AIデー向けお勉強シリーズ③:ジェームス・ドウマさんその2
(Ep. 258)
テスラのAI担当であるアンドレア・カパーシーが2020年2月に、機械学習エンジニア向けのカンファレンス Scaled ML で行った講演の内容をもとに、ドウマさんが、テスラFSDの最近のイノベーションの一つであるBEVについて語ってくださっています。
この動画の視聴目的はBEVのアーケティクチャーの把握と、FSDへの影響を把握することです
BEVの設計自体は他の企業でも行えるでしょうが、使い物になるまでのプロセスには大きなチャレンジが待ち受けています。
バックボーン

BEVにデータが供給されるまでのアーキテクチャー
フュージョンの様子
スーペース・ディテクション

BEVを経由した場合のアウトプットデータ

個別のトピックは以下です
・機械学習エキスパート向けのリクルーティング講演
・バックボーン(個々のカメラネット)(図)
・個々のピクセルの関連性に基づいて処理
・演算のアウトプットを、モニター上の各カメラ画像に重ねて出力する
・動体検出
・道路上のライン検出
・道路のエッジの検出
・これらは車載用のNNによる検出
・8台のカメラ
・運転用に使用されるのは主に7台のカメラ
・フロントに3台、サイドに各2台ずつ
・メイン(通常→車2台分くらいの前方)
・フィッシュアイ(180度→サイドビューとの連携用)
・ナロー(90度のテレフォトビュー→200フィートくらいの前方)
・ピラー( 側面から前方)×2
・リピーター(フェンダーについてるやつ→後方用)×2
・後ろのライセンスプレート上に、リアビューカメラ
・APの初期バージョンでは、フロントの2つのカメラしか使っていなかった
・次にピラーの統合
・次にリピーターの統合
・この頃になるとAPは自動でレーンチェンジするようになっていた
・この2年で、サイドカメラの仕事量、使用量が増大
・すべのカメラにバックボーンNNが備わっている(図)
・フロントカメラには複数のバックボーン
・最新版では、動体検出、静体検出、道路ライン、道路エッジなどのメイン機能のために、それぞれ完全に独立したバックボーンが実装されている
・AP自体は現在でも、HD2 HD2.5 搭載車上でも機能している。
・ただしFSD用のNN大きさは、AP用の20倍もあるので、HD2.5上では実行できない
・もしかしたらHD2.5の上で走らせようとおもえば、実行自体はできるかもしれない
・以前はパースペクティブ・ビュー
・現在はBEV
・両者の違い
・a map of everything の生成 (ベクトル・スペース上での)
・パースペクティブ・ビュー上で、車はどこにあるのか?という質問を実行
・パースペクティブ・ビュー上でのキューボイドで、答えを返してきていた
・BEV上で、このBEVビューの中で車はどこにあるのか?という質問を実行
・100フィートか、200フィート上から見下ろしたとして(つまり高さを捨象して)、その視点のから見て、車の周囲の状況を記述しなさい、という質問をする
・その上で、車の位置、歩行者の位置、道路上の白線、縁石などをBEV上にプロジェクションさせる(パースペクティブ・ビュー上ではなくて)
・必要に応じて人間用インターフェース画面上にも表示させる
・パーキングロットでのスマートサモンにおける周囲状況の認識の劇的な改善(図)
・駐車場での自動運転は、ある意味で道路よりも難しい
・geometry、trigonometryアプローチは使い物にならなかった
・それらは画像認識の世界では、古典的なアプローチだった
・画像上のピクセル間の距離からの情報を、三角関数的なアルゴで、実際の距離に置き換えていたが、車両の近傍以外では上手に機能しなかった
・とりわけ水平線上の対象物の認識誤差は、ヒドかった
・geometryアプローチの放棄
・BEVの導入し、NNアプローチをメインの方法に据える
・劇的な改善
・グラウンド・トゥルースとその近似画像
・NNアプローチはすべてが新しい手法
・とりあえずの結果を出す(Demo out)のであれば、geometryアプローチで先ず始めるのは、自然なことだった
・フロントガラス自動ワイパー機能の度重なる改善
・テスラ車に、もはやレインセンサーは付いていない
・ジェネラル・デザイン・フィロソフィー 1.0と2.0
・複数の画像を統合して、統合画像を生成する
・各カメラ画像は、部分的に重なっている
・隣接したカメラと、エッジなどがコンシステントでなければならない
・スティッチアップ
・最低でも画像のローテ―ションが必要(temporal moduleにおける)
・それを並べると、時間経過を確認することができる
・1秒間前に見たものと、現在のものと、1秒後に見るもの、それらの間には高い確率的な連続性を想定できる
・時系列に並べた統合画像それ自体を、相互にチェックさせることができる。
・8フレームぐらいをローテーションして、相互チェックして、ベリフィケーションして、信頼性を高めている
・(ここでの議論に限れば)バックボーンは、もはや直接アウトプットを生成していない。そのアウトプットをフュージョン・レイヤー(ベクトル空間)へ供給している
・(ただそ。従来からの「バックボーンの演算データを、直接アウトプットへ供給」ルートが完全に消滅しているわけではない。)
・それを時間的な整合性もチェックしつつ、BEVにも投影
・信頼度のさらなる向上(図)
・ここでは、図より visceral difference (直感的な違い)を把握してほしい。
・アウトプットの目的対象が持つべきコンシステンシー
・テンポラル・モジュールによる時間的統合で、動体の存在のみならず、その動く方向、速度もより正確に認識できるようになった。
・アカデミアでは、BEV的なアプローチに関する論文は数年前から少しづつ出ていた
・アカデミアで論文が出た半年後くらいに、テスラからその成果を踏まえたその機能がリリースされることはよくある。
・(BEVアーケティクチャーを設計すること自体はテスラではなくても可能である。ただ学習のためのデータを集める方法にチャレンジがある)
・テスラは新しい機能を導入したとき、それまでの機能をすぐには捨てることはない。基本的には継ぎ足しで対応している。大まかなアーキテクチャーは、ほとんど温存してる。
・新しい機能の改善が十分に進み、もはや過去の機能を搭載することが意味をなさなくなるまで、そのままにしているのだろう。
・現在でもバックボーンは直接いくつかのアウトプットを供給している。
(FSD画面上ではBEVによるものか、バックボーンによるものかは識別できないはず。)
・このようなアプローチを数多くの機能で、同時進行で採用している
・BEVは二次元なので、高さがわからない。道路が極端に傾斜していたりするケースでは認識の難易度があがる。
・これはカメラビューレベルで対処しなければならない問題
・BEVによるアウトプットは、グランド・トゥルースの完璧な近似ではないが、FSDに必要な主要な特徴をすべて備えている
・FSDにおけるBEVの活用度合いの大幅な増加
・geometryアプローチのリファインメントよりも、BEVの導入の方が性能の飛躍をもたらした
・when you get these cameras to cross-correlate against each other and cross-correlate against time
・BEVでシングル・フレームから生成されるアウトプットの精度 と
BEVでタイム・コンポ―ネントを考慮して生成されるアウトプットの精度 を比べた場合
タイム・コンポーネントの方が必須度、優先度が高いだろう
・4Dでのトレーニング
・時間も考慮したフレーム群でのトレーニングが進めば、静止画像でのトレーニングはそれよりもたやすい
・オートノミー・デー(2019年4月)時点では、テスラはBEVについては言及しなかった
・おそらく2019年中頃からBEVの採用・開発を加速させていったのだろう
・NNコミュニティでは、時間的統合は昔から大きな課題だった。
・その有効性はだれもが認識していたが、実現する方法がわからなかった。
・(BEV空間へのプロジェクションを前提とした、スティッチアップとローテションの様々なノウハウに、時間的統合におけるイノベーション・ブレークスルーが詰め込まれているのであろう)
・BEVを経由する(という目的のために各カメラ画像から特徴を抽出していく)という方法でなくても、ブルート・フォース的に、パースペクティブ・ビュー上に直接オブジェクトをアウトプットさせるという方法もありえたかもしれない。
・過去の事例:グーグルのアニメーション空間の中での、別の視点の生成の実験
・一定の成果は残したが、訓練時間、計算コストの問題で現実的に採用できるソリューションとはならなかった
・small enough and sample efficient enough でなければならない
・例えば囲碁もブルート・フォース的に問題解決することはできない
・問題をある程度限定して、答えを出す
・解決すべき問題はコンピューテショナリーにトラクタブルでなければならない。
Tesla's Latest FSD Breakthrough: BEV Explained w/ James Douma (Ep. 258)
DAVE
so this is the most recent talk that Karpathy's done that has a decent amount of detail in it
and so that's why if what you are interested in understanding what's FSD beta
