テスラ AI DAY スーパーカット
テスラのAIデーの、ニューラル・アルゴリズム及びシミュレーション部分のスーパーカットです。
ここで解説されている手法は実務でも利用されているものもあり、その点にモートがあるわけではありません。しかしそれらをすべて統合し、人間の視覚野のシミュレーションともいうべきシステムを構築してしまったこと、それを用いて大規模にトレーニングするためのデータおよび演算環境をそろえてしまっていること。
これは他社では絶対に真似できません。
テスラに唯一近いアプローチを採用している企業は、ジョージ・ホッツのC3.AI (シンボル $AI)ですが、フォーカスしている市場が異なること、データ収集においてはお話にならないことなど、自動運転に関してはテスラに大きく引き離されています。
また、とりわけLiDARを利用して3Dマップを作っているそれ以外の無数の他社のエンジニアは「とりあえずデモを出して何も知らない役員をゴマかしているけど、この技術の先に本当に自動運転が実現できる未来があるのか?」と自問していることでしょう。
その他社の役員は、自社の自動運転の「デモのためのデモ」を見て悦にいっているとともに、それを使っていかに顧客を目くらましするかを日々考えていることでしょう。
①アンドレイ:アーケティクチャー全体:ベクタースペースの生成
②アショック:オートラベリング
③アンドレイ:データ収集
④アショック:シミュレーション
の順番で話が進みます。
トピックは以下です。
〇イーロンが登壇

what we want to show today is that tesla is much more than an electric car company that we have deep AI activity in hardware on the inference level on the training level
we're arguably the leaders in real world AI as it applies to the real world those of you who have seen the full self-driving beta i can appreciate
the rate at which the tesla neural net is learning to drive this is
a particular application of AI but there's more
there are applications down the road that will make sense
i want to encourage anyone who is interested in solving real-world AI problems at either the hardware or the software level to join tesla or consider joining tesla
〇ANDREJが登壇
i lead the vision team here at tesla autopilot and i'm incredibly excited to be here to kick off this section
giving you a technical deep dive into the autopilot stack and showing you all the under the hood components that go into making the car drive by itself in the vision
component what we're trying to do is we're trying to design a neural network that processes the raw information
which in our case is the eight cameras that are positioned around the vehicle and they send those images and we need to process that in real time into the vector space
and this is a three-dimensional representation of everything you need for driving
so this is the three-dimensional positions of lines edges curbs traffic signs traffic lights cars their positions orientations depth velocities and so on
〇これをやりたいんですけどね。

here i'm showing the video of the raw inputs that come into the stack and then neural net processes that into the vector space
and you are seeing parts of that vector space rendered in the instrument cluster on the car
what i find fascinating about this is that we are effectively building a synthetic animal from the ground up
the car can be thought as an animal.
it moves around it senses the environment and acts autonomously and intelligently
we are building all the components from scratch in-house
so we are building all the mechanical components of the body the nervous system which is all the electrical components
and for our purposes the brain of the autopilot and specifically for this section the synthetic visual cortex
now the biological visual cortex actually has quite intricate(入り組んだ) structure and a number of areas that organize the information flow of the human brain
in your visual cortexes light hits the retina(網膜)
it goes through the LGN all the way to the back of your visual cortex
then goes through areas v1 v2 v4 the IT
the venture on the dorsal streams and
the information is organized in a certain layout
when we are designing the visual cortex of the car
we also want to design the neural network architecture of how the information flows in the system
〇視覚野のアナロジー
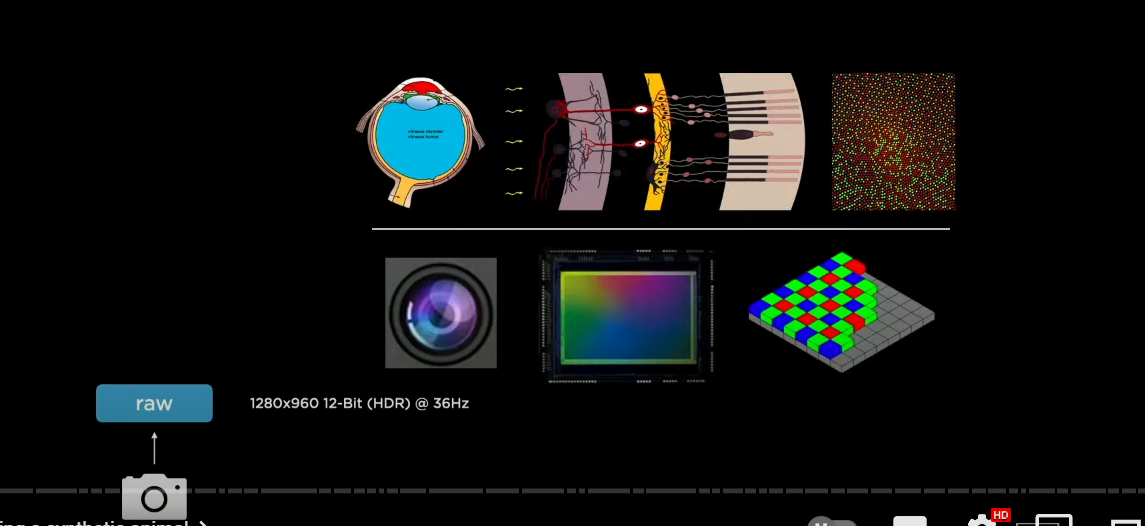
the processing starts when light hits our artificial retina and we are going to process this information with neural networks
now i'm going to roughly organize this section chronologically(年代順に)
starting off with the neural networks
what they looked like four years ago when i joined the team and how they have developed over time
four years ago the car was mostly driving in a single lane going forward on the highway
and it had to keep lane and it had to keep distance away from the car in front of us
and at that time all of processing was only on individual image level
so a single image has to be analyzed by a neural net
and make little pieces of the vector space
process that into little pieces of the vector space
so this processing took the following shape
we take 1280 by 960 input and this is 12 bit integers streaming in at roughly 36 hertz
now we're going to process that with the neural network
〇レジデュアルNN→レグネッツ
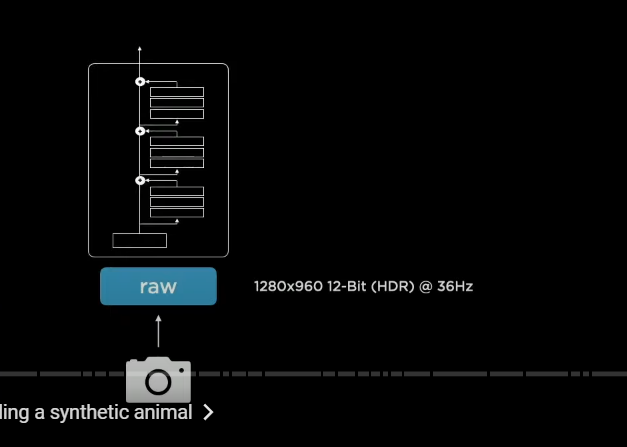
so instantiate(インスタンス化する) a feature extractor backbone
(レジデュアルNNを使った特徴抽出バックボーン)
in this case we use residual neural networks
we have a stem and a number of residual blocks connected in series
(ステムとレジデュアルブロックス)
now the specific class of resnets that we use are called regnets
regnets offer a very nice design space for neural networks
(レグネッツによるNNデザインスペース)
because they allow you to nicely trade off latency and accuracy
(レイテンシとアキュラシのトレードオフ)
〇REGNETS

now these regnets give us a number of features as an output at different resolutions in different scales
so in particular on the very bottom of this feature hierarchy
we have very high resolution information with very low channel counts
ボトム(160*120*64)→ディティール把握
and all the way at the top we have low spatial,low resolution but high channel counts
トップ(20*15*512)→概要とコンテクストを把握
so on the bottom we have a lot of neurons that are really scrutinizing the detail of the image
and on the top we have neurons that can see most of the image and have a lot of that scene context
〇BiFPN

then we like to process this with feature pyramid networks(フィーチャーピラミッドネットワーク:FPN)
in our case we like to use BiFPNs
residual NN = Regnets
feature pyramid networks = BiFPNs
and they get to multiple scales to talk to each other effectively and share a lot of information
so for example if you're a neuron all the way down in the network
you're looking at a small patch and you're not sure this is a car or not
ihelps from the top players are useful
like hey you are actually in the vanishing point of this highway
and so you can disambiguate that this is probably a car
〇検出を担当するヘッドでの、車両の検出ケース

after BiFPN and a feature fusion across scales
then we go into task specific heads(単体のヘッド)
so for example if you are doing object detection
we have a one stage yolo like object detector here
where we initialize a raster(ラスターイメージ) and there's a binary bit per position telling you whether or not there's a car
and then in addition to that if there is a car
here's a bunch of other attributes you might be interested in
so the x y with height offset or any of the other attributes like what type of a car is this and so on
so this is for the detection by itself
〇単体のヘッドとハイドラネットの違い
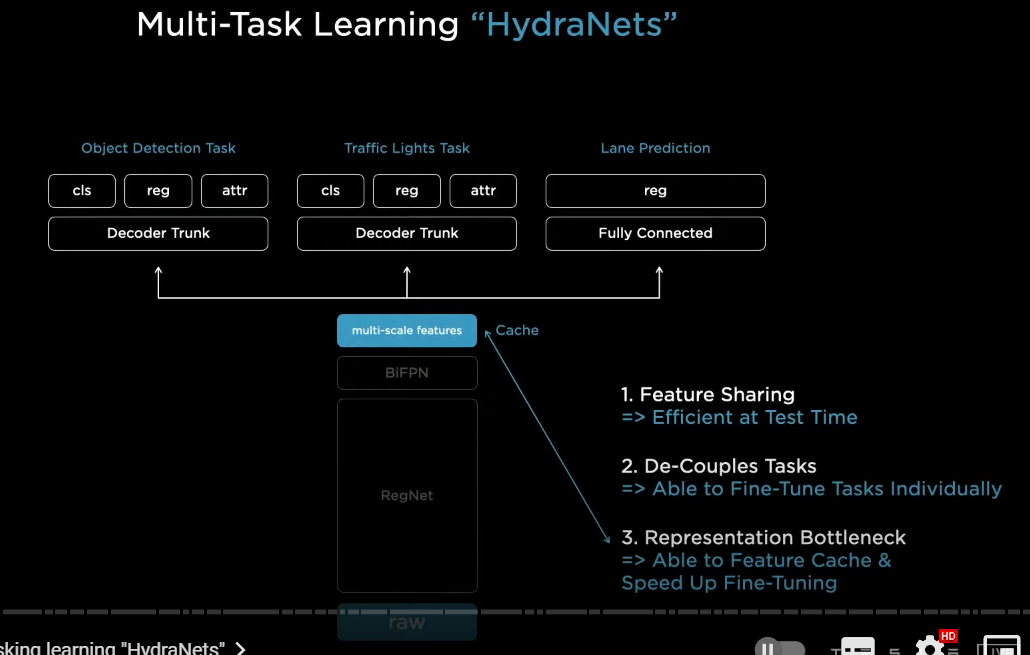
now very quickly we discovered that we don't just want to detect cars
we want to do a large number of tasks
for example we want to do traffic light recognition and detection a lane prediction and so on
quickly we converge in this kind of architectural layout
where there's a common shared backbone and then branches off into a number of heads
so we call these therefore hydranets and these are the heads of the hydra
this architectural layout has a number of benefits
以下はハイドラネットの利点
1
number one because of the feature sharing we can amortize the forward pass inference in the car at test time and so this is very efficient to run
because if we had to have a backbone for every single task that would be a lot of backbones in the car
2
number two this decouples all of the tasks so we can individually work on every one task in isolation
and for example we can upgrade any of the data sets or change some of the architecture of the head and so on
and you are not impacting any of the other tasks and so we don't have to revalidate all the other tasks which can be expensive
3
and number three because there's this bottleneck here in features
so we cache these features to disk and
when we are doing these fine tuning workflows, we only fine-tune from the cached features up and we only fine tune the heads
in terms of our training workflows
we will do an end-to-end training run
once in a while where we train everything jointly
then we cache the features at the multi-scale feature level
and then we fine-tune off of that for a while
and then end-to-end train once again and so on
〇画像上(2D)でのラベリング
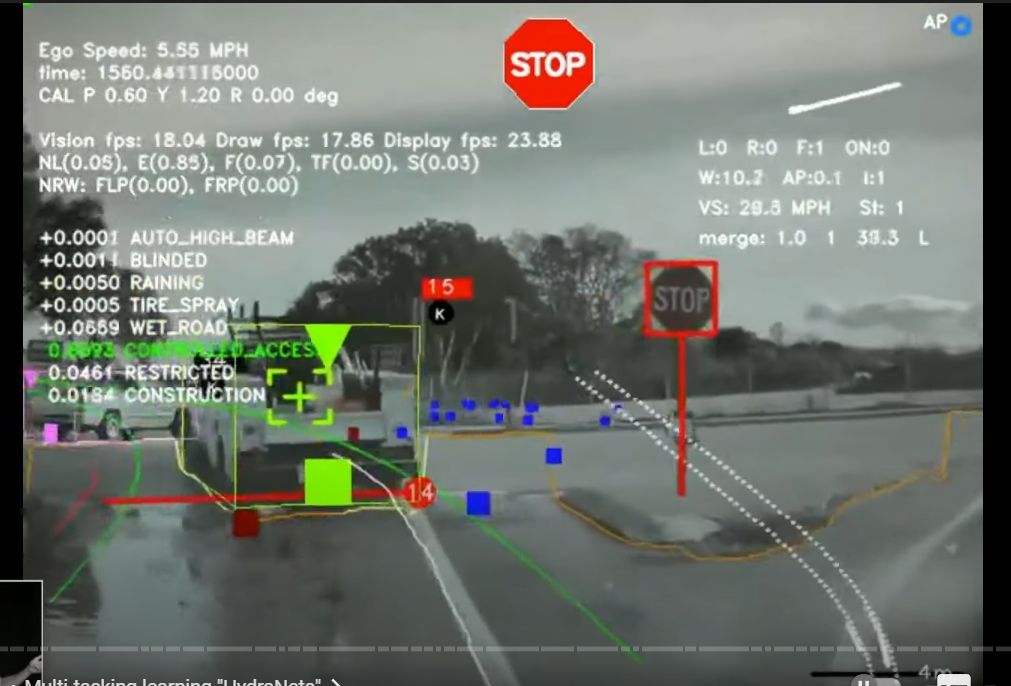
so here's predictions that we were obtaining several years ago from one of these hydro nets
again we are processing individual images and we're making a large number of predictions about these images
here you can see predictions of the stop signs the stop lines the lines the edges the cars the traffic lights the curbs whether or not the car is parked all of the static objects like trash cans cones and so on and
everything here is coming out of the Hydra net
so that was all fine and great
but as we worked towards FSD we quickly found that this is not enough
where this first started to break(ほころび始めた、破綻し始めた) was when we started to work on smart summon(スマート・サモンで)
i am showing some of the predictions of only the curb detection task
and i'm showing it for every one of the cameras
so we'd like to wind our way around the parking lot to find the person who is summoning the car
now the problem is that you can't just directly drive on image space predictions (カメラ画像により表示されている映像(2D)、その中をドライブしていくやり方ではうまくいかなかった。)
you actually need to cast them out and form a vector space around you
〇 オキュパンシートラッカー(ダメ)
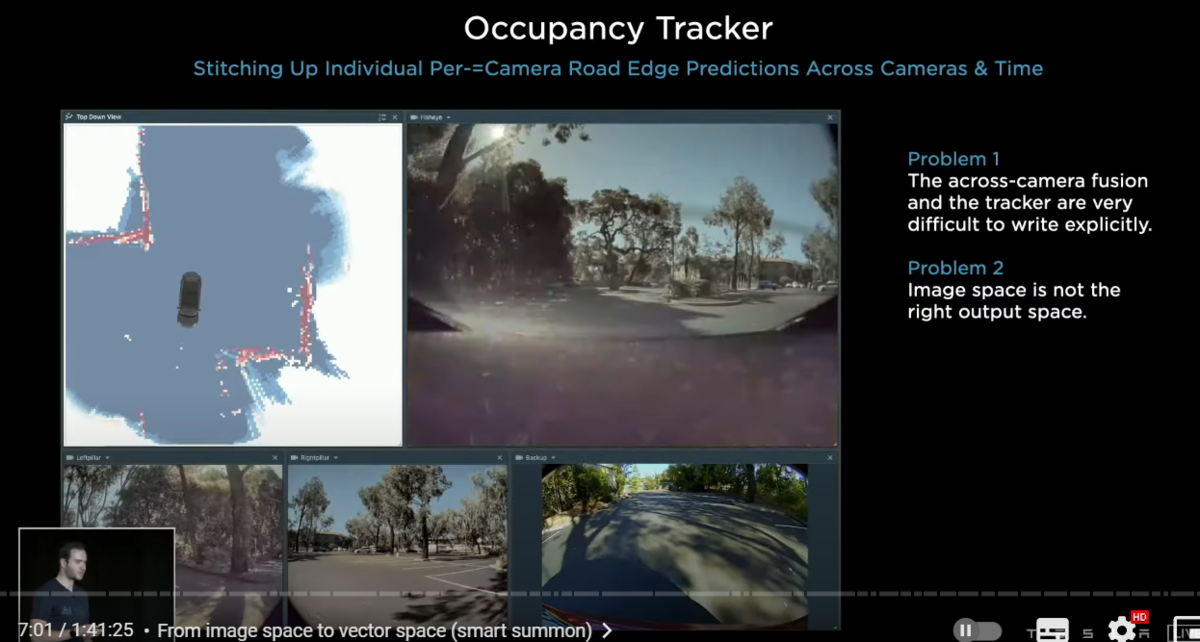
we attempted to do this using c++ and developed the occupancy tracker(オキュパンシー・トラッカー) at the time
here we see that the curb detections from the images are being stitched up across camera scenes across camera boundaries
and over time there have been two major problems with the setup
以下問題点
1
number one we very quickly discovered that tuning the occupancy tracker and all of its hyper parameters was extremely complicated
you don't want to do this explicitly by hand in c++
you want this to be inside the neural network and train that end-to-end
2
number two we very quickly discovered that the image space is not the correct output space
you don't want to make predictions in image space
you really want to make it directly in the vector space
〇2Dラベリングを、ベクタースペースに投影してみると。。。

