル・エンコーディングズ)
with size and coses in the output space
and then these get encoded with an MLP into a set of query vectors(クエリ―ベクトル)
and then all of the images and their features also emit(放出する) their own keys and values
and then the queries keys and values feed into the multi-headed self-attention
what's happening is that every single image piece is broadcasting what it is a part of in its key
i'm part of a pillar in roughly this location
and i'm seeing this kind of stuff and that's in the key
then every query is along the lines of hey i'm a pixel in the output space at this position
and i'm looking for features of this type then the keys and the queries interact multiplicatively
and then the values get pulled accordingly
and so this re-represents(空間の再表象) the space
and we find this transformation to be very effective if you do all of the engineering correctly
this again is very easily said difficult to do
you need to do all of the engineering correctly
〇カメラキャリブレーション
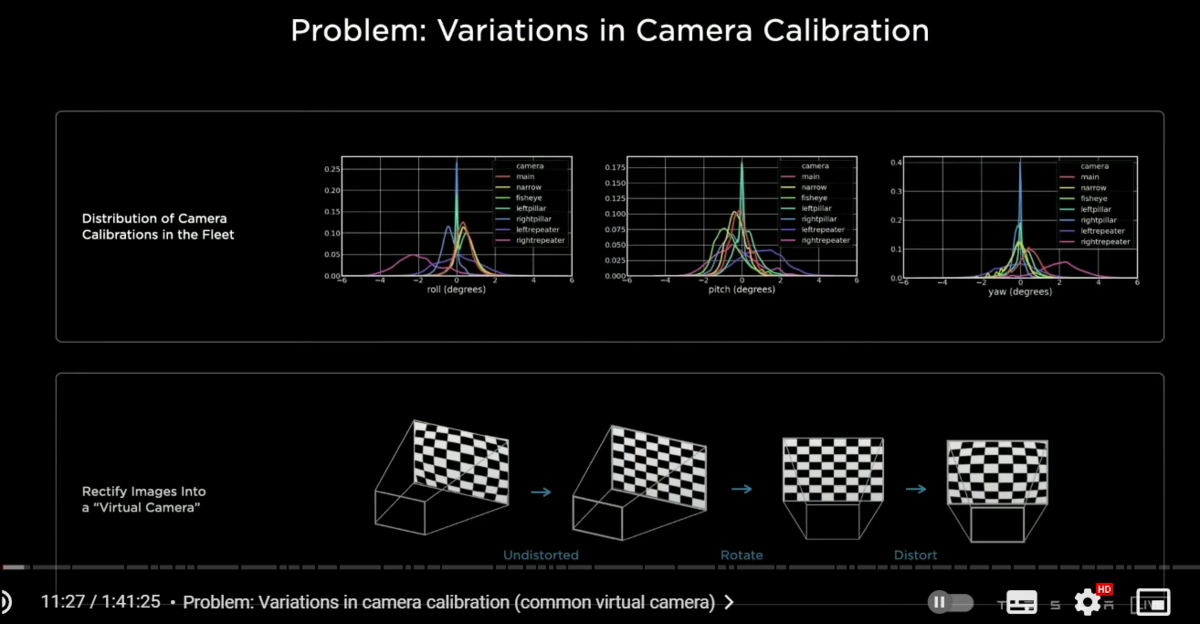
so one more thing you have to be careful with some of the details here when you are trying to get this to work
in particular all of our cars are slightly cockeyed in a slightly different way
and so if you're doing this transformation from image space to the output space
you really need to know what your camera calibration is
and you need to feed that into the neural net
and so you could definitely just like concatenate(文字列を結合する)the camera calibrations of all of the images
and somehow feed them in with an MLP
but we found that we can do much better by transforming all of the images into a synthetic virtual camera(シンセティック・バーチャル・カメラ)
using a special rectification(整流) transform
〇レクティフィケーション→コモンバーチャルカメラ

so this is what that would look like
we insert a new layer right above the image which is rectification layer(整流レイヤー)
it's a function of camera calibration and it translates all of the images into a virtual common camera(バーチャル・コモン・カメラ)
so if you were to average up(次々と平均値を求める) a lot of repeater images(リピーターカメラの画像) for example which faced at the back
without doing this you would get a kind of a blur
but after doing the rectification transformation(整流トランスフォーメーション)
you see that the back mirror gets really crisp(クッキリとした)
this improves the performance quite a bit
〇ドライバブルなベクタースペースの生成
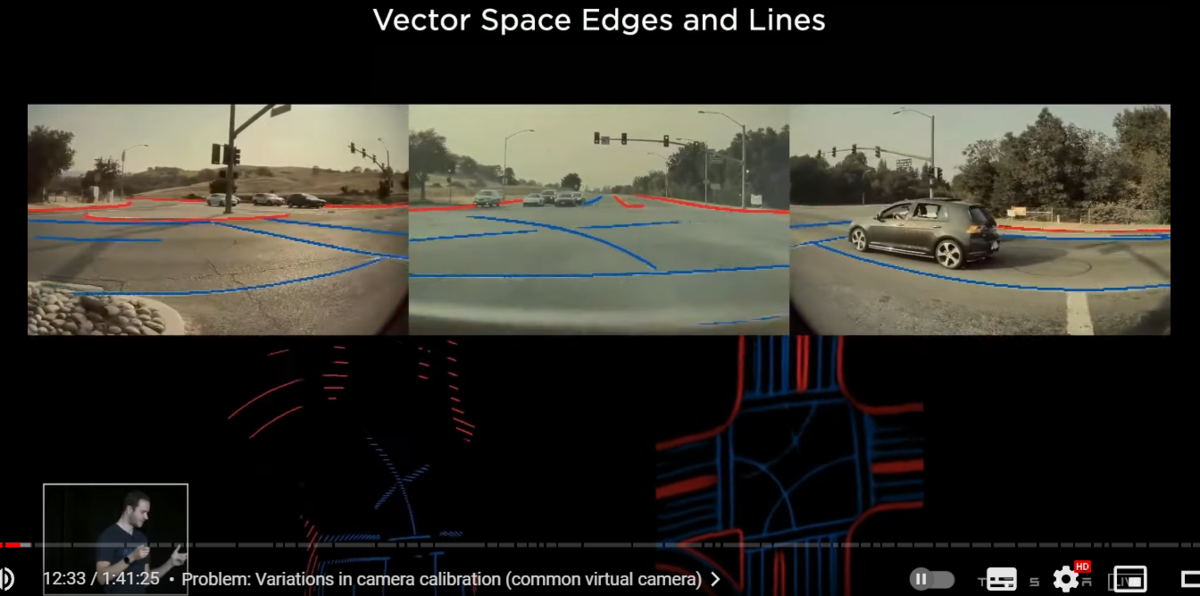
so here are some of the results on the left we are seeing what we had before
and on the right we're now seeing significantly improved predictions coming directly out of the neural net
this is a multi-camera network predicting directly in vector space
it's basically night and day you can actually drive on this
this took some time and some engineering and incredible work from the AI team to actually get this to work and deploy and make it efficient in the car
this also improved a lot of our object detection
〇マルチカムとシングルカムの性能差

so for example here in this video i'm showing single camera predictions in orange
and multi-camera predictions in blue
if you can't predict these cars if you are only seeing a tiny sliver of a car
your detections are not going to be very good
and their positions are not going to be good
but a multi-camera network does not have an issue
here's another video from a more nominal sort of situation
and we see that as these cars in this tight space across camera boundaries
there's a lot of jank that enters into the predictions
and the whole setup just doesn't make sense especially for very large vehicles like this one
and we can see that the multi-camera networks struggle significantly less with these kinds of predictions
so at this point we have multi-camera networks and they're giving predictions directly in vector space
but we are still operating at every single instant in time(個々の瞬間画像) completely independently
〇画像のみの場合の問題点→記憶の欠如

so very quickly we discovered that there's a large number of predictions we want to make that actually require the video context and we need to figure out how to feed this into the net
in particular is this car parked or not
is it moving? how fast is it moving? is it still there? it's temporarily occluded
or for example if i'm trying to predict the road geometry ahead
it's very helpful to know the signs or the road markings that i saw 50 meters ago
〇ビデオニューラルネットアーケティクチャー