how is it different from what AP was before the non-FSD version and where is it going
what have they changed then this is like a good reference for that
you looked into from Tesla's full self-driving code
did that match up with some of the stuff that karpathy was talking about in his talk
DOUMA
i'm not really looking at code so much
i'm looking at the architecture of the NNs
we sort of figured out a way to figure out what the architecture of the NNs
that they some of the NNs
the ones that aree really big in the car
it's also possible to look at the code
it's a lot harder to interpret what's going on in the code and
that's a pretty significant undertaking
whereas at least for me having looked at a bunch of these things
just looking at the shape of the NN
it's kind of a fingerprint
you look at the shape of the NN and it gives you a pretty good idea
of what they're trying to do with this NN
because different NNs are for different objectives
they have different shapes
because we've got a few different snapshots
we saw the NNs a couple of years ago
we saw them a year ago and so we can look at the evolution and get an idea about
what's working for Tesla what's not
what they're experimenting with
DAVE
in karpathy’s talk he talked about Pseudo LiDAR image depth mapping and the overall architecture of Tesla FSD
DOUMA
the Karpathy in his talk he spends about the first half of it doing a general introduction to
what Tesla is doing like their development approach
for an audience the audience for this talk is people who know a lot about machine learning and who don't know very much about Tesla
so the first half he basically explains Tesla and your audience probably knows that part so i'd skip it
and then about halfway through he starts talking
and showing some examples of internal stuff that they're working on
that is recent developments in what they're doing and in particular i wanted to talk about things
that i thought were relevant to people's experience
and helping people understand what the NNs in AP are trying to do in particular
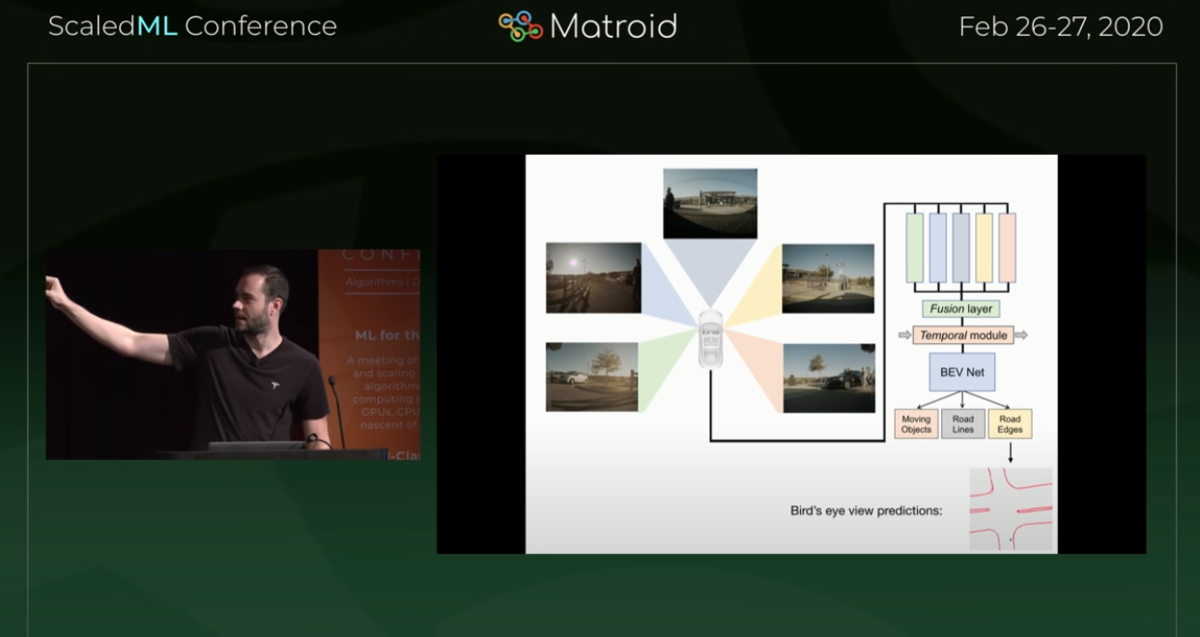
let's start with backbone here a minute
so this is a slide that shows one camera in the car conveys this
it takes an image that image gets a little bit of pre-processing
and then it feeds through the camera nets
and what karpathy here is describing as a backbone
and so this is basically a big NN
this just basically takes all these pixels
it processes them
looking at relationships between the pixels
according to the way that it's been trained
and then it squirts out a number of outputs
now he has three examples here
he shows moving objects
in this frame it's showing a box around a car
and then road lines and in this image
it's highlighting the lines in the center of the road markings
and then road edges
this output is the frame marked up showing where curve is here on the edge
these are examples of outputs
that a single backbone network on a single camera
might put out in the networks that are actually in the cars
we see anywhere from dozens to 100 of these outputs
depending on the camera obviously
the front camera side cameras they don't all look for exactly the same thing
they look for generally similar kinds of things
so that wasn't interesting
there's eight cameras
most of the driving is done with seven of the cameras
on the front of the car there are three cameras that look straight ahead
there's a fish eye which got almost 180 degree field of view
then there's what's called the main camera
which has about a 90 degree field of view it's a very recognizable field view
and they have narrow which is a telephoto view
it's looking well down the road narrow is interested in things that are a couple hundred feet down the road
main is interested in stuff that's close to the car within a couple of vehicle links
fisheye basically pulls in things from the side
if you're sitting in an intersection fisheye can also show you a certain amount to the left and to the right
so then there's four cameras on the sides of the car
there's two in the pillars that