here's a way of illustrating the issue
i'm showing on the first row the predictions of our curves
and our lines in red and blue they look great in the image
but once you cast them out into the vector space
things start to look really terrible and we are not going to be able to drive on this
you can see how the predictions are quite bad and the reason for this is because you need to have an extremely accurate depth per pixel in order to actually do this projection
(この方式だと、1ピクセル毎の超正確な深度が必要→それは無理)
and so you can imagine just how high of the bar it is
to predict that depth in these tiny every single pixel of the image so accurately
and also if there's any occluded area where you'd like to make predictions
you will not be able to predict it because it's not an image space concept
〇カメラごとに検出して、フュージョンする問題点

2
the other problems with this is also for object detection
if you are only making predictions per camera then sometimes you will encounter cases like this
where a single car actually spans five of the eight cameras(8カメラ中5カメラをスパンする車両)
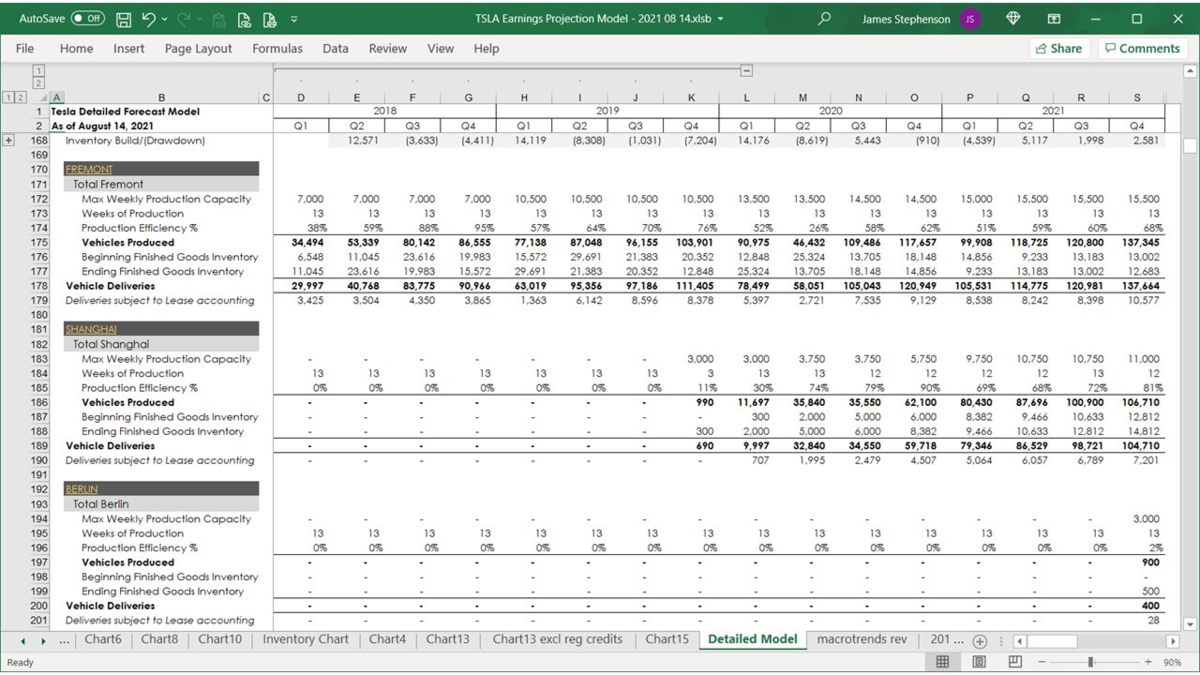
so if you are making individual predictions
then since no single camera sees all of the car and you're not going to be able to do a very good job of predicting that whole car
and it's going to be incredibly difficult to fuse these measurements
〇マルチカメラ画像をどのようにベクタースぺースに統合していったのか
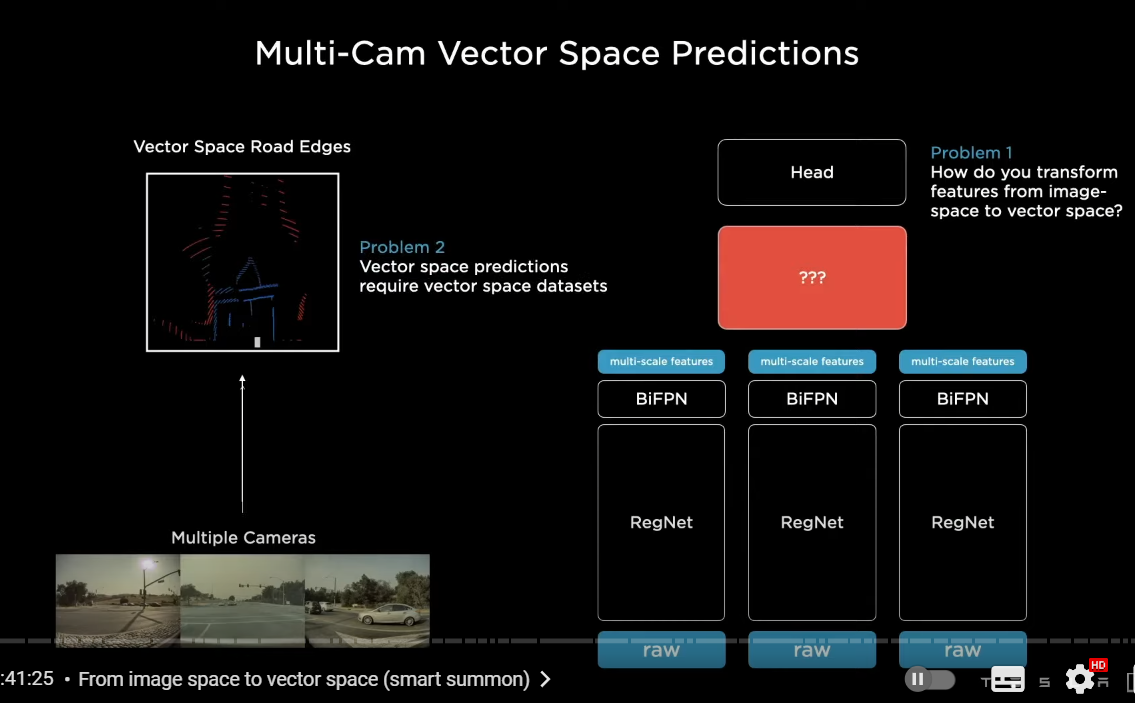
so instead we'd like to take all of the images and simultaneously feed them into a single neural net and directly output in vector space
now this is very easily said much more difficult to achieve
but roughly we want to lay out a neural net in this way
where we process every single image with a backbone and then we want to fuse them
and we want to re-represent the features
from image space features to directly vector space features
(イメージ空間フィーチャーズとベクトル空間フィーチャーズの違い)
and then go into the decoding of the head
(それを各ヘッドでディコーディング)
2-1 トランスフォーマー(今流行りの手法)
so there are two problems with this problem
number one how do you actually create the neural network components that do this transformation
you have to make it differentiable so that end-to-end training is possible
2-2 ベクトル空間向けの特徴量の抽出
number two if you want vector space predictions from your neural net
you need vector-specific based data sets
just labeling images and so on is not going to get you there
you need vector space labels
for now i want to focus on the neural network architectures
i'm going to deep dive into problem number one
〇BEVのある部分と、各カメラ画像のどの部分が対応しているのか
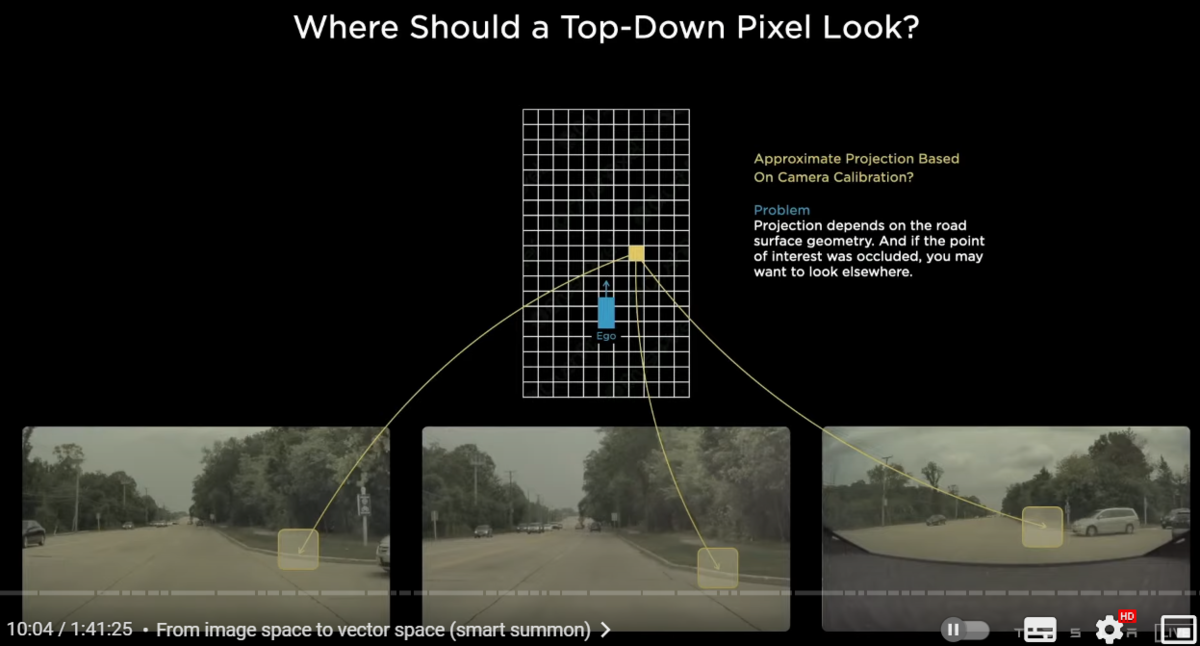
we're trying to have this bird's eye view prediction instead of image space predictions
for example let's focus on a single pixel in the output space in yellow
and this pixel is trying to decide
Am i part of a curb or not
where should the support for this kind of a prediction come from in the image space
we know how the cameras are positioned and
they're extrinsic and intrinsic so we can roughly project this point into the camera images
and the evidence for whether or not this is a curve may come from somewhere here in the images
the problem is that this projection is really hard to actually get correct
because it is a function of the road surface and the road surface could be sloping up or sloping down
also there could be other data dependent issues for example there could be inclusion due to a car
so if there's a car occluding this part of the image
then actually you may want to pay attention to a different part of the image
not the part where it projects
and because this is data dependent it's really hard to have a fixed transformation for this component
〇トランスフォーマーの使用
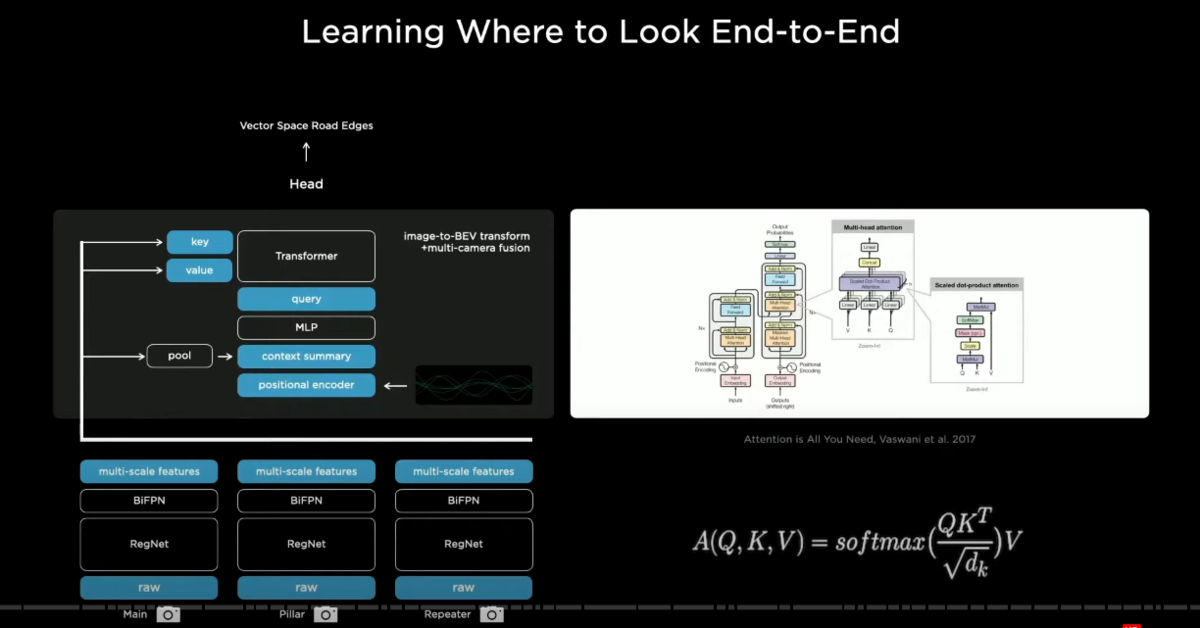
so in order to solve this issue we use a transformer(トランスフォーマー) to represent this space
this transformer uses multi-headed self-attention(マルチヘッド・セルフアテンション)
and blocks off it in this case
we can get away with even a single block doing a lot of this work effectively
what this does is you initialize a raster(ラスターイメージ) of the size of the output space
and you tile it with positional encodings(ポジショナル・エンコーディングズ)
with size and coses in the output space
and then these get encoded with an MLP into a set of query vectors(クエリ―ベクトル)
and then all of the images and their features also emit(放出する) their own keys and values
and then the queries keys and values feed into the multi-headed self-attention
what's happening is that every single image piece is broadcasting what it is a part of in its key
i'm part of a pillar in roughly this location
and i'm seeing this kind of stuff and that's in the key
then every query is along the lines of hey i'm a pixel in the output space at this position
and i'm looking for features of this type then the keys and the queries interact multiplicatively
and then the values get pulled accordingly
and so this re-represents(空間の再表象) the space
and we find this transformation to be very effective if you do all of the engineering correctly
this again is very easily said difficult to do
you need to do all of the engineering correctly
〇カメラキャリブレーション
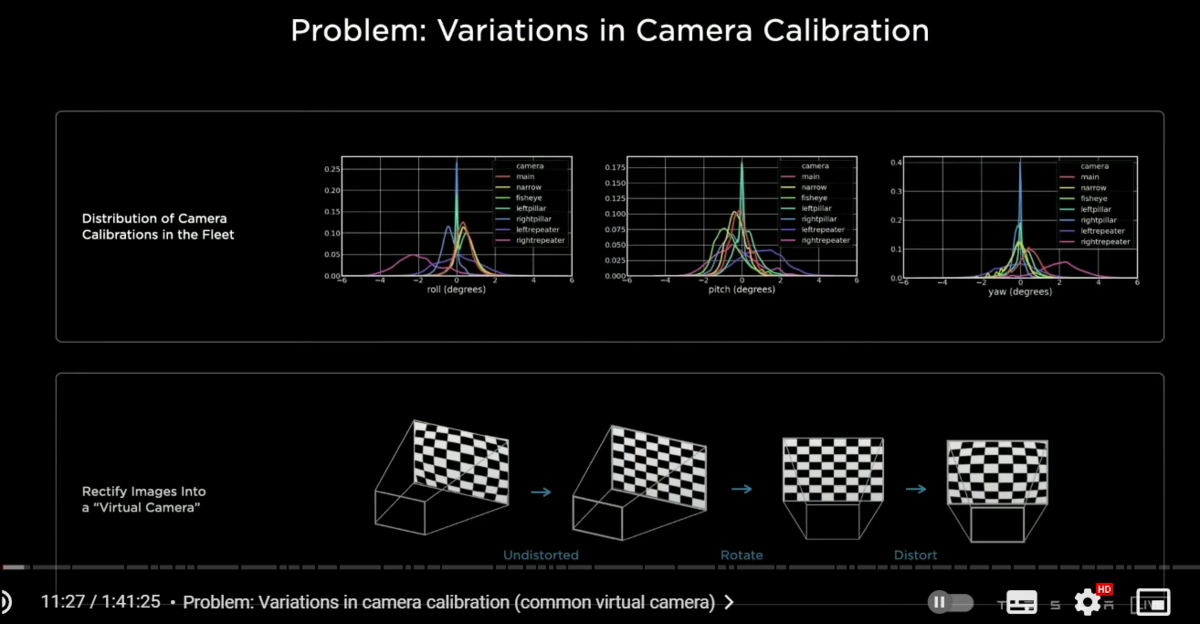
so one more thing you have to be careful with some of the details here when you are trying to get this to work
in particular all of our cars are slightly cockeyed in a slightly different way
and so if you're doing this transformation from image space to the output space
you really need to know what your camera calibration is
and you need to feed that into the neural net
and so you could definitely just like concatenate(文字列を結合する)the camera calibrations of all of the images
and somehow feed them in with an MLP
but we found that we can do much better by transforming all of the images into a synthetic virtual camera(シンセティック・バーチャル・カメラ)
using a special rectification(整流) transform
〇レクティフィケーション→コモンバーチャルカメラ