so we try to insert video modules(時系列データを認識するビデオモジュール)into our neural network architecture and this is one of the solutions that we've merged on
we have the multi-scale features as we had them from before
and what we are going to now insert is a feature queue module(フィーチャー・キュー・モジュール)
that is going to cache some of these features over time
and then a video module that is going to fuse this information temporally
and then we're going to continue into the heads that do the decoding
now i'm going to go into both of these blocks one by one
also in addition notice here that we are also feeding in the kinematics(キネマティクス/運動学)
this is basically the velocity and the acceleration that's telling us about how the car is moving
so not only are we going to keep track of what we're seeing from all the cameras
but also how the car has traveled
〇フィーチャーキューモジュール

so here's the feature cue and the rough layout of it
we are basically concatenating(連結する) these features over time
and the kinematics of how the car has moved
and the positional encodings and that's being concatenated encoded and stored in a feature queue
and that's going to be consumed by a video module
now there's a few details again to get right
in particular with respect to the pop and push mechanisms
and when do you push
〇時間と空間の記憶

here's a cartoon diagram illustrating some of the challenges
there's going to be the ego cars coming from the bottom and coming up to this intersection here
and then traffic is going to start crossing in front of us
and it's going to temporarily start occluding some of the cars ahead
and then we're going to be stuck at this intersection for a while and just waiting our turn
this is something that happens all the time and it's a cartoon representation of the challenges
so number one with respect to the feature queue and when we want to push into a queue
obviously we'd like to have a time-based queue
where for example we enter the features into the queue say every 27 milliseconds
and so if a car gets temporarily occluded
then the neural network now has the power to be able to look and reference the memory in time
and learn the association that hey even though this thing looks occluded right now
there's a record of it in my previous features
and i can use this to still make a detection
for example suppose you're trying to make predictions about the road surface and the road geometry ahead
and you're trying to predict that i'm in a turning lane and the lane next to us is going straight
then it's really necessary to know about the line markings and the signs
and sometimes they occur a long time ago
and if you only have a time-based queue(時間ベースのキュー) you may forget the features
while you're waiting at your red light
so in addition to a time-based queue we also have a space-based queue(空間ベースのキュー)
we push every time the car travels a certain fixed distance
in this case we have a time based queue and a space-based queue to feed to cache our features
and that continues into the video module
〇ビデオモジュール
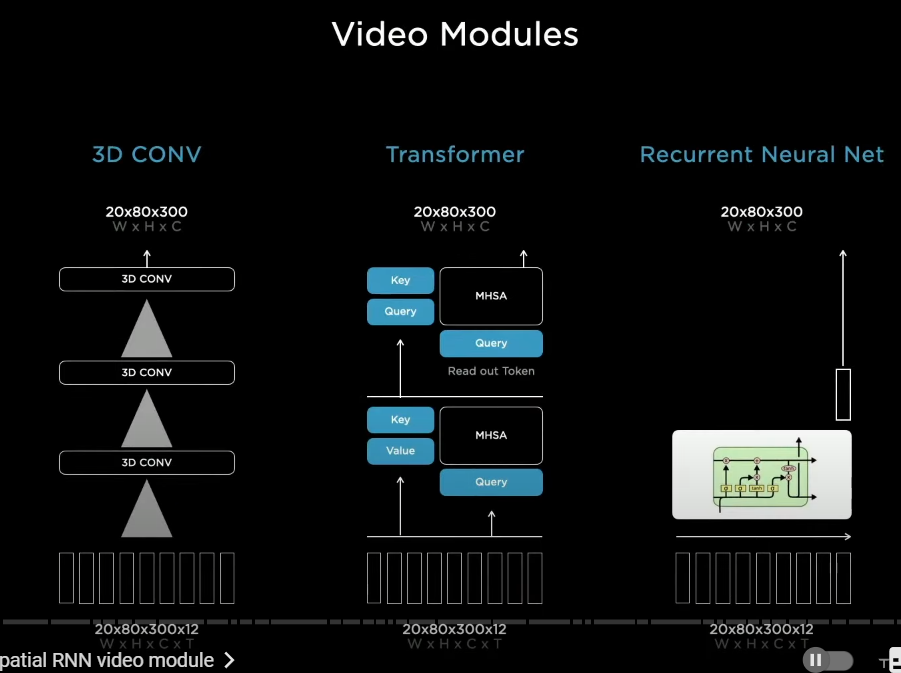
now for the video module we looked at a number of possibilities of how to fuse this information temporally
so we looked at three-dimensional convolutions transformers, axial transformers
(3Dコンボリューション・トランスフォーマーズ、アクシャル・トランスフォーマーズ)
in an effort to try to make them more efficient recurrent neural networks (RNN) of a large number of flavors
〇空間RNNビデオモジュール