basically look to the side and forward
then there's a set of repeater cameras which
repeater is the it's like a little turn signal indicator
that's on the front fender of the car on the side of it
so the Tesla's they have a camera that looks backwards
from each side of the car
so that's seven cameras
three to the front
and then two on each side there's another camera
which sits above the license plate and
when you back up your car it's the camera that shows you the rear view
the NNs are also capable of using that well
you don't tend to see the rear view camera used in a lot of the NNs
for instance the BEVs are they're totally dominated by the other seven cameras
DAVE
have you noticed over time Tesla incorporating more of the camera data views into their NNs
DOUMA
in early versions of AP
some years ago they were using like two of the front cameras for a really long time
and then they started incorporating the pillars
and then the repeaters came in
around the time
navigation on AP where it could start doing lane changes on its own
then it was really using all the cameras for the first time
really integrating everything
they've always done a lot of processing
on the front cameras
those are obviously really important to being able to drive the car
but the amount of work that they do on the side cameras
has increased a lot over the last 24 months or so
and so now all the cameras are basically have really big networks
and they're all doing a lot of processing but of course
there's three cameras to the front of the car
and some of the front cameras actually
have more than one backbone
they have multiple backbones that are specialized on different kinds of subsets
in this example Karpathy shows like
moving objects, road lines, and road edges
in the most recent version of networks
i saw they actually have completely different backbones for these big categories of objects
like they have a separate one
for moving objects
and a separate one for static stuff on the road and so on
DAVE
Is this more of a HD3 thing
where the old hardware just probably couldn't process fast enough all of the camera data
or did you see in the old hardware also used of all of the cameras
DOUMA
Navigation on AP was deployed before HD3 came out
but they're probably pretty close together in time
now that AP actually works fine on the older on the hardware 2.5 and hardware 2 versions of the car
but the amount of stuff that i see in FSD networks is way out of old hardware
it's 20 times too big to run on the hardware 2.5 processor
so they're definitely not running that on hardware 2.5
but the all of the functions that I saw in networks up until I started seeing FSD networks
it seemed like it was being scaled so that it could fit in hardware 2.5
so now Karpathy in this talk
he leads up to an explanation of the BEV networks and
using a NN how to develop this BEV
Tesla has recently gone to asking the car to give it a map of everything
asking a NN to generate a map of everything (Vector space they call it)
that's around the car in one field
and previously they had perspective views
if you ask to PVs "show me where the cars are"
and it would show you in the cameras field of view
like here's a car here's a car here's a car by putting boxes around those
the BEV it asks the network to take a step back
imagine you were looking at the car from 100 feet up or 200 feet up
and imagine all the area around the car
and then asking the network
tell me where the cars and the pedestrians and the road lines and the curbs are
in this view (vector space derived view)
one of the first places that this became really valuable to Tesla
and a really good test bed for this is smart summon
so they have this advanced summon feature where you can
call the car to come to you from across a parking lot
in parking lots
it's really hard to tell
where the car is supposed to drive
they're not nearly as well delineated as driving on roads are
the car, the curbs can be in all of these complicated patterns
they wanted to do was
having the NN to tell me where is it safe to drive in the parking lot
and so he's talking in this section about how they tackled that problem