so this is what that would look like
we insert a new layer right above the image which is rectification layer(整流レイヤー)
it's a function of camera calibration and it translates all of the images into a virtual common camera(バーチャル・コモン・カメラ)
so if you were to average up(次々と平均値を求める) a lot of repeater images(リピーターカメラの画像) for example which faced at the back
without doing this you would get a kind of a blur
but after doing the rectification transformation(整流トランスフォーメーション)
you see that the back mirror gets really crisp(クッキリとした)
this improves the performance quite a bit
〇ドライバブルなベクタースペースの生成
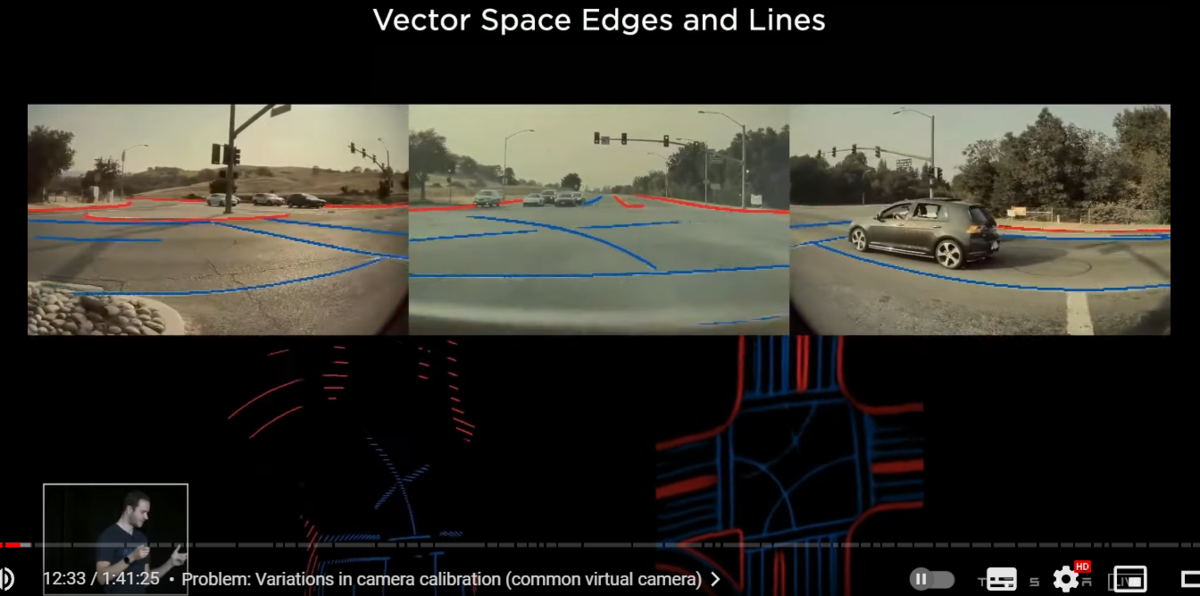
so here are some of the results on the left we are seeing what we had before
and on the right we're now seeing significantly improved predictions coming directly out of the neural net
this is a multi-camera network predicting directly in vector space
it's basically night and day you can actually drive on this
this took some time and some engineering and incredible work from the AI team to actually get this to work and deploy and make it efficient in the car
this also improved a lot of our object detection
〇マルチカムとシングルカムの性能差

so for example here in this video i'm showing single camera predictions in orange
and multi-camera predictions in blue
if you can't predict these cars if you are only seeing a tiny sliver of a car
your detections are not going to be very good
and their positions are not going to be good
but a multi-camera network does not have an issue
here's another video from a more nominal sort of situation
and we see that as these cars in this tight space across camera boundaries
there's a lot of jank that enters into the predictions
and the whole setup just doesn't make sense especially for very large vehicles like this one
and we can see that the multi-camera networks struggle significantly less with these kinds of predictions
so at this point we have multi-camera networks and they're giving predictions directly in vector space
but we are still operating at every single instant in time(個々の瞬間画像) completely independently
〇画像のみの場合の問題点→記憶の欠如

so very quickly we discovered that there's a large number of predictions we want to make that actually require the video context and we need to figure out how to feed this into the net
in particular is this car parked or not
is it moving? how fast is it moving? is it still there? it's temporarily occluded
or for example if i'm trying to predict the road geometry ahead
it's very helpful to know the signs or the road markings that i saw 50 meters ago
〇ビデオニューラルネットアーケティクチャー

so we try to insert video modules(時系列データを認識するビデオモジュール)into our neural network architecture and this is one of the solutions that we've merged on
we have the multi-scale features as we had them from before
and what we are going to now insert is a feature queue module(フィーチャー・キュー・モジュール)
that is going to cache some of these features over time
and then a video module that is going to fuse this information temporally
and then we're going to continue into the heads that do the decoding
now i'm going to go into both of these blocks one by one
also in addition notice here that we are also feeding in the kinematics(キネマティクス/運動学)
this is basically the velocity and the acceleration that's telling us about how the car is moving
so not only are we going to keep track of what we're seeing from all the cameras
but also how the car has traveled
〇フィーチャーキューモジュール

so here's the feature cue and the rough layout of it
we are basically concatenating(連結する) these features over time
and the kinematics of how the car has moved
and the positional encodings and that's being concatenated encoded and stored in a feature queue
and that's going to be consumed by a video module
now there's a few details again to get right
in particular with respect to the pop and push mechanisms
and when do you push
〇時間と空間の記憶

here's a cartoon diagram illustrating some of the challenges
there's going to be the ego cars coming from the bottom and coming up to this intersection here
and then traffic is going to start crossing in front of us
and it's going to temporarily start occluding some of the cars ahead
and then we're going to be stuck at this intersection for a while and just waiting our turn
this is something that happens all the time and it's a cartoon representation of the challenges
so number one with respect to the feature queue and when we want to push into a queue
obviously we'd like to have a time-based queue
where for example we enter the features into the queue say every 27 milliseconds
and so if a car gets temporarily occluded
then the neural network now has the power to be able to look and reference the memory in time
and learn the association that hey even though this thing looks occluded right now
there's a record of it in my previous features
and i can use this to still make a detection
for example suppose you're trying to make predictions about the road surface and the road geometry ahead
and you're trying to predict that i'm in a turning lane and the lane next to us is going straight
then it's really necessary to know about the line markings and the signs
and sometimes they occur a long time ago
and if you only have a time-based queue(時間ベースのキュー) you may forget the features
while you're waiting at your red light
so in addition to a time-based queue we also have a space-based queue(空間ベースのキュー)
we push every time the car travels a certain fixed distance
in this case we have a time based queue and a space-based queue to feed to cache our features
and that continues into the video module
〇ビデオモジュール
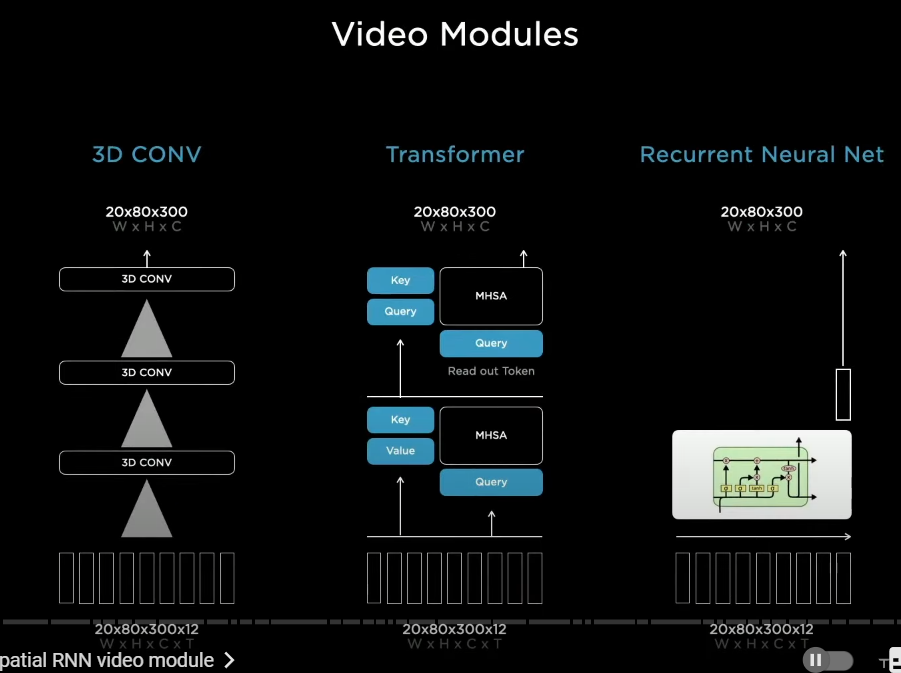
now for the video module we looked at a number of possibilities of how to fuse this information temporally
so we looked at three-dimensional convolutions transformers, axial transformers
(3Dコンボリューション・トランスフォーマーズ、アクシャル・トランスフォーマーズ)
in an effort to try to make them more efficient recurrent neural networks (RNN) of a large number of flavors
〇空間RNNビデオモジュール