i want to spend some time on is a spatial recurrent neural network video module(空間RNNビデオ・モジュール)
because of the structure of the problem we're driving on two-dimensional(2D) surfaces
we can actually organize the hidden state into a two-dimensional lattice(2Dラティス)
and then as the car is driving around
we update only the parts that are near the car and where the car has visibility
so as the car is driving around
we are using the kinematics to integrate the position of the car in the hidden features grid
and we are only updating the RNN at the points where we have that are nearby us
〇多様な空間認識が生まれる
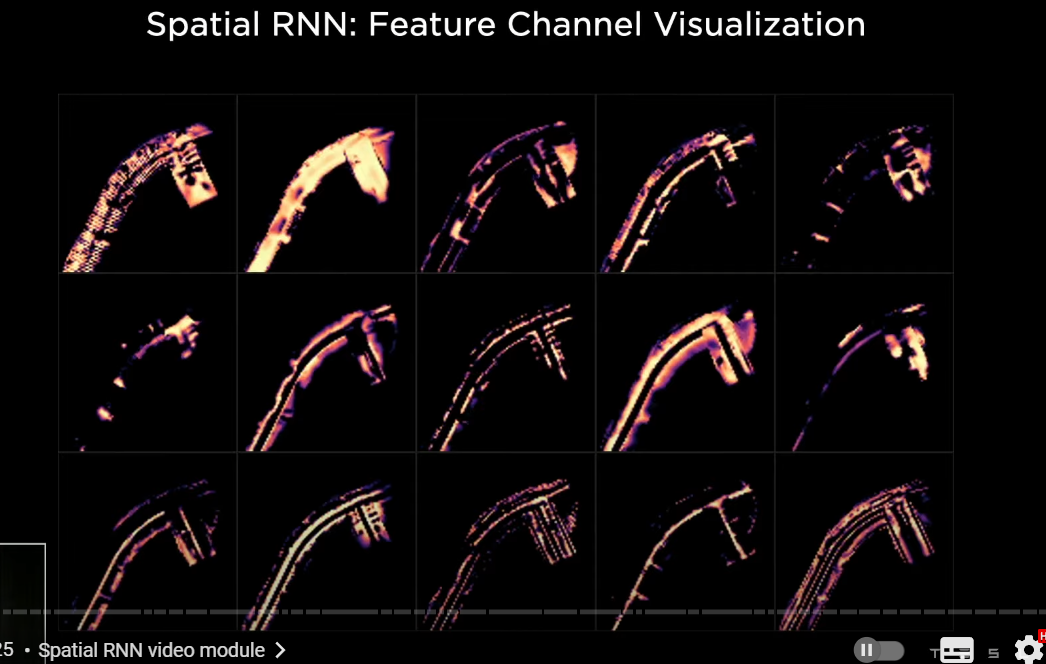
here's an example of what that looks like
the car is driving around
and we're looking at the hidden state of this RNN
and these are different channels in the hidden state(短期記憶、ワーキングメモリの役割を果たす)
so after optimization and training this neural net
some of the channels are keeping track of different aspects of the road
for example the centers of the road the edges the lines the road surface and so on
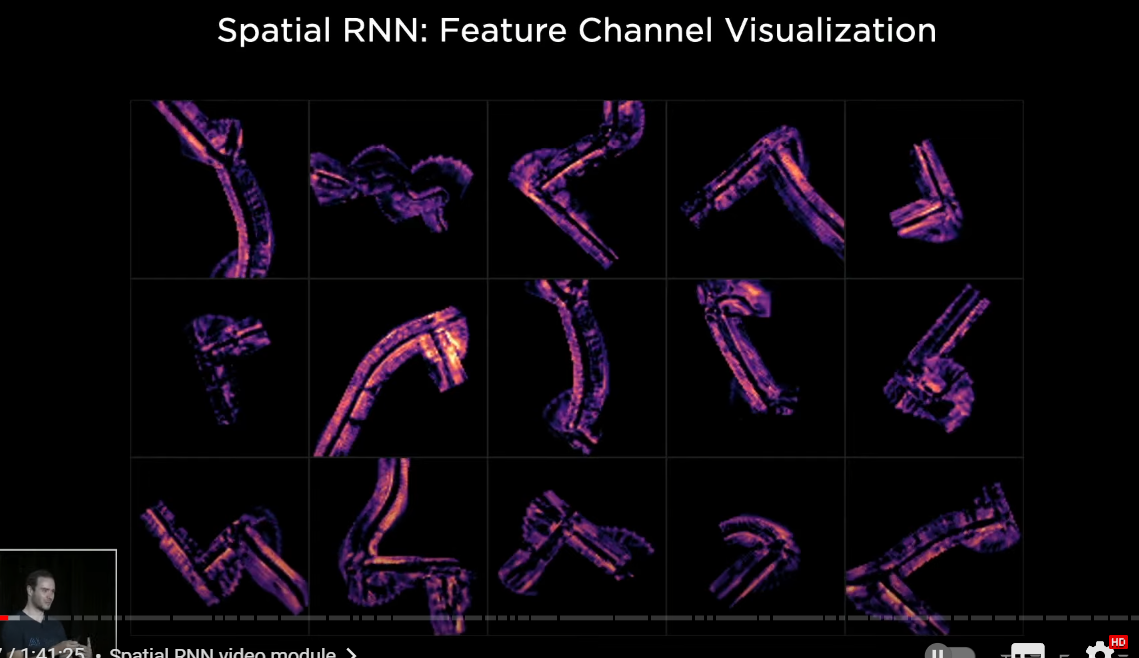
so this picture is looking at the mean of the first 10 channels for different traversals of different intersections in the hidden state
there's cool activity as the recurrent neural network is keeping track of what's happening at any point in time
and you can imagine that we've now given the power to the neural network
to actually selectively read this memory and write to this memory
so for example if there's a car right next to us and is occluding some parts of the road
then now the network has the ability to not to write to those locations
but when the car goes away and we have a good view
then the recurring neural net can say okay we have very clear visibility we definitely want to write information about what's in that part of space
〇空間RNN
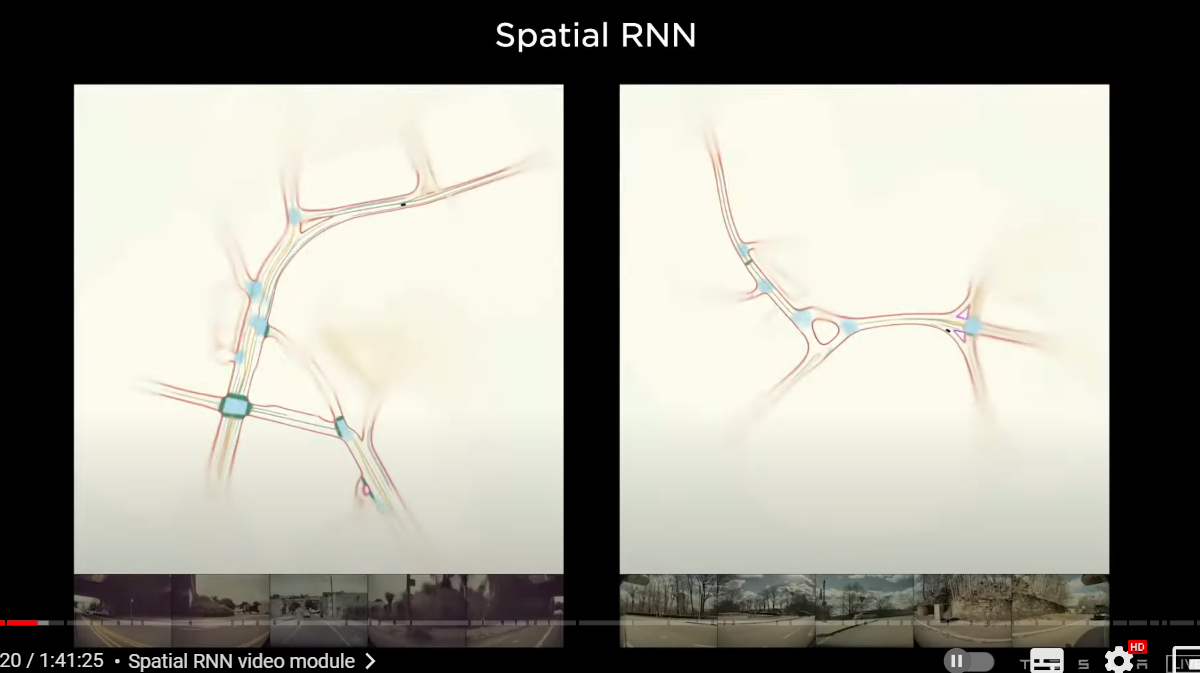
here's a few predictions that show what this looks like
here we are making predictions about the road boundaries in red
intersection areas in blue road centers and so on so
we're only showing a few of the predictions here
just to keep the visualization clean
and yeah this is done by the spatial RNN(空間RNN)
and this is only showing a single clip
a single traversal but you can imagine there could be multiple trips through here
and number of cars a number of clips could be collaborating to build this map
which is an HD map
except it's not in a space of explicit items
The “HD map”is in a space of features of a recurrent neural network
the video networks also improved our object detection
〇ビデオネットワークによる、ドロップの改善

(オクルードされた場合に、ビデオモジュールでは2台の車両は、ディテクトされているのに、シングルフレームでは、ドロップしている)
so in this example i want to show you a case where there are two cars over there and one car is going to drive by and occlude them briefly
so look at what's happening with the single frame predictions
and the video predictions as the cars pass in front of us
so that makes a lot of sense so a quick playthrough through what's happening when both of them are in view
the predictions are roughly equivalent
and you are seeing multiple orange boxes
because they're coming from different cameras
when they are occluded the single frame networks drop the detection
but the video module remembers it and we can persist the cars
and then when they are only partially occluded
the single frame network is forced to make its best guess about what it's seeing and it's forced to make a prediction and it makes a terrible prediction
but the video module knows that there's only a partial
knows that this is not a very easily visible part right now and doesn't actually take that into account
〇深度と加速度の改善

we also saw significant improvements in our ability to estimate depth and especially velocity
so here i'm showing a clip from our remove the radar push
where we are seeing the radar depth and velocity in green
and we were trying to match or even surpass the signal just from video networks alone
and what you're seeing here is in orange
we are seeing a single frame performance
and in blue we are seeing again video modules and so you see that the quality of depth is much higher
and for velocity
the orange signal, you can't get velocity out of a single frame network
so we just differentiate depth to get that but the video module is right on top of the radar signal
and so we found that this worked extremely well for us
〇現段階の全体図

so here's putting everything together this is what our architectural roughly looks like today
we have raw images feeding on the bottom
they go through a rectification layer to correct for camera calibration
and put everything into a common virtual camera
we pass them through regnet's (residual networks) to process them into a number of features at different scales
we fuse the multi-scale information with BiFPN
this goes through transformer module to re-represent it into the vector space
in the output space this feeds into a feature queue in time
or space that gets processed by a video module like the spatial rnn
and then continues into the branching structure of the hydra net
with trunks and heads for all the different tasks
so that's the architecture roughly what it looks like today
and on the right you are seeing some of its predictions which visualize both in a top-down vector space
and also in images this architecture has been definitely complexified from just very simple image-based single network about three or four years ago
and continues to evolve
now there's still opportunities for improvements that the team is actively working on
you'll notice that our fusion of time and space is fairly late in neural network terms
we can do earlier fusion of space or time
and do cost volumes or optical flow like networks on the bottom
or our outputs are dense rasters(ラスタ)
and it's actually pretty expensive to post-process some of these dense rasters in the car
and we are under very strict latency requirements so this is not ideal
we actually are looking into all kinds of ways of predicting
just the sparse structure(スパース・ストラクチャー) of the road
maybe point by point or in some other fashion that is that doesn't require expensive post processing
but this basically is how you achieve a very nice vector space
〇インド出身のアショクが登壇
最適化問題を解く