originally they had tackled that problem just with geometry
which is you have a camera and it's a projection onto the world
and you can use trigonometry to say
if i see the curb at this point in the picture (2D)
it must be at this position relative to the car in the real world
and they were using that to try to estimate
where the boundaries of
where it was safe to drive was
and they were getting that works pretty well
when you're really close to the car
but there's a lot of difference
if you look out the side of the car
it's pretty easy to tell when something is five feet from the car versus ten feet from the car
but when you're looking 40 feet from the car
and you're trying to tell if something is 40 versus 45 feet away
that's a lot harder to do
to understand that distance
the geometric approach wasn't doing it for them
when they switched using a NN for this BEV approach
they suddenly started getting much better results
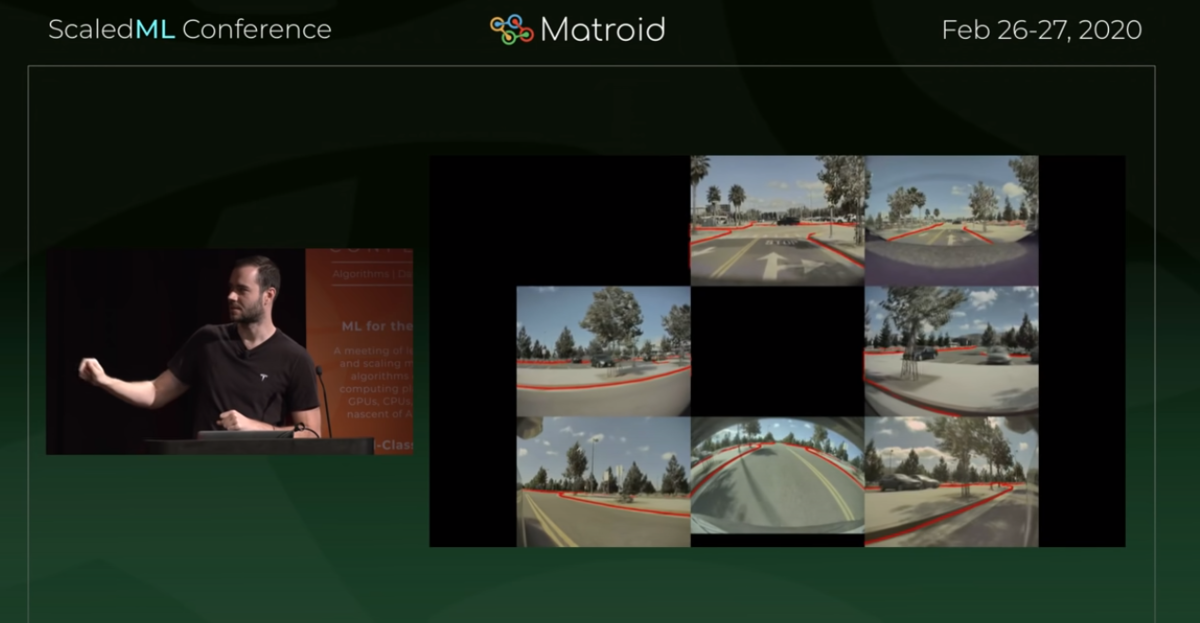
so this is what the ground truth is
in other words this is what it would actually look like on a map
and then here's what the geometric thing was showing us and it looks terrible
then here's what the BEV NN was telling us and
it's perfect it's like a really good match to the ground truth map
so you can see there what a leap forward it was
for them to step away from geometric approach to understanding the environment
having a NN take a bunch of camera views
and try to show what the world looks like
DAVE
when they were doing this a smart summon was the expectation that
a geometric approach, geometry approach would actually work
and then as they hit limitations
they're trying to explore other solutions with NNs
and so was this like on the fly adaptations
we're trying to solve this problem and
we're throwing different things at it
and then the NNs came out to be the winner
DOUMA
it's a little of both
i think their expectation is that
in the long run the NNs will win a lot of this stuff
but in the short run
NNs are new and the best way to use a NN to solve a problem can be not very obvious
and a lot of the geometric techniques are mature
they've been around for a really long time so
if they need to do something today
an approach they can take is
use a geometric approach to just get going
and then you start trying different things with the NN
to figure out what the right way to do it with a NN is
and looking at how the different NNs evolved over time
my favorites was the windshield wiper thing
because every time I saw a NN
the windshield(フロントガラス) wiper network it had radically transformed
like it wasn't this arc
where they started with this
and then they gradually moved in some direction
it went all over the place they did all kinds of things
trying to get the windshield wiper to work
that was an example of where they didn't think it was going to be that hard
when they started out and then it turned out to be surprisingly hard
and they had a whole bunch of experiments
and then eventually they found something that worked pretty well for them
and that's what they're doing now
he talks a little bit about their general design philosophy here
now when they tried to do the NN
how did they change stuff that was in the car
so now what they want to do to be able to use the NN to solve this problem
to understand the thing
you need to rotate the view at minimum
you need to be able asking the camera what would I see from above
in the field of view that you've got
then you want to put all the cameras together(fusion)
because no camera can see all the way around the car
and because the cameras really overlap a lot in their fields of view
they can act as a check on each other
and check overlapping parts
because each camera wants to see a consistent view
and its edge has to be consistent with the adjacent camera
the cameras all together end up being a good consistency check for all of them
so essentially when you try to put them all together and make it make sense
the accuracy of everything gets a lot better
so then another thing that you can do
once you've integrated all the cameras into a scene (virtual mono camera)