i want to spend some time on is a spatial recurrent neural network video module(空間RNNビデオ・モジュール)
because of the structure of the problem we're driving on two-dimensional(2D) surfaces
we can actually organize the hidden state into a two-dimensional lattice(2Dラティス)
and then as the car is driving around
we update only the parts that are near the car and where the car has visibility
so as the car is driving around
we are using the kinematics to integrate the position of the car in the hidden features grid
and we are only updating the RNN at the points where we have that are nearby us
〇多様な空間認識が生まれる
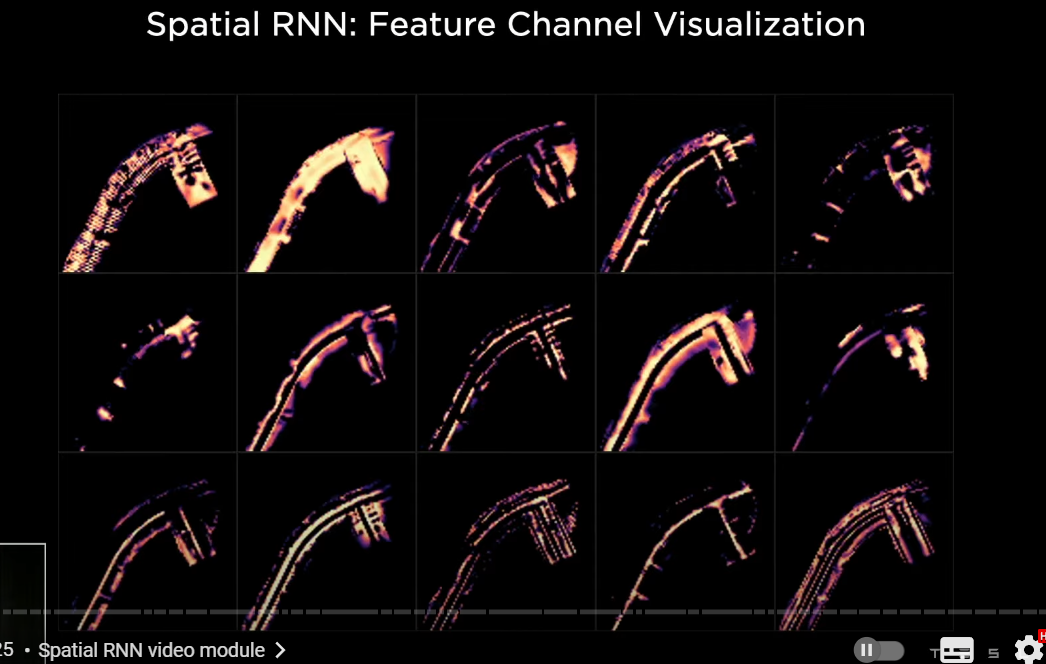
here's an example of what that looks like
the car is driving around
and we're looking at the hidden state of this RNN
and these are different channels in the hidden state(短期記憶、ワーキングメモリの役割を果たす)
so after optimization and training this neural net
some of the channels are keeping track of different aspects of the road
for example the centers of the road the edges the lines the road surface and so on
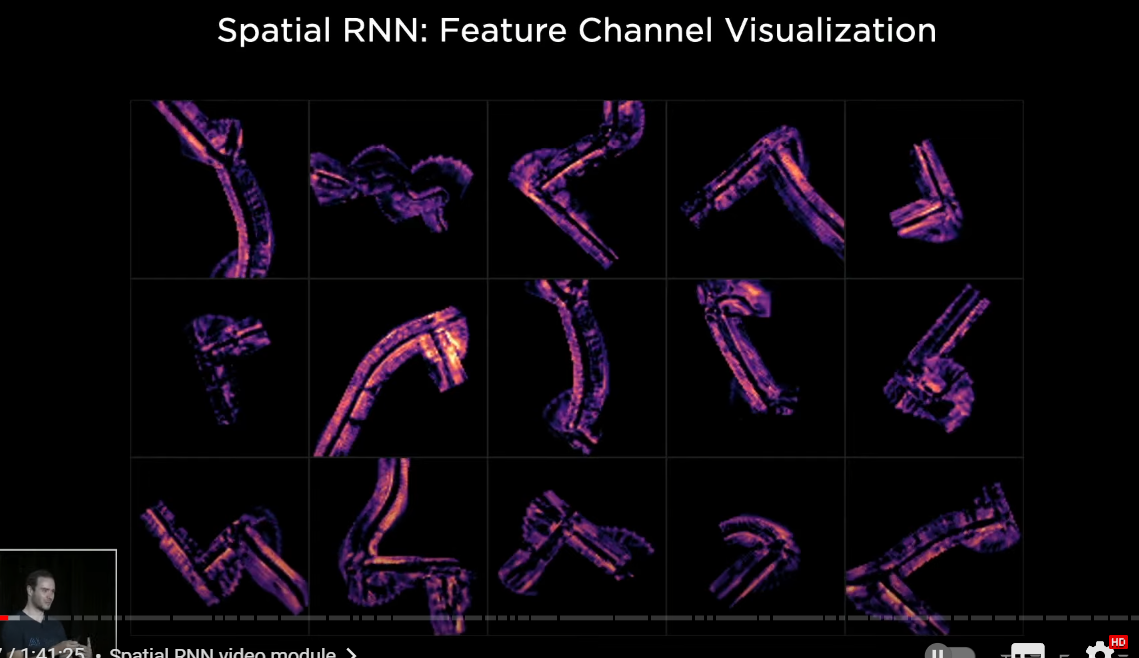
so this picture is looking at the mean of the first 10 channels for different traversals of different intersections in the hidden state
there's cool activity as the recurrent neural network is keeping track of what's happening at any point in time
and you can imagine that we've now given the power to the neural network
to actually selectively read this memory and write to this memory
so for example if there's a car right next to us and is occluding some parts of the road
then now the network has the ability to not to write to those locations
but when the car goes away and we have a good view
then the recurring neural net can say okay we have very clear visibility we definitely want to write information about what's in that part of space
〇空間RNN
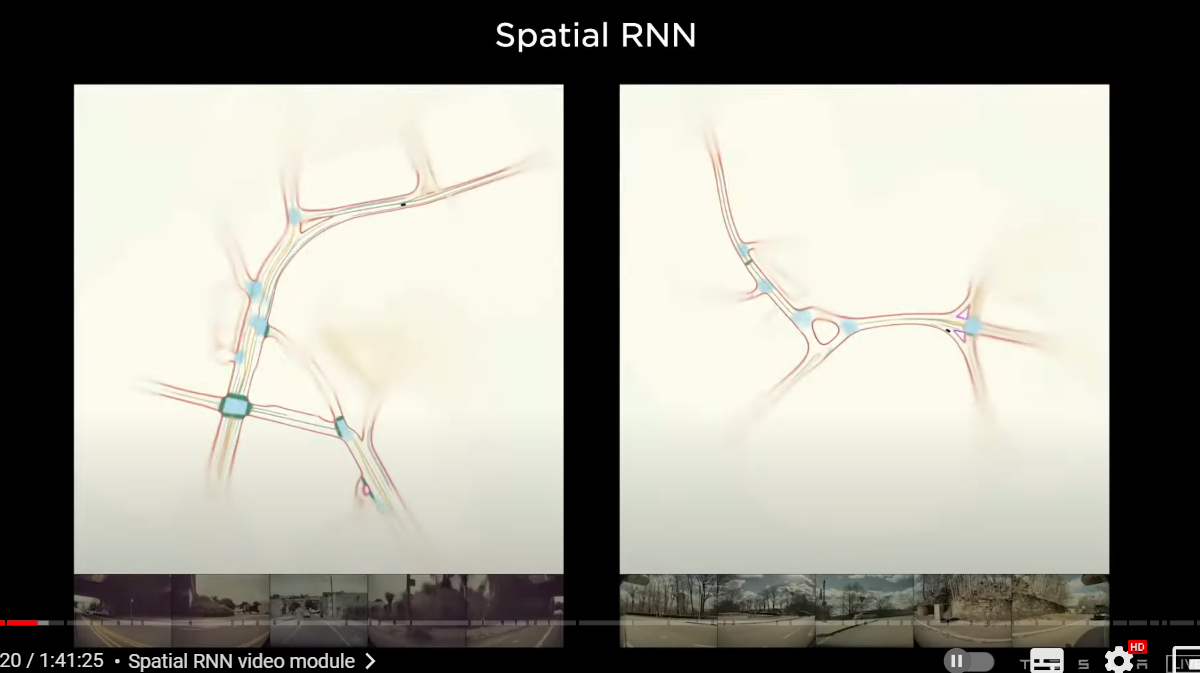
here's a few predictions that show what this looks like
here we are making predictions about the road boundaries in red
intersection areas in blue road centers and so on so
we're only showing a few of the predictions here
just to keep the visualization clean
and yeah this is done by the spatial RNN(空間RNN)
and this is only showing a single clip
a single traversal but you can imagine there could be multiple trips through here
and number of cars a number of clips could be collaborating to build this map
which is an HD map
except it's not in a space of explicit items
The “HD map”is in a space of features of a recurrent neural network
the video networks also improved our object detection
〇ビデオネットワークによる、ドロップの改善

(オクルードされた場合に、ビデオモジュールでは2台の車両は、ディテクトされているのに、シングルフレームでは、ドロップしている)
so in this example i want to show you a case where there are two cars over there and one car is going to drive by and occlude them briefly
so look at what's happening with the single frame predictions
and the video predictions as the cars pass in front of us
so that makes a lot of sense so a quick playthrough through what's happening when both of them are in view
the predictions are roughly equivalent
and you are seeing multiple orange boxes
because they're coming from different cameras
when they are occluded the single frame networks drop the detection
but the video module remembers it and we can persist the cars
and then when they are only partially occluded
the single frame network is forced to make its best guess about what it's seeing and it's forced to make a prediction and it makes a terrible prediction
but the video module knows that there's only a partial
knows that this is not a very easily visible part right now and doesn't actually take that into account
〇深度と加速度の改善

we also saw significant improvements in our ability to estimate depth and especially velocity
so here i'm showing a clip from our remove the radar push
where we are seeing the radar depth and velocity in green
and we were trying to match or even surpass the signal just from video networks alone
and what you're seeing here is in orange
we are seeing a single frame performance
and in blue we are seeing again video modules and so you see that the quality of depth is much higher
and for velocity
the orange signal, you can't get velocity out of a single frame network
so we just differentiate depth to get that but the video module is right on top of the radar signal
and so we found that this worked extremely well for us
〇現段階の全体図

so here's putting everything together this is what our architectural roughly looks like today
we have raw images feeding on the bottom
they go through a rectification layer to correct for camera calibration
and put everything into a common virtual camera
we pass them through regnet's (residual networks) to process them into a number of features at different scales
we fuse the multi-scale information with BiFPN
this goes through transformer module to re-represent it into the vector space
in the output space this feeds into a feature queue in time
or space that gets processed by a video module like the spatial rnn
and then continues into the branching structure of the hydra net
with trunks and heads for all the different tasks
so that's the architecture roughly what it looks like today
and on the right you are seeing some of its predictions which visualize both in a top-down vector space
and also in images this architecture has been definitely complexified from just very simple image-based single network about three or four years ago
and continues to evolve
now there's still opportunities for improvements that the team is actively working on
you'll notice that our fusion of time and space is fairly late in neural network terms
we can do earlier fusion of space or time
and do cost volumes or optical flow like networks on the bottom
or our outputs are dense rasters(ラスタ)
and it's actually pretty expensive to post-process some of these dense rasters in the car
and we are under very strict latency requirements so this is not ideal
we actually are looking into all kinds of ways of predicting
just the sparse structure(スパース・ストラクチャー) of the road
maybe point by point or in some other fashion that is that doesn't require expensive post processing
but this basically is how you achieve a very nice vector space
〇インド出身のアショクが登壇
最適化問題を解く

hi everyone my name is ashok i lead the planning and controls auto labeling and simulation teams
the visual networks take dense video data and then compress it down into a 3D vector space
the role of the planner is to consume this vector space and get the car to the destination while maximizing the safety comfort and the efficiency of the car
even back in 2019 our planner was pretty capable driver
it was able to stay in the lanes make lane changes as necessary
and take exits of the highway
but cdc(市街地) driving is much more complicated
there are structured lane lines and vehicles do much more free from driving
then the car has to respond to all of curtains and crossing vehicles and pedestrians doing funny things
〇プランニングにおける問題点