hi everyone my name is ashok i lead the planning and controls auto labeling and simulation teams
the visual networks take dense video data and then compress it down into a 3D vector space
the role of the planner is to consume this vector space and get the car to the destination while maximizing the safety comfort and the efficiency of the car
even back in 2019 our planner was pretty capable driver
it was able to stay in the lanes make lane changes as necessary
and take exits of the highway
but cdc(市街地) driving is much more complicated
there are structured lane lines and vehicles do much more free from driving
then the car has to respond to all of curtains and crossing vehicles and pedestrians doing funny things
〇プランニングにおける問題点

what is the key problem in planning
1,number one the action space is very non-convex(非凸型) and
→局所最適に陥ってしまうケースが数多くあるということ
2,number two it is high dimensional
what I mean by non-convex is there can be multiple possible solutions that can be independently good but getting a globally consistent solution is pretty tricky
so there can be pockets of local minima that the planning can get stucked into
and secondly the high dimensionality comes because the car needs to plan for the next 10 to 15 seconds
and needs to produce the position velocities and acceleration or this entire window
there are many parameters to be produced at runtime
discrete search(離散検索、個別探索) methods are really great at solving non-convex problems
because they are discrete they don't get stuck in local minima(局所最小、局所最適、部分最適)
whereas continuous function optimization(連続最適化) can easily get stuck in local minima and
produce poor solutions that are not great
on the other hand for high dimensional problems
a discrete search sucks
because it does not use any graded information(グレーディド・インフォ) so literally has to go and explore each point to know how good it is
whereas continuous optimization use gradient-based methods(確率勾配法) to very quickly go to a good solution
〇ハイブリッドプランニングによる、局所最適の回避
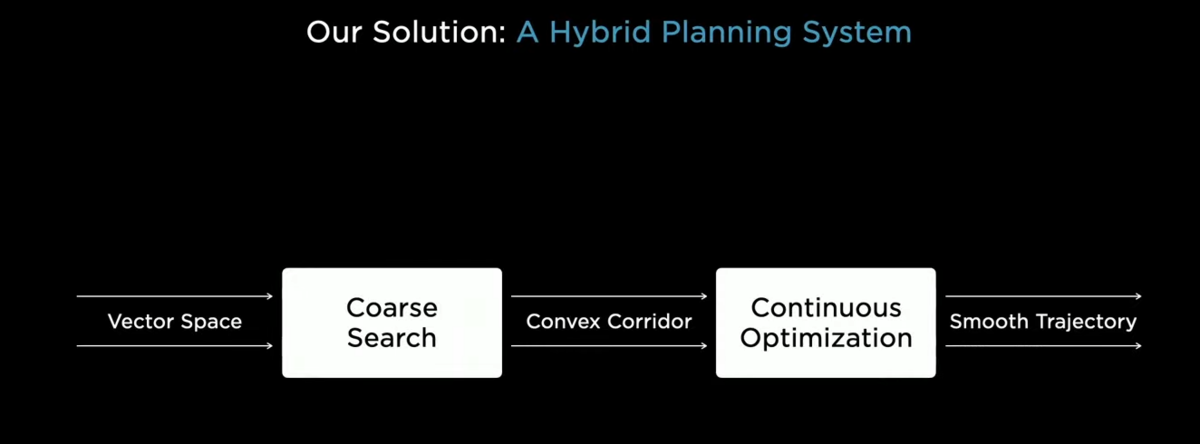
our solution to this problem is to break it down hierarchically
first use a coarse search method(コアース・サーチ) to crunch down(踏みつける、かみ砕く) the non-convexity and come up with a convex corridor
→コンベックスな問題に置き換える
and then use continuous optimization techniques to make the final smooth trajectory
→のちに連続的最適化
〇多くのプランニングを走らせる
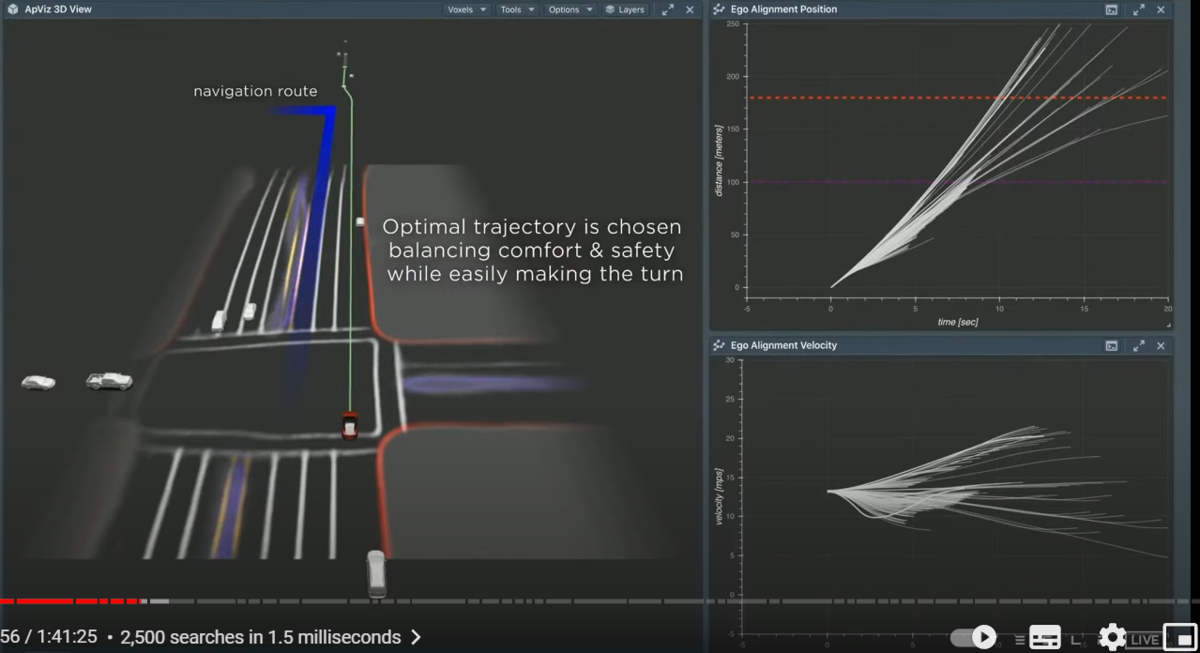
let's see an example of how the search operates
so here we're trying to do a lane change
in this case the car needs to do two back-to-back(連続) lane changes to make the left turn up ahead
for this the car searches over different maneuvers
the first one is a lane change that's close by
but the car breaks pretty harshly so it's pretty uncomfortable
the next maneuver tried is the lane change
it speeds up
goes in front of the other cars and do the lane change bit late
but now it risks missing the left turn
we do thousands of such searches in a very short time span
because these are all physics-based models these futures are very easy to simulate
and in the end we have a set of candidates and we finally choose one based on the optimality conditions of safety comfort and easily making the turn
so now the car has chosen this path
and you can see that as the car executes this trajectory
it matches what we had planned
the cyan(水色) plot on the right side is the actual velocity of the car
and the white line be underneath was a plan
so we are able to plan for 10 seconds here and able to match that when you see in hindsight(後知恵、後付け、後から)
so this is a well-made plan
〇自分以外の物体のプランニング

when driving alongside other agents it's important to not just plan for ourselves but instead we have to plan for everyone jointly
and optimize for the overall scenes traffic flow
in order to do this what we do is we literally run the autopilot planner on every single relevant object in the scene
(関連するすべてのオブジェクトにオートパイロット・プラナーを走らせる)
〇道を譲りあうケース