it should also make sense across time
there's continuity between what i saw a second ago
and what i see now
and what i will see a second from now
so another consistency check that all these things can do is
i do my top down BEV
and now i want to stitch several seconds of those together and
ask them to cross check each other and
then my accuracy goes up again
and this is what you see them doing here
he's just got an example of five cameras here
one from the front and four on the sides
and then this is what we were looking at before that was the backbone
now this time the backbone isn't making these outputs down directly
instead what the backbone is doing is
it's extracting all these features
and it's feeding them into another NN that takes the output from the individual camera networks
and it makes a unified view
the unified view combines all of them together
the next stage is the temporal one
where you look at several unified views over time
like maybe eight frames
so you take the last eight synthesized views that you have
and you ask them to all be consistent
so you have a network that that cross-checks all of those against each other
(Temporal module)
one side effect you get of time is
now you can see moving objects
if you see a car moving from frame to frame to frame
one of the things that this network can output is
not only it can just tell you there's a car there
but also it can tell you what direction it's moving and how fast it's moving
the last thing you do is you ask it to rotate the view
so that you're looking down on the car
now that you've integrated all this stuff together
both across space and across time now we rotate the view
and then in the rotated view
now we ask it all the things we were asking it before
where are the pedestrians
where are the road signs
where are the road markings
curbs and so forth
now in the rest of these examples
karpathy is using curbs in the summon as an example
for what they're doing
you would tend to see these benefits across all the different kinds of things
that they were trying to do
DAVE
this whole fusion of the different cameras into a BEV(vector space)
is this something you think that Tesla has pioneered with or
is this something that is growing more common with vision and NNs
DOUMA
Academics have been trying to do this for a little while
in the last couple of years
there has been several interesting papers out on BEV networks
my experience with looking at Tesla's networks is
i'll often look at the networks and i'll see some stuff going on
and then i'll go to the literature and i'll search for other people doing this
and i will frequently find that somebody just came out with a seminal paper on this topic
like six months or a year before Tesla did it
so they probably are innovating and
they're certainly adapting these ideas
typically what you see the research having been done on
is not exactly what Tesla wants to do
they'll be very similar
and this inspires Tesla to try something along those lines
and then they figure out how to adapt it to what they're trying to do
DAVE
you've got this fusion BEV and
then it seems Karpathy is saying that they're relying on this BEV
increasingly more over time to drive
how do you think they're managing these two views
meaning you have the old kind of forward-facing view
then you have this newer kind of BEV
when do you rely on the BEV versus when do you rely on the old forward-facing view
is there some type of switching going on or
do they have to match up or how does the logic work with that
DOUMA
AP's a product that's in development it has an arc
they do lots and lots of small revisions that they push out to the fleet
and for the most part what they do is they introduce new functionality
and then they gradually refine it over time
so we're at a point in time right now
where they still have all the outputs that they got from those backbone nets
that were on the original cameras
and they had a bunch of code that they developed
because they didn't used to have the BEV stuff
so they had some relatively mature functionality
that was using those capabilities