what is the key problem in planning
1,number one the action space is very non-convex(非凸型) and
→局所最適に陥ってしまうケースが数多くあるということ
2,number two it is high dimensional
what I mean by non-convex is there can be multiple possible solutions that can be independently good but getting a globally consistent solution is pretty tricky
so there can be pockets of local minima that the planning can get stucked into
and secondly the high dimensionality comes because the car needs to plan for the next 10 to 15 seconds
and needs to produce the position velocities and acceleration or this entire window
there are many parameters to be produced at runtime
discrete search(離散検索、個別探索) methods are really great at solving non-convex problems
because they are discrete they don't get stuck in local minima(局所最小、局所最適、部分最適)
whereas continuous function optimization(連続最適化) can easily get stuck in local minima and
produce poor solutions that are not great
on the other hand for high dimensional problems
a discrete search sucks
because it does not use any graded information(グレーディド・インフォ) so literally has to go and explore each point to know how good it is
whereas continuous optimization use gradient-based methods(確率勾配法) to very quickly go to a good solution
〇ハイブリッドプランニングによる、局所最適の回避
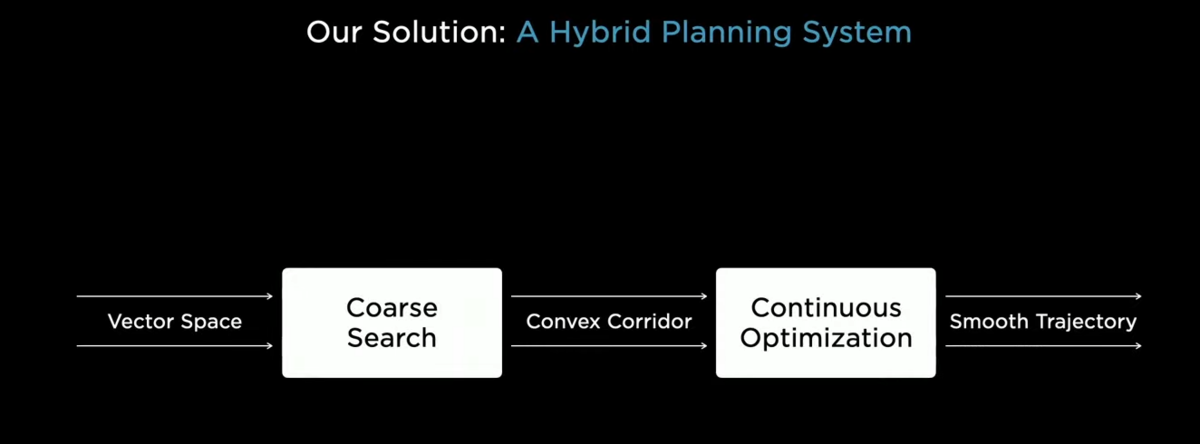
our solution to this problem is to break it down hierarchically
first use a coarse search method(コアース・サーチ) to crunch down(踏みつける、かみ砕く) the non-convexity and come up with a convex corridor
→コンベックスな問題に置き換える
and then use continuous optimization techniques to make the final smooth trajectory
→のちに連続的最適化
〇多くのプランニングを走らせる
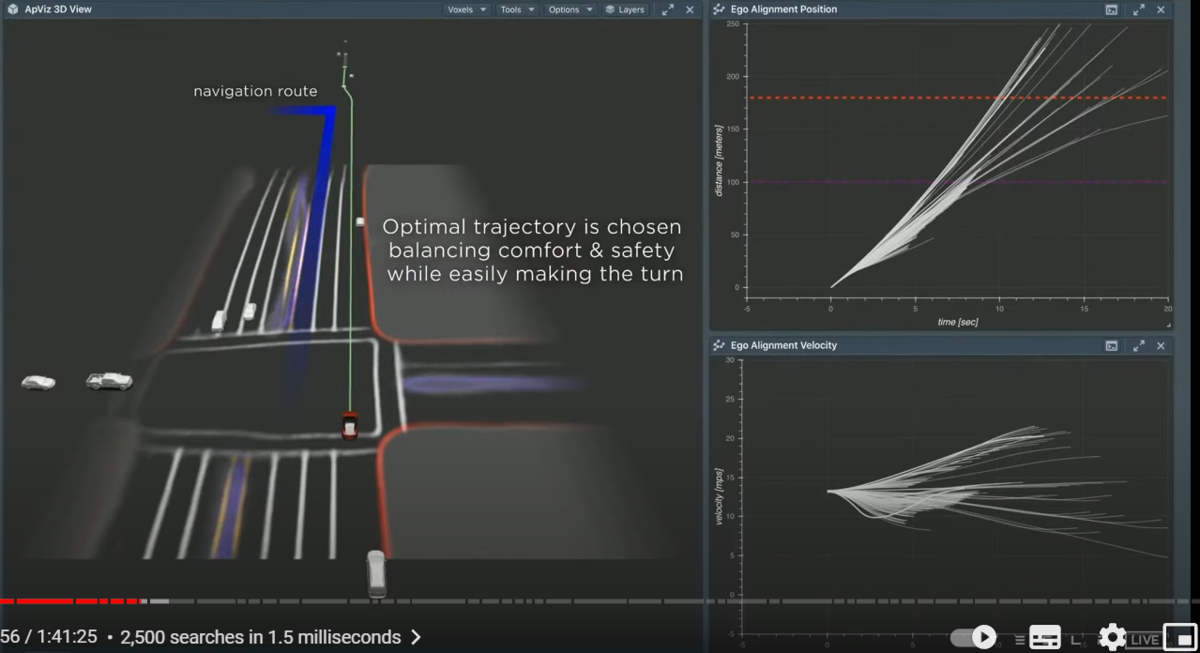
let's see an example of how the search operates
so here we're trying to do a lane change
in this case the car needs to do two back-to-back(連続) lane changes to make the left turn up ahead
for this the car searches over different maneuvers
the first one is a lane change that's close by
but the car breaks pretty harshly so it's pretty uncomfortable
the next maneuver tried is the lane change
it speeds up
goes in front of the other cars and do the lane change bit late
but now it risks missing the left turn
we do thousands of such searches in a very short time span
because these are all physics-based models these futures are very easy to simulate
and in the end we have a set of candidates and we finally choose one based on the optimality conditions of safety comfort and easily making the turn
so now the car has chosen this path
and you can see that as the car executes this trajectory
it matches what we had planned
the cyan(水色) plot on the right side is the actual velocity of the car
and the white line be underneath was a plan
so we are able to plan for 10 seconds here and able to match that when you see in hindsight(後知恵、後付け、後から)
so this is a well-made plan
〇自分以外の物体のプランニング

when driving alongside other agents it's important to not just plan for ourselves but instead we have to plan for everyone jointly
and optimize for the overall scenes traffic flow
in order to do this what we do is we literally run the autopilot planner on every single relevant object in the scene
(関連するすべてのオブジェクトにオートパイロット・プラナーを走らせる)
〇道を譲りあうケース

here's an example of why that's necessary
this is an auto corridor i'll let you watch the video for a second
there was autopilot driving an auto corridor going around parked cars cones and poles
here there's a 3D view of the same thing
the oncoming car arrives now and autopilot slows down a little bit
but then realizes that we cannot yield to them because we don't have any space to our side but the other car can yield to us instead
so instead of just blindly breaking here
they can pull over and should yield to us because we cannot yield to them
and assertively(自信を持って) makes progress
a second oncoming car arrives now this vehicle has higher velocity
we literally run the autopilot planner for the other object
so in this case we run the panel for them that object's plan
now goes around their parked cars
and then after they pass the parked cars goes back to the right side of the road for them
since we don't know what's in the mind of the driver
we actually have multiple possible futures for this car
one future is shown in red the other one is shown in green
and the green one is a plan that yields to us
but since this object's velocity and acceleration are pretty high
we don't think that this person is going to yield to us
and they are actually going to go around these parked cars
so autopilot decides that okay i have space here
this person's definitely gonna come so i'm gonna pull over
so as autopilot is pulling over we notice that
the car has chosen to yield to us
based on their yaw rate and their acceleration
and autopilot immediately changes his mind
and continues to make progress
this is why we need to plan for everyone
because otherwise we wouldn't know that this person is going to go around the other parked cars
and come back to their side
if we didn't do this autopilot would be too timid(臆病)
and would not be a practical self-driving car
〇損失関数の最小化


so now we saw how the search and planning for other people set up a convex valley
finally we do a continuous optimization to produce the final trajectory
that the planning needs to take
the gray width area is the convex corridor(コンベクス・コリドー)
and we initialize the spline in heading and acceleration
parameterized or the arc length of the plan
and you can see that continuously the compromisation makes fine-grained changes to reduce all of its costs
some of the costs are distance from obstacles traversal time and comfort
for comfort you can see that the lateral acceleration plots on the right have nice trapezoidal shapes
on the right side the green plot that's a nice trapezoidal(台形の) shape
and if you record on a human trajectory
this is pretty much how it looked like
the lateral(側面、側部) jerk(躍度、加加速度、単位時間あたりの加速度の変化率) is also minimized
so in summary we do a search for both us and everyone else in the scene
we set up a convex corridor and then optimize for a smooth path
together these can do some really neat things like shown above
〇複雑なケース

but driving looks a bit different in other places like where i grew up from
it's very much more unstructured cars and pedestrians cutting each other harsh braking honking it's a crazy world
we can try to scale up these methods but it's going to be really difficult to efficiently solve this at runtime(運転しているその瞬間ごとに)
instead what we want to do is using learning based methods
and i want to show why this is true
so we're going to go from this complicated problem to a much simpler toy parking problem
but still illustrates the core of the issue
here this is a parking lot, the ego car is in blue and needs to park in the green parking spot here
so it needs to go around the curbs the parked cars and the cones shown in orange here
there's a simple baseline it's A-star
A-star is the standard algorithm that uses a ladder space search(ラダースペースサーチ)
and in this case the heuristic here is the Euclidean distance to the goal

you can see that it directly shoots towards the goal but very quickly gets trapped in a local minima and it backtracks(引き返す) from there
and then searches a different path to try to go around this parked car
eventually it makes progress and gets to the goal but it ends up using 400,000 nodes for making this
obviously this is a terrible heuristic
we want to do better than this
〇ブルートフォース+ガイド

so if you added a navigation route to it and has the car to follow the navigation route
while being close to the goal this is what happens
the navigation route helps immediately
but still when it encounters cones or other obstacles
it basically does that same thing as before
backtracks and then searches the whole new path
this poor search has no idea that these obstacles exist
it literally has to go there and has to check if it's in collision
and if it's in collision then back up
the navigation heuristic helped but still took 22,000 nodes
we can design more these heuristics to help the search make go faster
but it's really tedious(うんざり、退屈) and hard to design a globally optimal heuristic
even if you had a distance function from the cones that guided the search
this would only be effective for the single cone
〇モンテカルロツリー探索

what we need is a global value function(グローバル・バリュー関数)
so instead of what we want to use is neural networks to give this heuristic for us
the vision networks produces vector space and we have cars moving around in the vector space
this looks like a atari game and it's a multiplayer version
so we can use techniques such as alpha zero etc that was used to solve GO and other atari games to solve the same problem
so we're working on neural networks that can produce state and action distributions
that can then be plugged into Monte-Carlo Tree Search(モンテ・カルロ・ツリーサーチ) with various cost functions
some of the cost functions can be explicit cost functions
like distance, collisions, comfort, traversal time etc
but they can also be interventions from the actual manual driving events
we train such a network for this simple parking problem
so here again same problem
〇オーダーオブマグニチュードの改善