here's an example of why that's necessary
this is an auto corridor i'll let you watch the video for a second
there was autopilot driving an auto corridor going around parked cars cones and poles
here there's a 3D view of the same thing
the oncoming car arrives now and autopilot slows down a little bit
but then realizes that we cannot yield to them because we don't have any space to our side but the other car can yield to us instead
so instead of just blindly breaking here
they can pull over and should yield to us because we cannot yield to them
and assertively(自信を持って) makes progress
a second oncoming car arrives now this vehicle has higher velocity
we literally run the autopilot planner for the other object
so in this case we run the panel for them that object's plan
now goes around their parked cars
and then after they pass the parked cars goes back to the right side of the road for them
since we don't know what's in the mind of the driver
we actually have multiple possible futures for this car
one future is shown in red the other one is shown in green
and the green one is a plan that yields to us
but since this object's velocity and acceleration are pretty high
we don't think that this person is going to yield to us
and they are actually going to go around these parked cars
so autopilot decides that okay i have space here
this person's definitely gonna come so i'm gonna pull over
so as autopilot is pulling over we notice that
the car has chosen to yield to us
based on their yaw rate and their acceleration
and autopilot immediately changes his mind
and continues to make progress
this is why we need to plan for everyone
because otherwise we wouldn't know that this person is going to go around the other parked cars
and come back to their side
if we didn't do this autopilot would be too timid(臆病)
and would not be a practical self-driving car
〇損失関数の最小化


so now we saw how the search and planning for other people set up a convex valley
finally we do a continuous optimization to produce the final trajectory
that the planning needs to take
the gray width area is the convex corridor(コンベクス・コリドー)
and we initialize the spline in heading and acceleration
parameterized or the arc length of the plan
and you can see that continuously the compromisation makes fine-grained changes to reduce all of its costs
some of the costs are distance from obstacles traversal time and comfort
for comfort you can see that the lateral acceleration plots on the right have nice trapezoidal shapes
on the right side the green plot that's a nice trapezoidal(台形の) shape
and if you record on a human trajectory
this is pretty much how it looked like
the lateral(側面、側部) jerk(躍度、加加速度、単位時間あたりの加速度の変化率) is also minimized
so in summary we do a search for both us and everyone else in the scene
we set up a convex corridor and then optimize for a smooth path
together these can do some really neat things like shown above
〇複雑なケース

but driving looks a bit different in other places like where i grew up from
it's very much more unstructured cars and pedestrians cutting each other harsh braking honking it's a crazy world
we can try to scale up these methods but it's going to be really difficult to efficiently solve this at runtime(運転しているその瞬間ごとに)
instead what we want to do is using learning based methods
and i want to show why this is true
so we're going to go from this complicated problem to a much simpler toy parking problem
but still illustrates the core of the issue
here this is a parking lot, the ego car is in blue and needs to park in the green parking spot here
so it needs to go around the curbs the parked cars and the cones shown in orange here
there's a simple baseline it's A-star
A-star is the standard algorithm that uses a ladder space search(ラダースペースサーチ)
and in this case the heuristic here is the Euclidean distance to the goal

you can see that it directly shoots towards the goal but very quickly gets trapped in a local minima and it backtracks(引き返す) from there
and then searches a different path to try to go around this parked car
eventually it makes progress and gets to the goal but it ends up using 400,000 nodes for making this
obviously this is a terrible heuristic
we want to do better than this
〇ブルートフォース+ガイド

so if you added a navigation route to it and has the car to follow the navigation route
while being close to the goal this is what happens
the navigation route helps immediately
but still when it encounters cones or other obstacles
it basically does that same thing as before
backtracks and then searches the whole new path
this poor search has no idea that these obstacles exist
it literally has to go there and has to check if it's in collision
and if it's in collision then back up
the navigation heuristic helped but still took 22,000 nodes
we can design more these heuristics to help the search make go faster
but it's really tedious(うんざり、退屈) and hard to design a globally optimal heuristic
even if you had a distance function from the cones that guided the search
this would only be effective for the single cone
〇モンテカルロツリー探索

what we need is a global value function(グローバル・バリュー関数)
so instead of what we want to use is neural networks to give this heuristic for us
the vision networks produces vector space and we have cars moving around in the vector space
this looks like a atari game and it's a multiplayer version
so we can use techniques such as alpha zero etc that was used to solve GO and other atari games to solve the same problem
so we're working on neural networks that can produce state and action distributions
that can then be plugged into Monte-Carlo Tree Search(モンテ・カルロ・ツリーサーチ) with various cost functions
some of the cost functions can be explicit cost functions
like distance, collisions, comfort, traversal time etc
but they can also be interventions from the actual manual driving events
we train such a network for this simple parking problem
so here again same problem
〇オーダーオブマグニチュードの改善