and they probably still have it in there
for instance you saw that
in the original backbone thing for instance
they have a moving object's output
like one of those would be cars
but identifying other vehicles that are on the road
is a big feature that these networks develop
so they had a function that was working reasonably well for quite a while
that they had developed to some level of refinement
now they bring in the BEV network approach(Vectpr space approach)
now the BEV network is answering the same question in a sense
but what you don't see is Tesla immediately throwing away the old way of doing it
and moving to the new one
because in the beginning the old one is going to be pretty competitive
because it's fairly refined and the new one is going to have some bugs
and it's going to have some accuracy limitations
as you use the new one more
it's going to get better
and once it gets good enough that the old one isn't really adding value anymore
then you can drop it
and so a lot of features end up being doing this thing
where you had the version that you were doing
before you come out with the new one
and gradually this new one gets better and better and better
and eventually "okay we don't need to waste our time on this anymore"
and then it comes out
and they're simultaneously doing this with a lot of different functions
at any given point in time
so every snapshot you see some things that are have been thrown away
some things that are brand new and being tried out
and some things are in a transition in between
that's what we're seeing right now with BEV nets
BEV nets are showing their success
at being able to do this and so they're doing more and more things with the BEV nets
they're adding more BEV nets and they're pulling more of the value out
i haven't yet seen them deprecate old stuff
but that's would be a function of when the BEV nets were doing it so well that you didn't need it anymore
there will be some things
that the BEV nets won't be good at doing
like they can't tell you how tall a bridge is that you're coming up on
there's some things that just require that vertical point of view
and there will be other things too
for instance in the BEV net
you can't tell the slope of the ground
so if you're driving around a curve and
the road is banked or counter banked
you don't see that in the BEV net
so that's something you always have to do in the camera view(2D)
we talked about the architecture here
they have
the backbones
they feed into a fusion layer
they make it sense across time
then they do the top down view, the BEV view
now they're pulling the objects out
so this is where Karpathy is showing the success of this method
in the specific case of predicting where curbs and parking lots are
this is the ground truth
so you got a map of the parking lot
which maybe you pre-mapped it or maybe you got this from google
this is what the geometry is telling them about where the curbs are
so you can see this is where the car is
it's this blue dot
and the stuff that's nearby it's not too bad
it's useful within one or two car links
you can tell what you don't want to run into
but it's not very helpful
not very good at helping you understand the shape of this intersection that you're coming to
and not very good at like what your options are for navigating it
because as you get farther away from the car
things get closer to the horizon line
the uncertainty of the positioning gets to be really large
and then this is the output of the NN(BEV=Vector space) and
while you can see that the NN is not a perfect representation of the ground truth
it's got all the important features
and this was a fairly early version of the BEV net
that they had developed in particular for summon
what i see in the FSD version of the BEV networks that i was looking at
was lots and lots of this BEV net getting used
they're using BEV nets everywhere
what i wanted to try to give you here was a sense of the visceral difference in the two
imagine this
if you're here in this car
and you're trying to decide okay i want to make a left turn
what do i need to do over the next five seconds