let's see how MCT(モンテカルロツリー) searched us
so here you notice that the plan is basically able to make progress towards the goal in one shot
to notice that this is not even using a navigation heuristic just given the scene
the plan is able to go directly towards the goal
all the other options you're seeing are possible options
it does not choose any of them just using the option that directly takes it towards the goal
the reason is that the neural network is able to absorb the global context of the scene
and then produce a value function that effectively guides it towards the global minima(全体最適)
as opposed to getting stuck in any local minima
so this only takes 288 nodes
(40万→2万→300)
and several orders of magnitude less than what was done in the A-star with the equilibrium distance heuristic
〇プラナーの設計
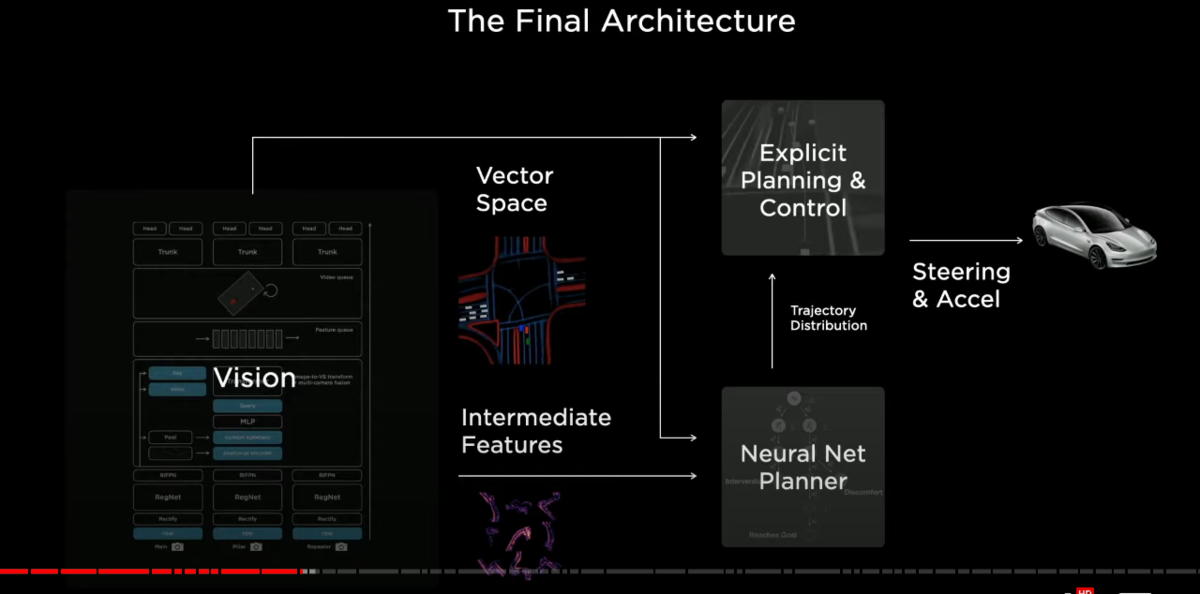
this is what a final architecture is going to look like
the vision system is going to crush down the dense video data into a vector space
it's going to be consumed by both an expressive planner and a neural network planner
in addition to this
the neural network planner can also consume intermediate features of the network
(エクスプレッシブ・プラナー、NNプラナー、インターミディエートフィーチャーズ)
together this producer trajectory distribution
and it can be optimized end to end both with explicit cost functions(顕示コスト関数) and human intervention and other data
this then goes into explicit planning function(顕示プランニング関数)
that does whatever is easy for that and produces the final steering and acceleration commands for the car
with that we need to now explain how we train these networks
and for training these networks we need large data sets
〇アンドレイが再び登壇
the story of data sets is critical
so far we've talked only about neural networks but neural networks only establish an upper bound on your performance
many of these neural networks have hundreds of millions of parameters and these hundreds of millions of parameters they have to be set correctly
if you have a bad setting of parameters it's not going to work
so neural networks are just an upper bound
you also need massive data sets to actually train the correct algorithms inside them
now in particular I mentioned we want data sets directly in the vector space
and so the question becomes how can you accumulate
because our networks have hundreds millions of parameters
how do you accumulate millions and millions of vector space examples
that are clean and diverse to train these neural networks effectively
so there's a story of data sets and how they've evolved
on the side of all of the models and developments that we've achieved
when i joined roughly four years ago we were working with a third party to obtain a lot of our data sets
unfortunately we found quickly that working with a third party to get data sets for something this critical was just not going to cut it
the latency of working with a third party was extremely high and honestly the quality was not amazing and so in the spirit of full vertical integration at tesla
we brought all of the labeling in-house and
over time we've grown more than one thousand person data labeling org
that is full of professional labelers who are working very closely with the engineers
so actually they're here in the us and co-located with the engineers here in the area as well
and so we work very closely with them and we also build all of the infrastructure ourselves for them from scratch
so we have a team we are going to meet later today that develops and maintains all of this infrastructure for data labeling
for example i'm showing some of the screenshots of some of the latency throughput and quality statistics that we maintain about all of the labeling workflows
and the individual people involved and all the tasks and how the numbers of labels are growing over time
we found this to be quite critical and we're very proud of this
〇数年前のラベリング
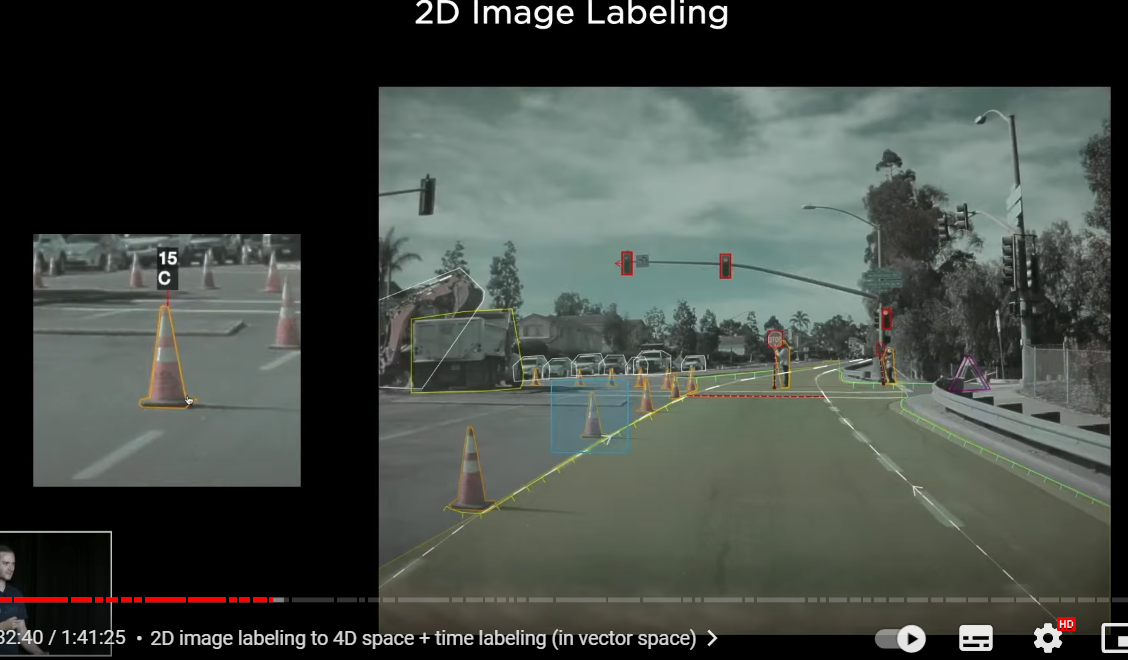
in the beginning roughly three or four years ago most of our labeling was in image space(2D labeling)
and this takes quite time to annotate(注釈をつける、ラベリングする) an image like this
and this is what it looked like where we are drawing polygons and polylines
on top of these single individual images
as we need millions of vector space labels
this method is not going to cut it
〇4Dラベリング
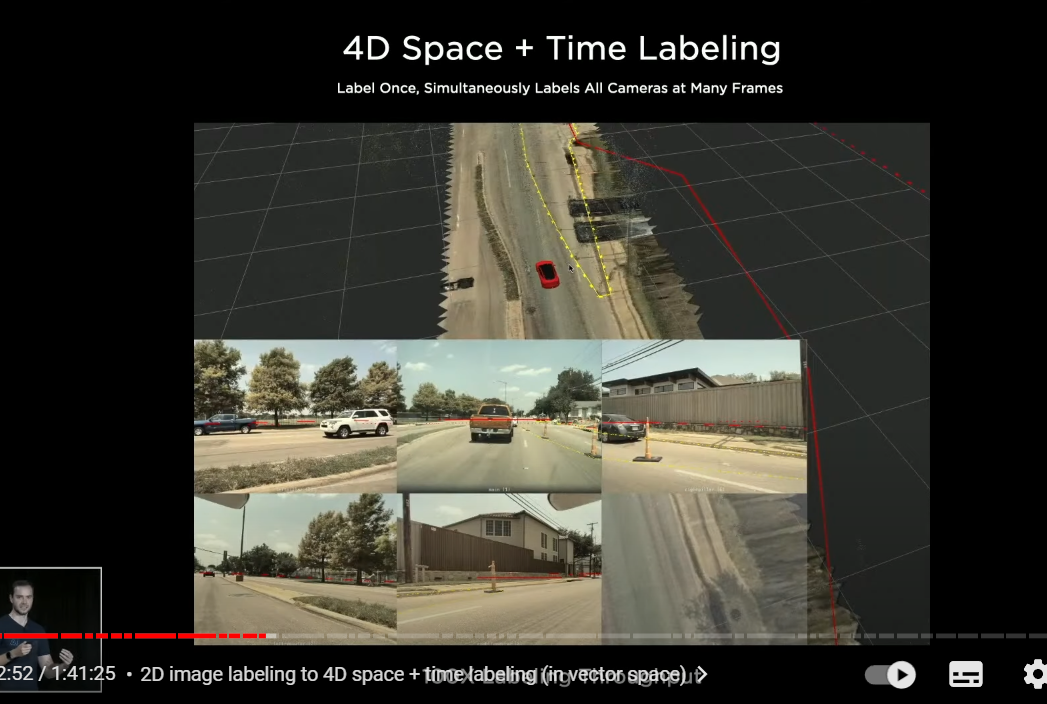
quickly we graduated to three-dimensional or four-dimensional labeling
where we directly label in vector space(多変数空間) not in individual images
so here is a clip and you see a very small reconstruction of the ground plane on which the car drove
and a little bit of the point cloud here that was reconstructed
and what you're seeing here is that the labeler is changing the labels directly in vector space
and then we are reprojecting those changes into camera images
(カメライメージへはあくまでプロジェクションしてるだけ。ラベリングはベクタースペースで行われる)
so we're labeling directly in vector space and this gave us a massive increase in throughput
because if it is labeled once in 3D and then you get to reproject
but even this was actually not going to cut it
because people and computers have different pros and cons
so people are extremely good at things like semantics but computers are very good at geometry reconstruction triangulation tracking
and for us it's much more becoming a story of how do humans and computers collaborate to actually create these vector space data sets
and so we're going to now talk about auto labeling which is the infrastructure we've developed for labeling these clips at scale
〇インド出身のアショクが再び登壇
こういうふうにラベリングしたいんだが。

even though we have lots of human labelers
the amount of training data needed for training the network significantly outnumbers them
we invested in a massive auto labeling pipeline
here's an example of how we label a single clip
a clip is entity that has dense sensor data
like videos,IMU data,GPS automatically etc
this can be 45 second to a minute long
these can be uploaded by our own engineering cars or from customer cars
we collect these clips and then send them to our servers
where we run a lot of neural networks offline to produce intermediate results
like segmentation masks depth point matching etc
this then goes to a lot of robotics and AI algorithms to produce a final set of labels
that can be used to train the networks
〇NeRFの利用
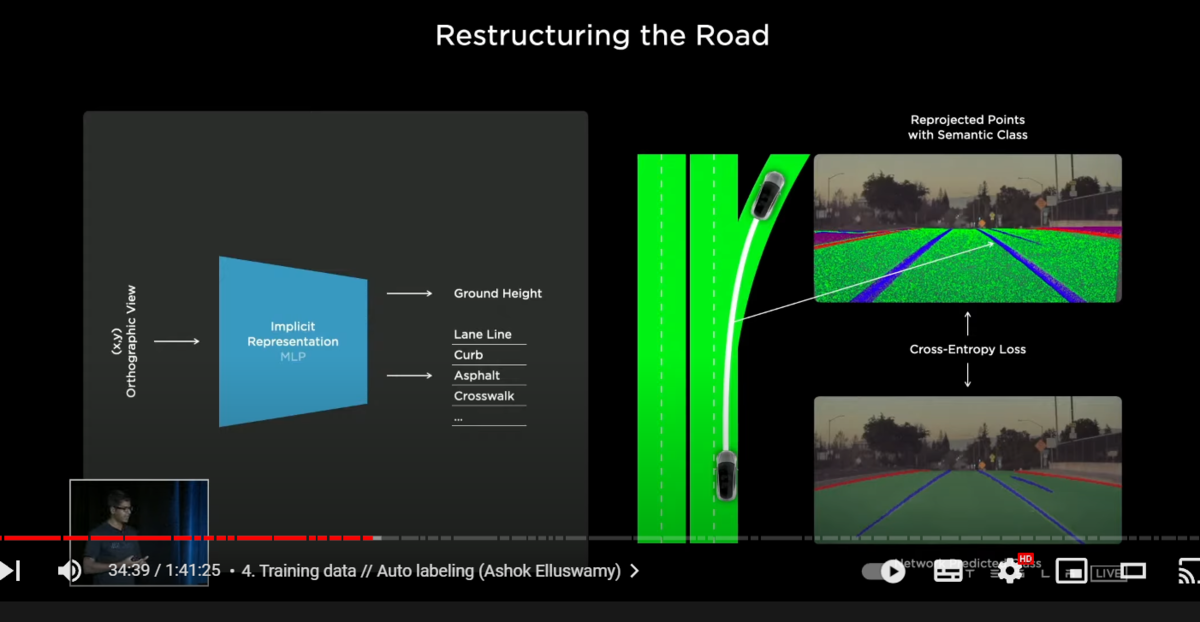
one of the first tasks we want to label is the road surface
typically we can use splines or meshes to represent the road surface
but because of the topology restrictions
those are not differentiable and not amenable(従順) to producing this
so what we do instead from last year is in the style of neural radiance fields work (NeRF:ニューラルネットワークによる三次元空間表現手法)
we use an implicit representation to represent the road surface
here we are querying xy points on the ground
and asking for the network to predict the height of the ground surface
along with various semantics(セマンティクス:個々の部分の意味) such as curves lane boundaries road surface rival space etc
given a single xy we get a z together these make a 3D point
and they can be re-projected into all the camera views
so we make millions of such queries and get lots of points
these points are re-projected into all the camera views
on the top right here, we are showing one such camera image with all these points re-projected
now we can compare this re-projected point with the image space prediction of the segmentations
and jointly optimizing this all the camera views across space and time
and produces an excellent reconstruction
〇ベクトル空間上で、再構成されたロードをプロジェクション

here's an example of how that looks like
so here this is an optimized road surface that is reproduction to the eight cameras that the car has
and across all of time
and you can see how it's consistent across both space and time
〇運転しながらベクトル空間を生成している

so a single car driving through some location can sweep out some patch around the trajectory using this technique
but we don't have to stop there
so here we collected different clips from different cars at the same location
and each of fleet sweeps out some part of the road
〇生成されたベクトル空間を相互に組み合わせる
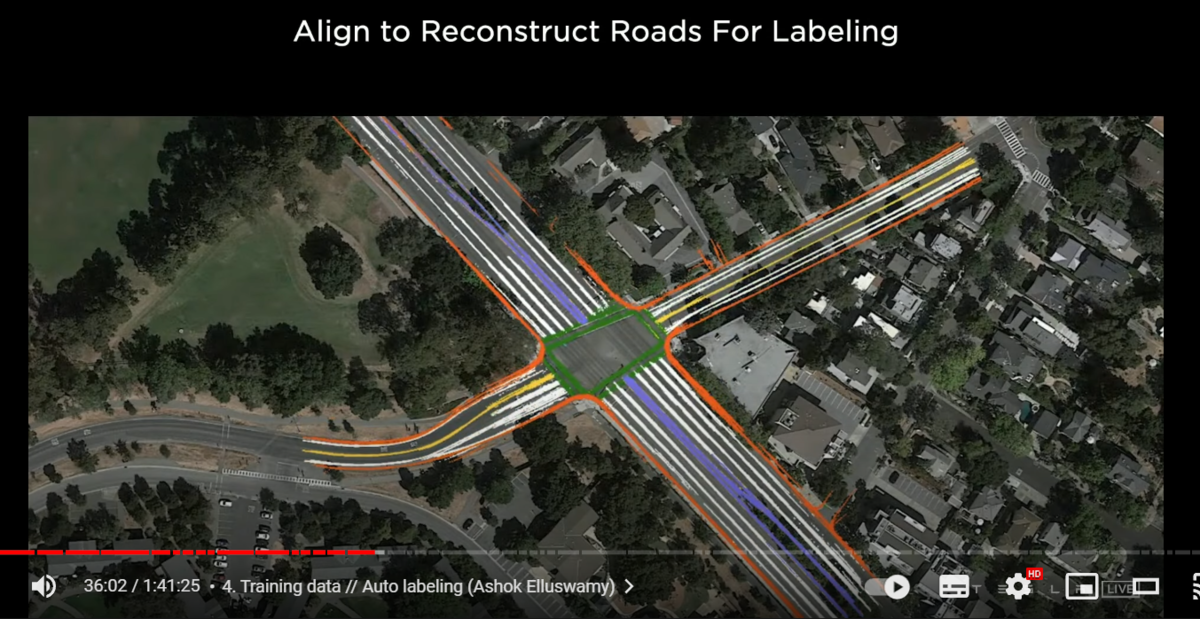
now we can bring them all together into a single giant optimization
so here these 16 different trips are organized
using various features such as road edges lane lines
all of them should agree with each other
and also agree with all of their image space observations
together this produces an effective way to label the road surface
not just where the car drove but also in other locations that it hasn't driven
the point of this is not to build HD-maps or anything like that
it's only to label the clips through these intersections
so we don't have to maintain them forever
as long as the labels are consistent with the videos that they were collected
then humans can come on top of this
clean up any noise or add additional metadata to make it even richer
〇ポイントクラウド