let's see how MCT(モンテカルロツリー) searched us
so here you notice that the plan is basically able to make progress towards the goal in one shot
to notice that this is not even using a navigation heuristic just given the scene
the plan is able to go directly towards the goal
all the other options you're seeing are possible options
it does not choose any of them just using the option that directly takes it towards the goal
the reason is that the neural network is able to absorb the global context of the scene
and then produce a value function that effectively guides it towards the global minima(全体最適)
as opposed to getting stuck in any local minima
so this only takes 288 nodes
(40万→2万→300)
and several orders of magnitude less than what was done in the A-star with the equilibrium distance heuristic
〇プラナーの設計
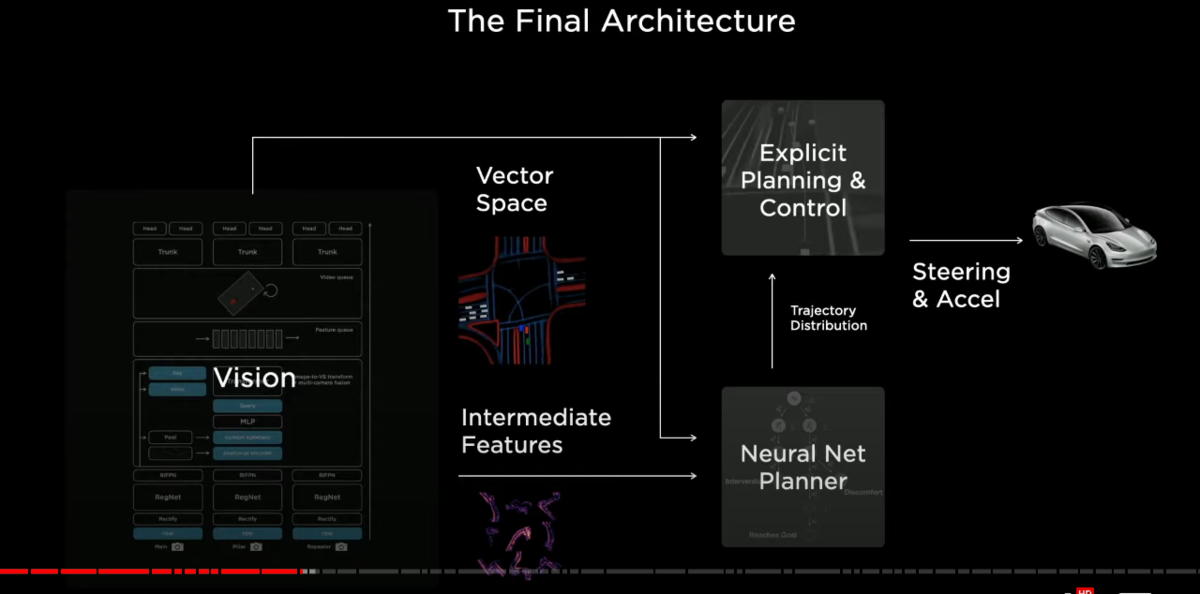
this is what a final architecture is going to look like
the vision system is going to crush down the dense video data into a vector space
it's going to be consumed by both an expressive planner and a neural network planner
in addition to this
the neural network planner can also consume intermediate features of the network
(エクスプレッシブ・プラナー、NNプラナー、インターミディエートフィーチャーズ)
together this producer trajectory distribution
and it can be optimized end to end both with explicit cost functions(顕示コスト関数) and human intervention and other data
this then goes into explicit planning function(顕示プランニング関数)
that does whatever is easy for that and produces the final steering and acceleration commands for the car
with that we need to now explain how we train these networks
and for training these networks we need large data sets
〇アンドレイが再び登壇
the story of data sets is critical
so far we've talked only about neural networks but neural networks only establish an upper bound on your performance
many of these neural networks have hundreds of millions of parameters and these hundreds of millions of parameters they have to be set correctly
if you have a bad setting of parameters it's not going to work
so neural networks are just an upper bound
you also need massive data sets to actually train the correct algorithms inside them
now in particular I mentioned we want data sets directly in the vector space
and so the question becomes how can you accumulate
because our networks have hundreds millions of parameters
how do you accumulate millions and millions of vector space examples
that are clean and diverse to train these neural networks effectively
so there's a story of data sets and how they've evolved
on the side of all of the models and developments that we've achieved
when i joined roughly four years ago we were working with a third party to obtain a lot of our data sets
unfortunately we found quickly that working with a third party to get data sets for something this critical was just not going to cut it
the latency of working with a third party was extremely high and honestly the quality was not amazing and so in the spirit of full vertical integration at tesla
we brought all of the labeling in-house and
over time we've grown more than one thousand person data labeling org
that is full of professional labelers who are working very closely with the engineers
so actually they're here in the us and co-located with the engineers here in the area as well
and so we work very closely with them and we also build all of the infrastructure ourselves for them from scratch
so we have a team we are going to meet later today that develops and maintains all of this infrastructure for data labeling
for example i'm showing some of the screenshots of some of the latency throughput and quality statistics that we maintain about all of the labeling workflows
and the individual people involved and all the tasks and how the numbers of labels are growing over time
we found this to be quite critical and we're very proud of this
〇数年前のラベリング
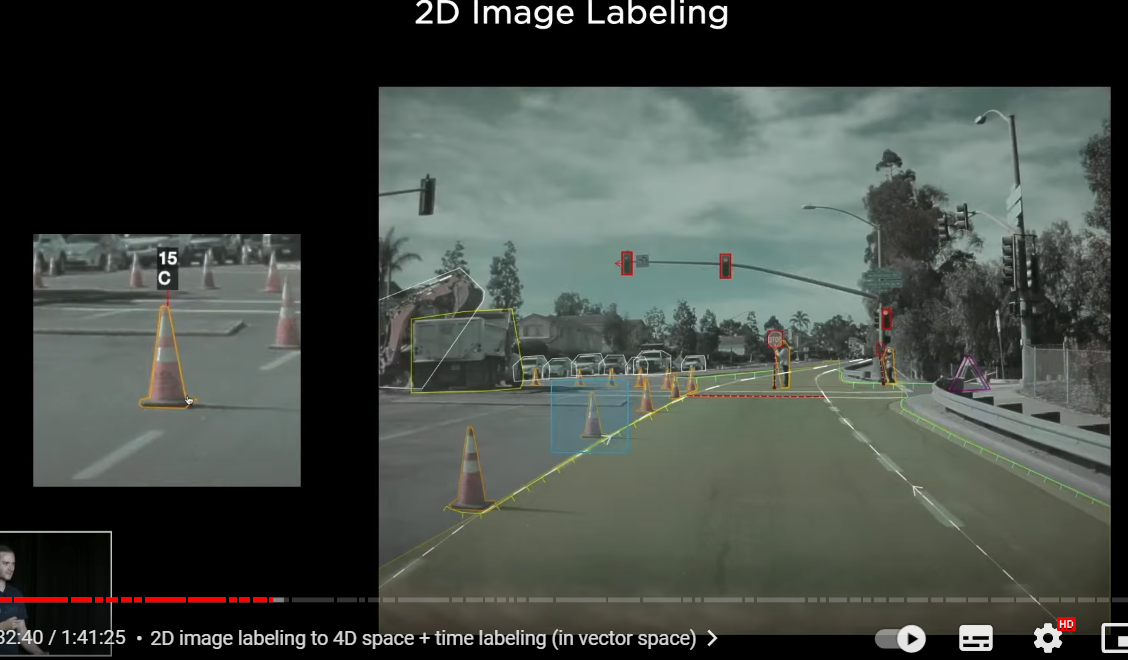
in the beginning roughly three or four years ago most of our labeling was in image space(2D labeling)
and this takes quite time to annotate(注釈をつける、ラベリングする) an image like this
and this is what it looked like where we are drawing polygons and polylines
on top of these single individual images
as we need millions of vector space labels
this method is not going to cut it
〇4Dラベリング
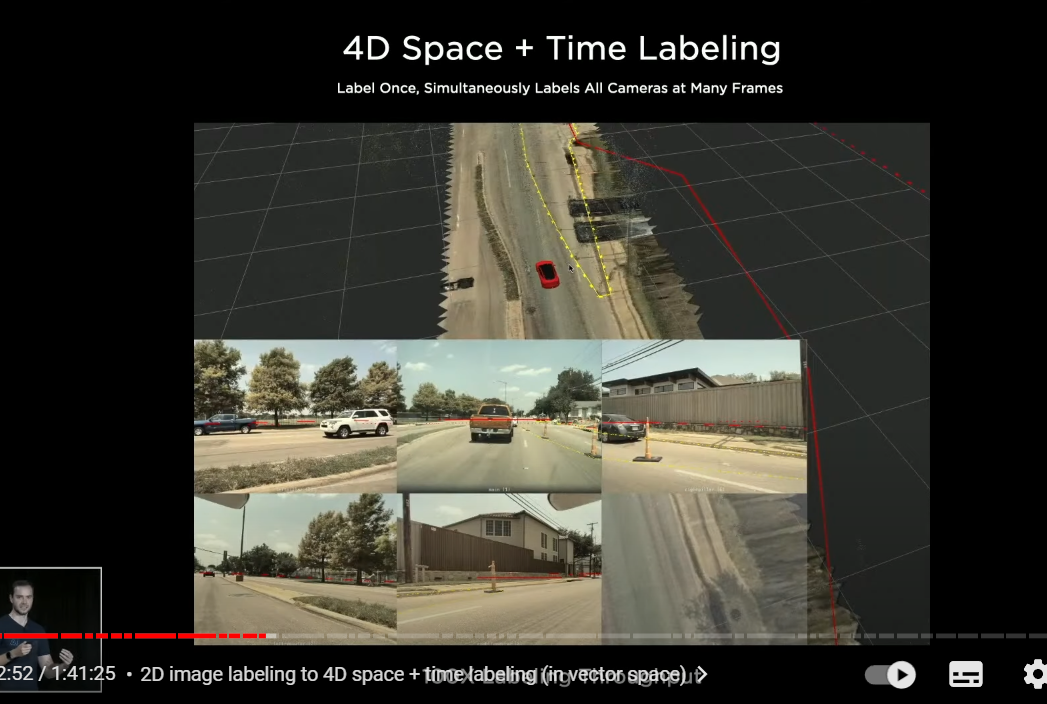
quickly we graduated to three-dimensional or four-dimensional labeling
where we directly label in vector space(多変数空間) not in individual images
so here is a clip and you see a very small reconstruction of the ground plane on which the car drove
and a little bit of the point cloud here that was reconstructed
and what you're seeing here is that the labeler is changing the labels directly in vector space
and then we are reprojecting those changes into camera images
(カメライメージへはあくまでプロジェクションしてるだけ。ラベリングはベクタースペースで行われる)
so we're labeling directly in vector space and this gave us a massive increase in throughput
because if it is labeled once in 3D and then you get to reproject
but even this was actually not going to cut it
because people and computers have different pros and cons
so people are extremely good at things like semantics but computers are very good at geometry reconstruction triangulation tracking
and for us it's much more becoming a story of how do humans and computers collaborate to actually create these vector space data sets
and so we're going to now talk about auto labeling which is the infrastructure we've developed for labeling these clips at scale
〇インド出身のアショクが再び登壇
こういうふうにラベリングしたいんだが。