you look at this it's not too tough
i need to turn wide enough to miss this curb
and i want to end up going about this way
if you go over to this ( geometry ) scene and you try to answer that question
this is almost not useful
in other words the level of uncertainty that you get
just trying to predict these things from the camera views themselves
is large enough that you just can't even make sense of the shape of the network
so this is the basic what you get with that basic geometric approach
now you could refine this
you could keep working on the basic geometric approach
and you could get better at it by putting things in
but when they took the problem away from geometry and
they gave it to a BEV network and they told it
the constraints are like
whatever one camera sees has to make sense for another camera
these objects, this space needs to be continuous and make sense
and as you move through the scene it needs to be continuous and make sense
when you get these cameras to cross-correlate against each other
and cross-correlate against time
all of a sudden your accuracy gets dramatically better
and in this case you can see the differences
basically this center image might not be perfect but it's usable
they went from something that was totally unusable
which they'd worked on a long time they had summon working in parking lots for a while
before they went to the BEV nets
DAVE
so that BEV view in the middle
looks like almost exactly the same as the ground truth
how much of that is based upon using the BEV net over time
over a few seconds versus
just like let's say a standstill frame
are they able to get that type of accuracy with just a single frame
or is that because they're able to see it over a few seconds time
DOUMA
so there are two components to that question
say the car wasn't moving
you turn on the car
it's sitting in one spot
it looks out
what is it going to see at this intersection
so you haven't had any motion
it's probably not going to be as good as this but it's not going to be bad
when you are stopped at an intersection
you don't get to use the time component nearly as much of orienting yourself in the world
but it does add some value
it's going to make the network more accurate
when the car drives through a scene and it sees a curb move
from the distance into the foreground and slide past
that has to have a kind of consistency to it
in how it moves through
it shouldn't jerk
it should keep track with the motion of the car
so relying on that motion consistency does allow AP to make a bet
to be a better judge at any moment in time
where that curb is or that object actually is
but the place that really has a benefit is
when you train these things
as soon as you start training that temporal layer
your training material has to have time in it
so this is when Elon was talking about training in 4D
the 3D is including the BEV the top down look
we know where all these objects are in space
and we're testing against that
and the 4D is time
where we start stitching these frames together
that predicting the time dimension for the NN is really hard
and when it gets good at that
it's really good at the static frames
DAVE
autonomy day in 2019
did they mention BEV much at all
at that presentation because we fast forward to February of 2020
andre Karpathy’s scaled ml and
he's basically saying hey this is the big thing
we're building a lot of this stuff on
but on autonomy day did they have that type of conviction
back then or is it something you think
in between that today
DOUMA
They didn't talk about it at autonomy day for sure
I don't think they talked about it
that the literature doesn't seem to have used this terminology
much before a couple of years ago
but so Tesla obviously had done a significant amount of internal development of this
by February of 2020
so they must have started working on it
in some capacity around mid-2019 or something
and it was around mid-2018 that this started becoming a popular topic out
in fact in 2019 you do see a bunch of papers come out so
they probably knew generally that they wanted autonomous car
NN circles you can go way back and people knew that