we don't have to stop at just the road surface
we can also arbitrarily(任意に) reconstruct 3D static obstacles
here this is a reconstructed 3D point cloud from our cameras
the main innovation here is the density of the point cloud
typically these points require texture to form associations from one frame to the next frame
but here we are able to produce these points even on textured surfaces
like the road surface or walls
and this is really useful to annotate(注釈をつけて、ラベリングすること) arbitrary obstacles
that we can see on the scene in the world
〇利点その1 後知恵

one more cool advantage of doing all of this on the servers offline is that
we have the benefit of hindsight(後知恵)
this is a super useful hack
because say in the car then the network needs to produce the velocity
it just has to use the historical information and guess what the velocity is
but here we can look at both the history but also the future
we can cheat and get the correct answer of the kinematics like velocity acceleration etc
〇利点その2 パーシステンシー

one more advantage is that we have different tracks
but we can switch them together even through occlusions
because we know the future
we have future tracks
we can match them and then associate them
here you can see the pedestrians on the other side of the road are persisted
even through multiple occlusions by these cars
this is really important for the planner
because the planner needs to know if it saw someone it still needs to account for them even they are occluded
so this is a massive advantage
〇ベクトル空間の生成に成功

combining everything together
we can produce these amazing data sets
that annotate all of the road texture all the static objects and all the moving objects even through occlusions
producing excellent kinematic labels all you can see how the cars turn smoothly
produce really smooth labels all the pedestrians are consistently tracked
the parked cars obviously zero velocity so we can know that cars are parked
so this is huge for us
this is one more example of the same thing you can see how everything is consistent
we want to produce a million labeled clips of such and train our multi-cam video networks(マルチカム・ビデオ・ネットワーク) with such a large data set
and want to crush this problem
we want to get the same view that's consistent that you're seeing in the car
〇レアケースでのドロップ

we started our first exploration of this with the Remove The Radar project
we removed it in a short time span like within three months
in the early days of the network
we noticed for example in lower security conditions the network can suffer understandably
because obviously this truck just dumped a bunch of snow on us and it's really hard to see
but we should still remember that this car was in front of us
but our networks early on did not do this because of the lack of data in such conditions
〇フリートからデータ収集


so what we did was that we asked the fleet to produce lots of similar clips
and the fleet responded it
it produces lots of video clips where shit's falling out of other vehicles
and we've sent this through auto leveling pipeline
that was able to label 10k clips within a week(1週間で1万ビデオクリップのラベリング)
this would have taken several months with humans labeling
so we did this for 200 of different conditions
and we were able to very quickly create large data sets
and that's how we were able to remove radar
〇もうドロップしない。レーダーもいらない。

so once we train the networks with this data
you can see that it's totally working and keeps the memory that this object was there
〇ベクトル空間からシミュレーションへ


finally we wanted to get a cyber truck into a data set for remove the radar
can you all guess where we got this clip from
it's rendered it's our simulation
it was hard for me to tell initially and it looks very pretty
in addition to auto labeling
we also invest heavily in using simulation for labeling our data
(シミュレーションとオート・ラベリングの関係)
so this is the same scene as seen before but from a different camera angle
so a few things that i wanted to point out
for example the ground surface it's not a plane asphalt there are lots of cars and cracks and tower seams there's some patchwork done
on top of it vehicles move realistically
the truck is articulated even goes over the curb and makes a wide turn
the other cars behave smartly they avoid collisions they go around cars
and also brake and accelerate smoothly
Autopilot is driving the car with the logo on the top and it's making unprotected left turn
〇シミュレーション上ではすべてが完璧にラベリングされている

since it's a simulation, it starts from the vector space so it has perfect labels
here we show a few of the labels that we produce
these are vehicle cuboids with kinematics
depth surface normals segmentation but
アンドレア・カパーシー may name a new task that he wants next week
and we can very quickly produce it
because we already have the vector space and we can write the code to produce these labels quickly
〇シミュレーションが有効となるケース

so when does simulation help
- データの入手が難しいケース
number one it helps when the data is difficult to source(手に入れる) as large as our fleet is
(テスラほどのオートパイロット搭載車両数を持ってしても)
it can be hard to get some crazy scenes like this couple
they run with their dog running on the highway while there are other high-speed cars around
this is a rare scene but still can happen
and autopilot still needs to handle it
- ラベリングに膨大な作業が必要な時
it helps when data is difficult to label
there are hundreds of pedestrians crossing the road
this could be a manitoban downtown people crossing the road
it's going to take several hours for humans to label this clip
and even for automatic labeling algorithms
this is really hard to get the association right
and it can produce bad velocities
but in simulation this is trivial
because you already have the objects
you just have to spit out the cuboids and the velocities
- クローズド・ループにおける適正行動を導入したいとき
finally it helps when we introduce closed loop behavior
where are the cars and where it needs to be
in a determining situation or the data depends on the actions
this is the only way to get it reliably
all this is great
1
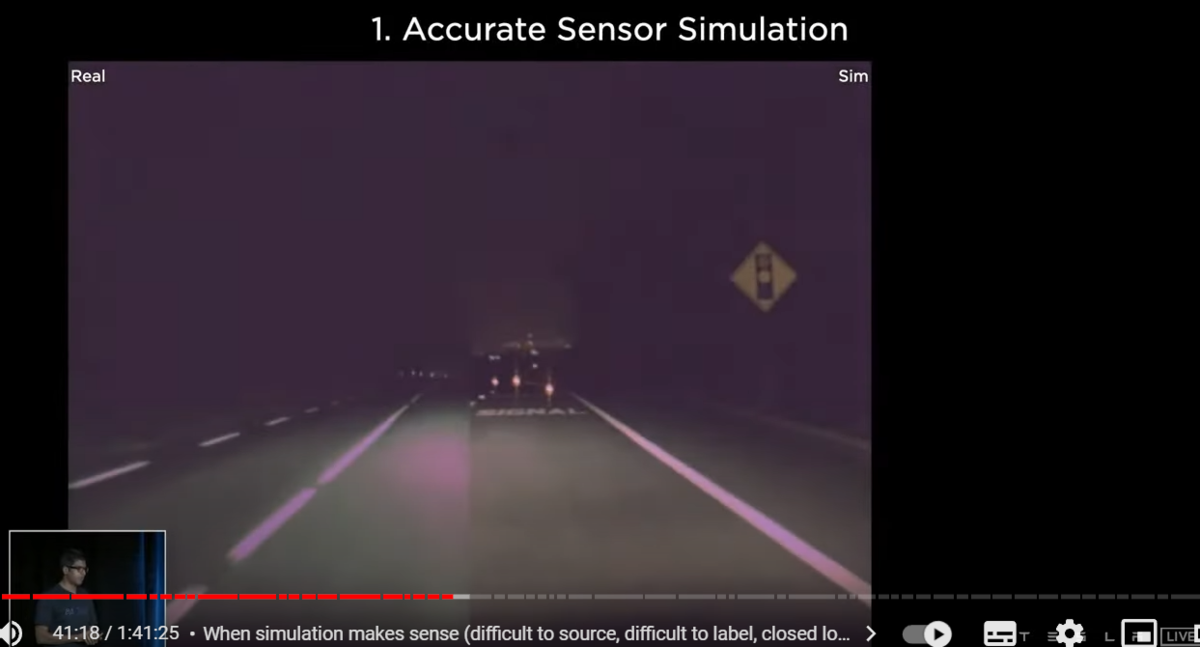

what's needed to make this happen
number one accurate sensor simulation again
the point of the simulation is not to produce pretty pictures
it needs to produce what the camera in the car would see
and what other sensors would see
here we are stepping through different exposure settings of the real camera on the left side
and the simulation on the right side
we're able to match what the real cameras do
in order to do this we had to model a lot of the properties of the camera
in our sensor simulation starting from sensor noise motion blur optical distortions even headlight transmissions even like diffraction patterns of the wind shield etc
we don't use this just for the autopilot software
we also use it to make hardware decisions such as
lens design
camera design
sensor placement or even headlight transmission properties
2

second we need to render the visuals in a realistic manner
you cannot have what in the game industry called jaggies
these are aliasing(エイリアシング) artifacts that are a dead giveaway
this is simulation we don't want them
so we go through a lot of paints to produce a nice special temporal anti-aliasing
we also are working on neural rendering techniques(ニューラル・レンダリング) to make this even more realistic
in addition we also used Ray-tracing to produce realistic lighting and global illumination
3

we obviously need more than four or five cars
because the network will easily overfit(過学習、過剰最適化)
because it knows the sizes
so we need to have realistic assets like the moves on the road
we have thousands of assets in our library
and they can wear different shirts and actually can move realistically
we also have a lot of different locations mapped and created environments
we are actually 2000 miles of road built and this is almost the length of the roadway from the east coast to the west coast of the united states
in addition we have built efficient tooling to build several miles more on a single day on a single artist
but this is just tip of the iceberg
4

actually as opposed to artists making these simulation scenarios
most of the data that we use to train is created procedurally using algorithms
these are all procedurally created roads with lots of parameters
such as curvature various trees cones poles cars with different velocities
and the interaction produce an endless stream of data for the network
but a lot of this data can be boring because the network may already get it correct
what we do is we also use ML based techniques to put up
for the network to see where it's failing at and to create more data around the failure points of the network
we try to make the network performance better in closed loop
5

so in simulation, we want to recreate any failures that happens to the autopilot
on the left side you're seeing a real clip that was collected from a car
it then goes through our auto labeling pipeline to produce a 3D reconstruction of the scene
along with all the moving objects combined with the original visual information
we recreate the same scene synthetically and create a simulation scenario entirely out of it
and then when we replay autopilot on it
autopilot can do entirely new things and
we can form new worlds new outcomes from the original failure
this is amazing because we don't want autopilot to fail in actual fleet
when it fails we want to capture it and keep it to that bar

we can also use neural rendering techniques to make it look even more realistic
we take the original video clip
we create a synthetic simulation from it and then apply neural rendering techniques on top of it
this one is very realistic and looks like it was captured by the actual cameras
i'm very excited for what simulation can achieve
but this is not all because networks trained in the car already used simulation data
we used 300million images(3億枚) with almost half a billion labels(5億ラベル)
and we want to crush down all the tasks that are going to come up for the next several months
with that I invite ミラン to explain how we scale these operations and really build a label factory and spit out millions of labels

テスラ財務現状&予測 AUG-2021 by James Stephenson
Thank you James for everything you have done to the Tesla community.
ジェームスさん、いつもテスラコミュニティに貢献してくださり、ありがとうございます。
1
https://twitter.com/ICannot_Enough/

2
https://twitter.com/ICannot_Enough/

3
https://twitter.com/ICannot_Enough/
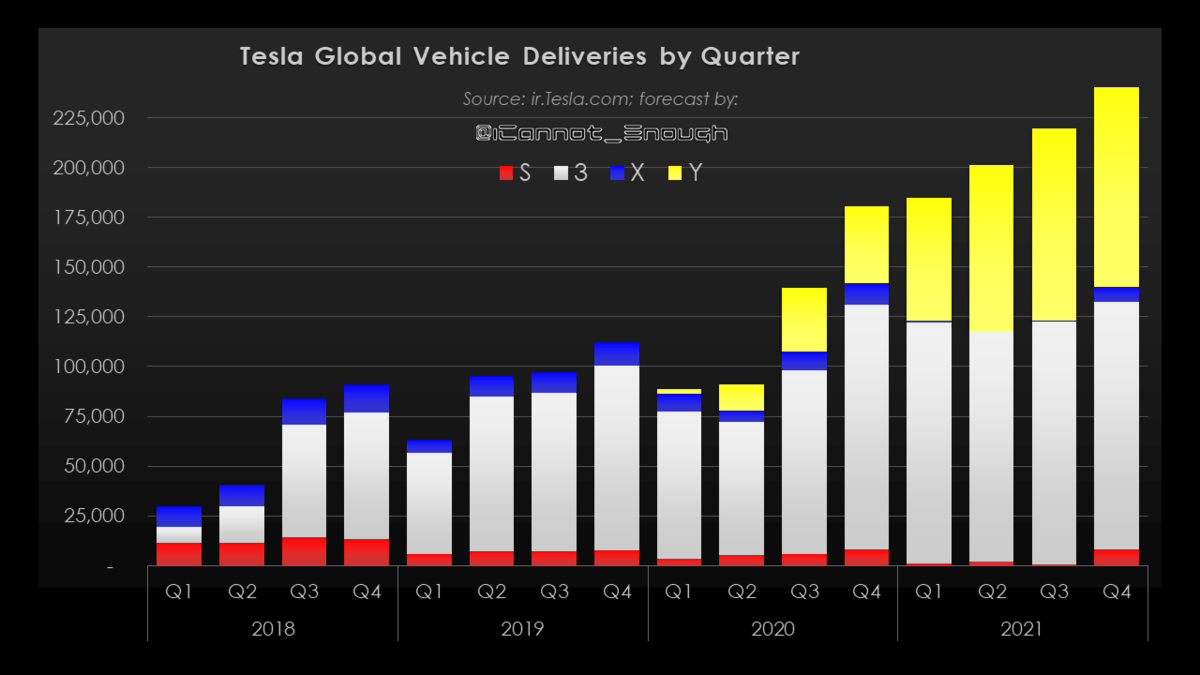
2021年は年間85万台生産いきそう。YoYで75%成長ペース。
4
https://twitter.com/ICannot_Enough/
5
https://twitter.com/ICannot_Enough/