even though we have lots of human labelers
the amount of training data needed for training the network significantly outnumbers them
we invested in a massive auto labeling pipeline
here's an example of how we label a single clip
a clip is entity that has dense sensor data
like videos,IMU data,GPS automatically etc
this can be 45 second to a minute long
these can be uploaded by our own engineering cars or from customer cars
we collect these clips and then send them to our servers
where we run a lot of neural networks offline to produce intermediate results
like segmentation masks depth point matching etc
this then goes to a lot of robotics and AI algorithms to produce a final set of labels
that can be used to train the networks
〇NeRFの利用
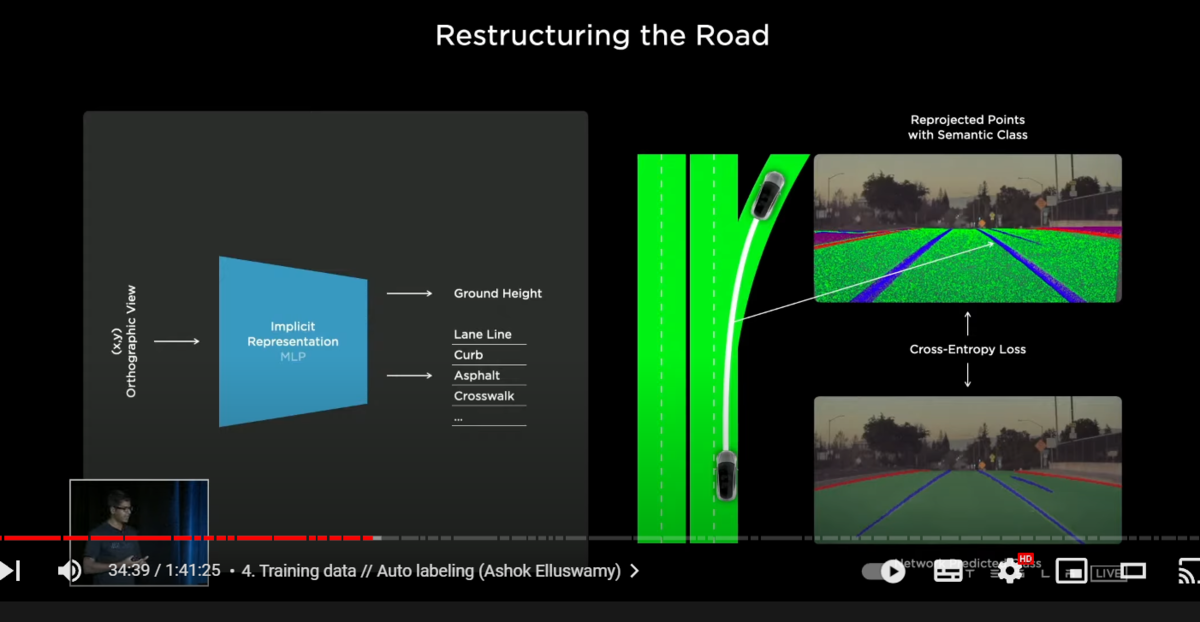
one of the first tasks we want to label is the road surface
typically we can use splines or meshes to represent the road surface
but because of the topology restrictions
those are not differentiable and not amenable(従順) to producing this
so what we do instead from last year is in the style of neural radiance fields work (NeRF:ニューラルネットワークによる三次元空間表現手法)
we use an implicit representation to represent the road surface
here we are querying xy points on the ground
and asking for the network to predict the height of the ground surface
along with various semantics(セマンティクス:個々の部分の意味) such as curves lane boundaries road surface rival space etc
given a single xy we get a z together these make a 3D point
and they can be re-projected into all the camera views
so we make millions of such queries and get lots of points
these points are re-projected into all the camera views
on the top right here, we are showing one such camera image with all these points re-projected
now we can compare this re-projected point with the image space prediction of the segmentations
and jointly optimizing this all the camera views across space and time
and produces an excellent reconstruction
〇ベクトル空間上で、再構成されたロードをプロジェクション

here's an example of how that looks like
so here this is an optimized road surface that is reproduction to the eight cameras that the car has
and across all of time
and you can see how it's consistent across both space and time
〇運転しながらベクトル空間を生成している

so a single car driving through some location can sweep out some patch around the trajectory using this technique
but we don't have to stop there
so here we collected different clips from different cars at the same location
and each of fleet sweeps out some part of the road
〇生成されたベクトル空間を相互に組み合わせる
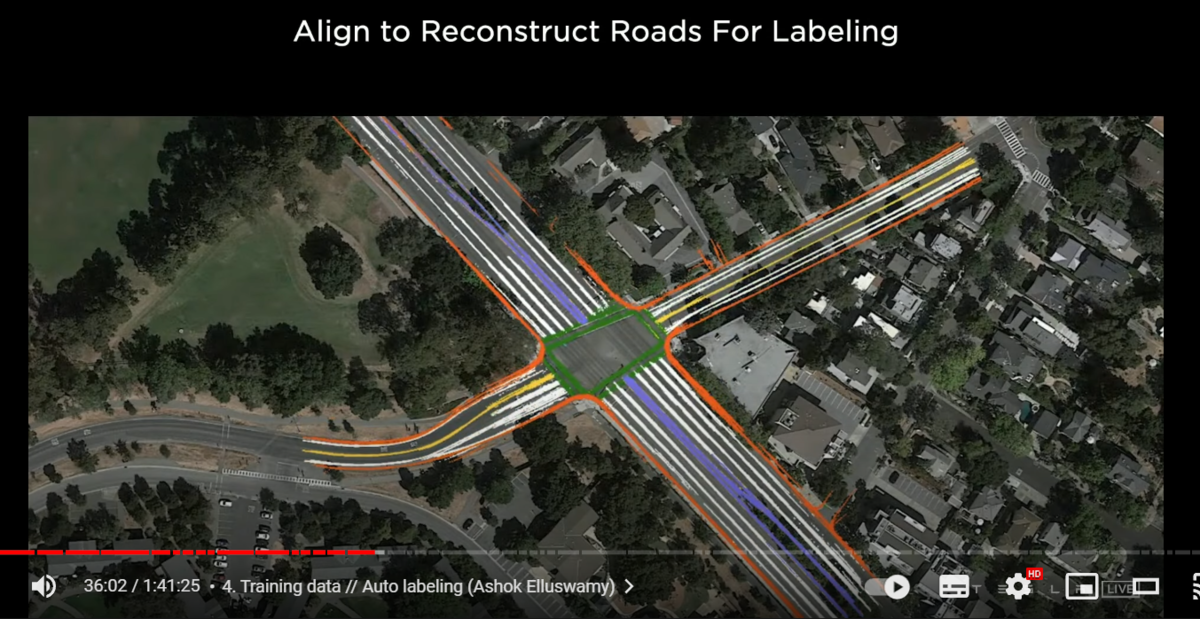
now we can bring them all together into a single giant optimization
so here these 16 different trips are organized
using various features such as road edges lane lines
all of them should agree with each other
and also agree with all of their image space observations
together this produces an effective way to label the road surface
not just where the car drove but also in other locations that it hasn't driven
the point of this is not to build HD-maps or anything like that
it's only to label the clips through these intersections
so we don't have to maintain them forever
as long as the labels are consistent with the videos that they were collected
then humans can come on top of this
clean up any noise or add additional metadata to make it even richer
〇ポイントクラウド

we don't have to stop at just the road surface
we can also arbitrarily(任意に) reconstruct 3D static obstacles
here this is a reconstructed 3D point cloud from our cameras
the main innovation here is the density of the point cloud
typically these points require texture to form associations from one frame to the next frame
but here we are able to produce these points even on textured surfaces
like the road surface or walls
and this is really useful to annotate(注釈をつけて、ラベリングすること) arbitrary obstacles
that we can see on the scene in the world
〇利点その1 後知恵

one more cool advantage of doing all of this on the servers offline is that
we have the benefit of hindsight(後知恵)
this is a super useful hack
because say in the car then the network needs to produce the velocity
it just has to use the historical information and guess what the velocity is
but here we can look at both the history but also the future
we can cheat and get the correct answer of the kinematics like velocity acceleration etc
〇利点その2 パーシステンシー

one more advantage is that we have different tracks
but we can switch them together even through occlusions
because we know the future
we have future tracks
we can match them and then associate them
here you can see the pedestrians on the other side of the road are persisted
even through multiple occlusions by these cars
this is really important for the planner
because the planner needs to know if it saw someone it still needs to account for them even they are occluded
so this is a massive advantage
〇ベクトル空間の生成に成功

combining everything together
we can produce these amazing data sets
that annotate all of the road texture all the static objects and all the moving objects even through occlusions
producing excellent kinematic labels all you can see how the cars turn smoothly
produce really smooth labels all the pedestrians are consistently tracked
the parked cars obviously zero velocity so we can know that cars are parked
so this is huge for us
this is one more example of the same thing you can see how everything is consistent
we want to produce a million labeled clips of such and train our multi-cam video networks(マルチカム・ビデオ・ネットワーク) with such a large data set
and want to crush this problem
we want to get the same view that's consistent that you're seeing in the car
〇レアケースでのドロップ

we started our first exploration of this with the Remove The Radar project
we removed it in a short time span like within three months
in the early days of the network
we noticed for example in lower security conditions the network can suffer understandably
because obviously this truck just dumped a bunch of snow on us and it's really hard to see
but we should still remember that this car was in front of us
but our networks early on did not do this because of the lack of data in such conditions
〇フリートからデータ収集