if you integrated time
it was going to be super valuable
they just didn't know how to do it
what's the right way to do it and
they've known for a long time that
if you integrated multiple cameras together
that was going to be really valuable
because there's a way the NNs can cross check themselves
the camera NNs and you have to bring all this stuff together
and make it make sense
it challenges all the networks to get a lot better and
once they all get a lot better
then the unified view starts to get really good
we've known for a long time that
this needed to happen
it just wasn't clear what the right way to do it
there are these brute force approaches that you can take
where it's definitely got all the inputs it needs
you just put a giant NN on it
and you just process it and you train everything against everything else
and google did some early experiments several years ago
getting a huge cloud of computers
and asking them to do this really hard thing
proved that certain things were possible but they weren't practical on that scale
because you need billions of hours of training
so to make it useful in the real world
you want to figure out what do I not need to look at
what is essential to helping the NN understand this thing
that needs to understand to do a good job of this
and what's not important
and so you gradually whittle away all the things you don't have to do
and you get a NN that's small enough and sample efficient enough
is like how much data does it take to train this function
it's got to be a reasonable number and
how much computation does it take
that's going to be reasonable
we can use a big data center
but we can't use a thousand big data centers
there are limits
it's like the trying to brute force the game of go
it seems pretty small it's a 19 by 19 board but
they're more go positions than our atoms in the universe
i forget like dozens of orders of magnitude
there are problems that don't seem very hard
but you simply can't brute force them
you have to constrain the problem a certain amount
before it starts to be tractable
that was one of the problems and it continues to be a problem
with this whole getting a computer to understand that the world is 3D
brute forcing that problem has been intractable
google did a couple of really interesting things
some guys at google brain did some really interesting things
where they just brute force
they've made a little cartoon world
they really dumbed it down
which still has spheres and cones
and they wanted to train NN
and you would show it one view of the world
and you would ask it
what would it look like from this other angle
where you would give it an arbitrary angle
and the amazing thing was they got it to work
it took a significant amount of computation and it was very brute force
but they showed that the NN will eventually figure that stuff out if the information is there
but the approach that they took
nobody tried to duplicate that in any product
because it just takes too much data
and the world has to be too simple for it to work
so where's the good middle ground
where it's computationally tractable
it's a reasonable size NN and a reasonable size amount of data and training time
but it works in the real world
it deals with all of the complexity of the of the real world
and that's been the challenge
it's just been in the last couple of years
that people have come up with techniques
where this started to produce results
that were significantly better than what we could do before
for a long time they've been able to muddle along
but why do this super complicated technique
that isn't getting you better results
and now they're doing these complicated techniques
that are getting dramatically better results
and that's one of the things you see in this slide
you can see there's a dramatic difference between
what they were getting with the geometric technique that was a dominant approach before
and what they're getting now
and once again you look at the ground truth
it's not perfect but it's a pretty good facsimile of that
and it's a dramatic improvement over what they had before