so what we did was that we asked the fleet to produce lots of similar clips
and the fleet responded it
it produces lots of video clips where shit's falling out of other vehicles
and we've sent this through auto leveling pipeline
that was able to label 10k clips within a week(1週間で1万ビデオクリップのラベリング)
this would have taken several months with humans labeling
so we did this for 200 of different conditions
and we were able to very quickly create large data sets
and that's how we were able to remove radar
〇もうドロップしない。レーダーもいらない。

so once we train the networks with this data
you can see that it's totally working and keeps the memory that this object was there
〇ベクトル空間からシミュレーションへ


finally we wanted to get a cyber truck into a data set for remove the radar
can you all guess where we got this clip from
it's rendered it's our simulation
it was hard for me to tell initially and it looks very pretty
in addition to auto labeling
we also invest heavily in using simulation for labeling our data
(シミュレーションとオート・ラベリングの関係)
so this is the same scene as seen before but from a different camera angle
so a few things that i wanted to point out
for example the ground surface it's not a plane asphalt there are lots of cars and cracks and tower seams there's some patchwork done
on top of it vehicles move realistically
the truck is articulated even goes over the curb and makes a wide turn
the other cars behave smartly they avoid collisions they go around cars
and also brake and accelerate smoothly
Autopilot is driving the car with the logo on the top and it's making unprotected left turn
〇シミュレーション上ではすべてが完璧にラベリングされている

since it's a simulation, it starts from the vector space so it has perfect labels
here we show a few of the labels that we produce
these are vehicle cuboids with kinematics
depth surface normals segmentation but
アンドレア・カパーシー may name a new task that he wants next week
and we can very quickly produce it
because we already have the vector space and we can write the code to produce these labels quickly
〇シミュレーションが有効となるケース

so when does simulation help
- データの入手が難しいケース
number one it helps when the data is difficult to source(手に入れる) as large as our fleet is
(テスラほどのオートパイロット搭載車両数を持ってしても)
it can be hard to get some crazy scenes like this couple
they run with their dog running on the highway while there are other high-speed cars around
this is a rare scene but still can happen
and autopilot still needs to handle it
- ラベリングに膨大な作業が必要な時
it helps when data is difficult to label
there are hundreds of pedestrians crossing the road
this could be a manitoban downtown people crossing the road
it's going to take several hours for humans to label this clip
and even for automatic labeling algorithms
this is really hard to get the association right
and it can produce bad velocities
but in simulation this is trivial
because you already have the objects
you just have to spit out the cuboids and the velocities
- クローズド・ループにおける適正行動を導入したいとき
finally it helps when we introduce closed loop behavior
where are the cars and where it needs to be
in a determining situation or the data depends on the actions
this is the only way to get it reliably
all this is great
1
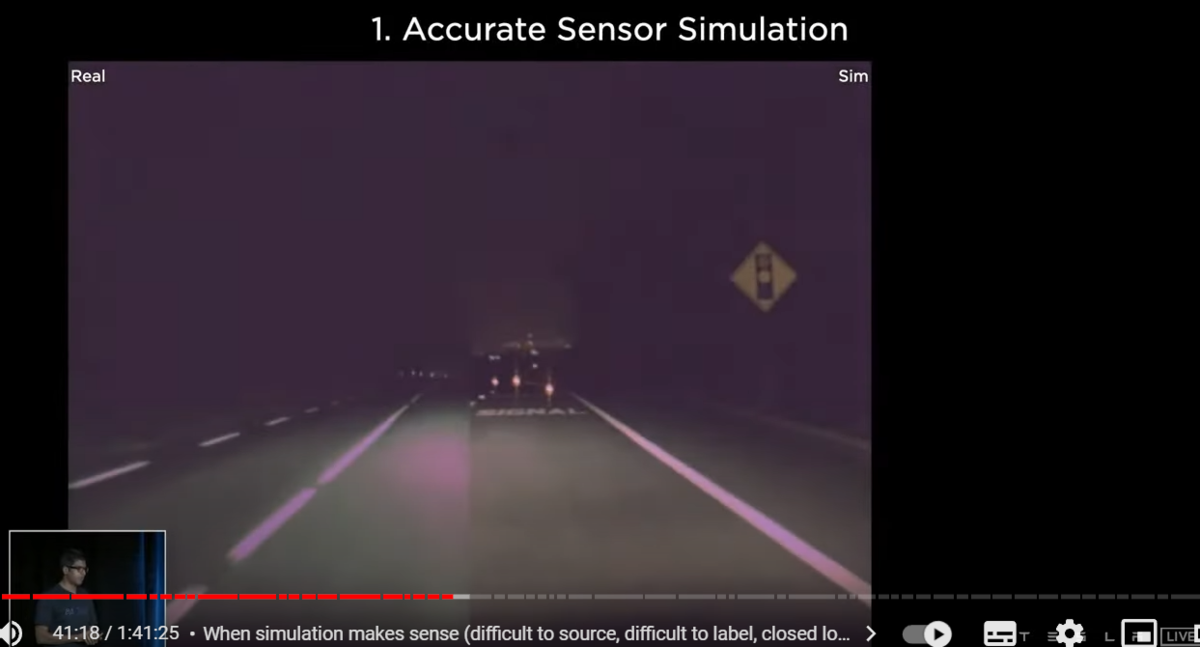

what's needed to make this happen
number one accurate sensor simulation again
the point of the simulation is not to produce pretty pictures
it needs to produce what the camera in the car would see
and what other sensors would see
here we are stepping through different exposure settings of the real camera on the left side
and the simulation on the right side
we're able to match what the real cameras do
in order to do this we had to model a lot of the properties of the camera
in our sensor simulation starting from sensor noise motion blur optical distortions even headlight transmissions even like diffraction patterns of the wind shield etc
we don't use this just for the autopilot software
we also use it to make hardware decisions such as
lens design
camera design
sensor placement or even headlight transmission properties
2

second we need to render the visuals in a realistic manner
you cannot have what in the game industry called jaggies
these are aliasing(エイリアシング) artifacts that are a dead giveaway
this is simulation we don't want them
so we go through a lot of paints to produce a nice special temporal anti-aliasing
we also are working on neural rendering techniques(ニューラル・レンダリング) to make this even more realistic
in addition we also used Ray-tracing to produce realistic lighting and global illumination
3

we obviously need more than four or five cars
because the network will easily overfit(過学習、過剰最適化)
because it knows the sizes
so we need to have realistic assets like the moves on the road
we have thousands of assets in our library
and they can wear different shirts and actually can move realistically
we also have a lot of different locations mapped and created environments
we are actually 2000 miles of road built and this is almost the length of the roadway from the east coast to the west coast of the united states
in addition we have built efficient tooling to build several miles more on a single day on a single artist
but this is just tip of the iceberg
4

actually as opposed to artists making these simulation scenarios
most of the data that we use to train is created procedurally using algorithms
these are all procedurally created roads with lots of parameters
such as curvature various trees cones poles cars with different velocities
and the interaction produce an endless stream of data for the network
but a lot of this data can be boring because the network may already get it correct
what we do is we also use ML based techniques to put up
for the network to see where it's failing at and to create more data around the failure points of the network
we try to make the network performance better in closed loop
5

so in simulation, we want to recreate any failures that happens to the autopilot
on the left side you're seeing a real clip that was collected from a car
it then goes through our auto labeling pipeline to produce a 3D reconstruction of the scene
along with all the moving objects combined with the original visual information
we recreate the same scene synthetically and create a simulation scenario entirely out of it
and then when we replay autopilot on it
autopilot can do entirely new things and
we can form new worlds new outcomes from the original failure
this is amazing because we don't want autopilot to fail in actual fleet
when it fails we want to capture it and keep it to that bar

we can also use neural rendering techniques to make it look even more realistic
we take the original video clip
we create a synthetic simulation from it and then apply neural rendering techniques on top of it
this one is very realistic and looks like it was captured by the actual cameras
i'm very excited for what simulation can achieve
but this is not all because networks trained in the car already used simulation data
we used 300million images(3億枚) with almost half a billion labels(5億ラベル)
and we want to crush down all the tasks that are going to come up for the next several months
with that I invite ミラン to explain how we scale these operations and really build a label factory and spit out millions of labels