生産台数の増加分ほとんどは、オースティンとベルリンからもたらされるであろう。
6
https://twitter.com/ICannot_Enough/
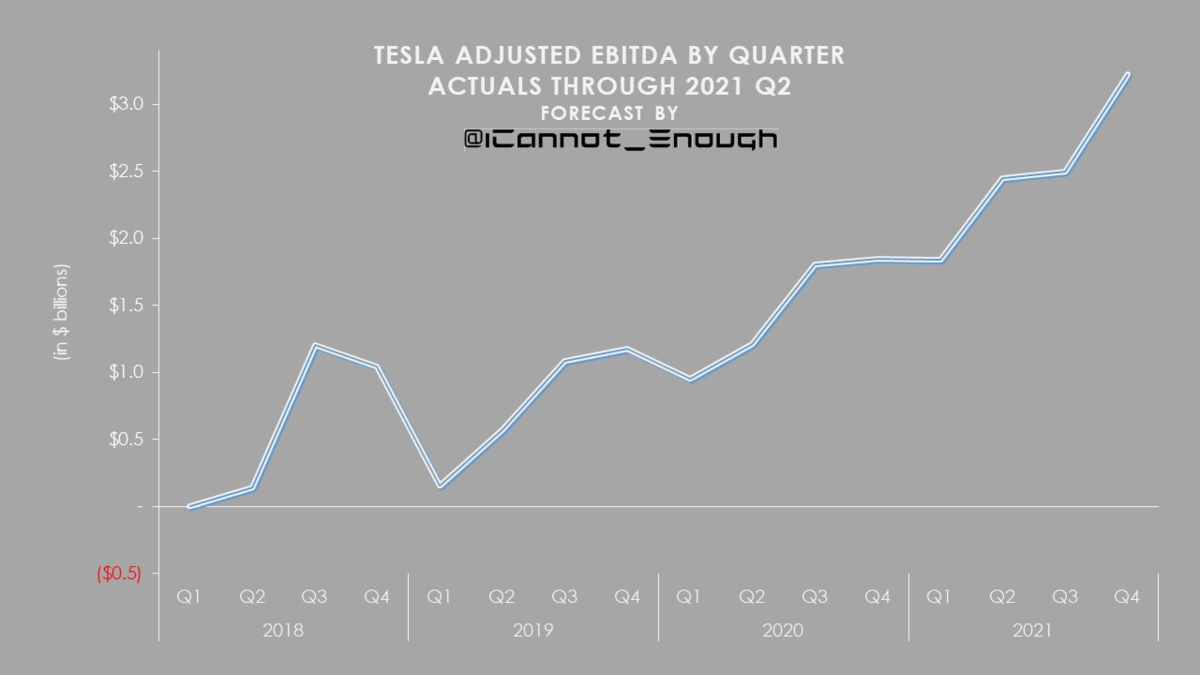
償却、株式ベース報酬に影響されない指標なので、企業の収益性を図る上で重要な指標
7
https://twitter.com/ICannot_Enough/
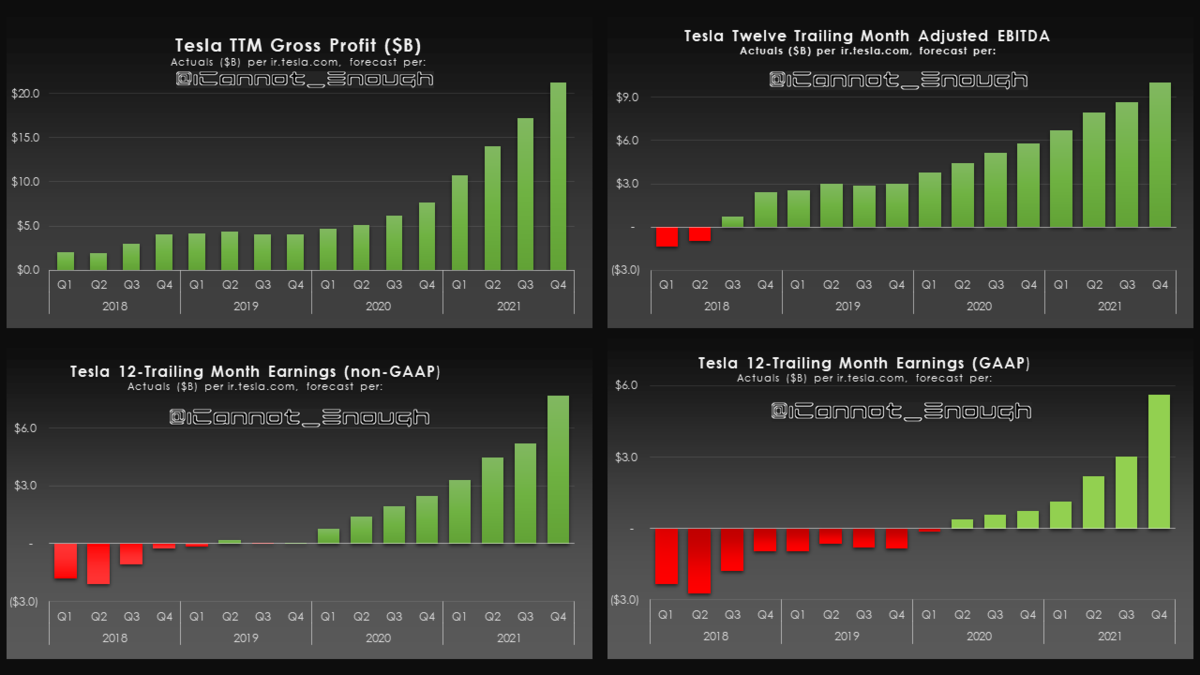
9

今後ますます排出権収入は縮小していくでしょう
10
https://twitter.com/ICannot_Enough/

This is a non-cash expense excluded from Adjusted EBITDA and Non-GAAP Earnings.
It will not exceed $2.283B ($1.784B of which has already hit) over the plan's 10-year life.
11
https://twitter.com/ICannot_Enough/

自動車部門の売上にエナジー部門が追い付いていない
12
https://twitter.com/ICannot_Enough/
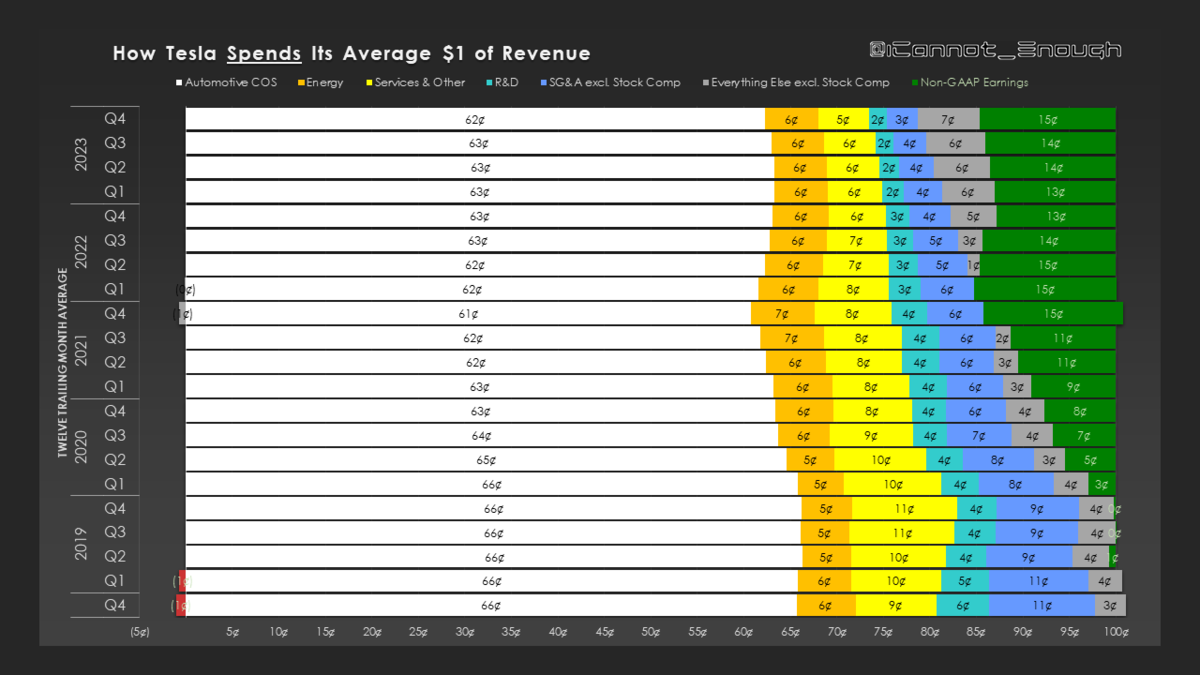
テスラが配当を支払うか、自社株買いする日も遠くはないでしょう
14
https://twitter.com/ICannot_Enough/
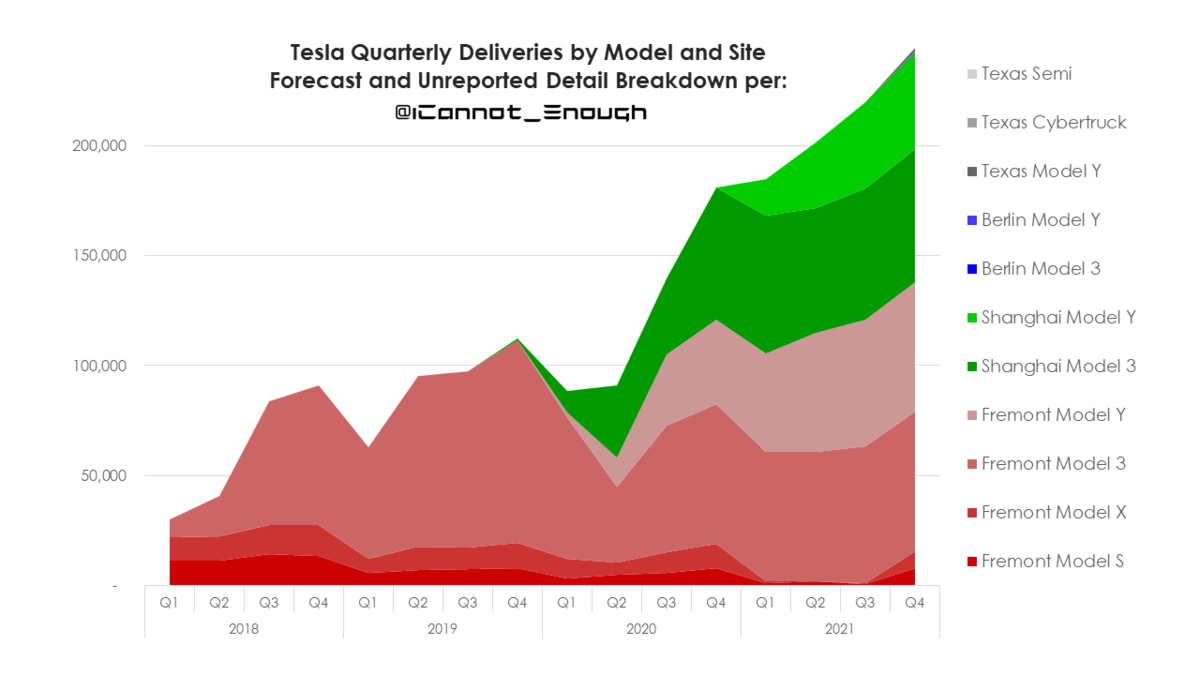
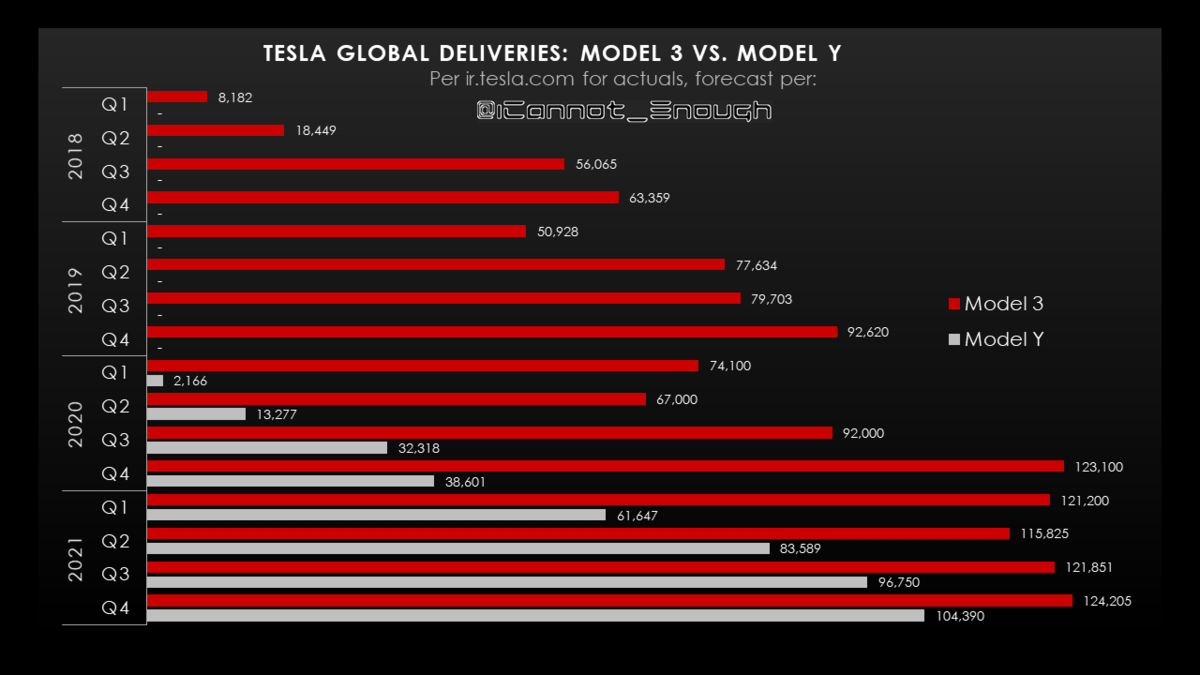
直近では、上海のモデルYの生産ペースがカギとなるね~
17
https://twitter.com/ICannot_Enough/
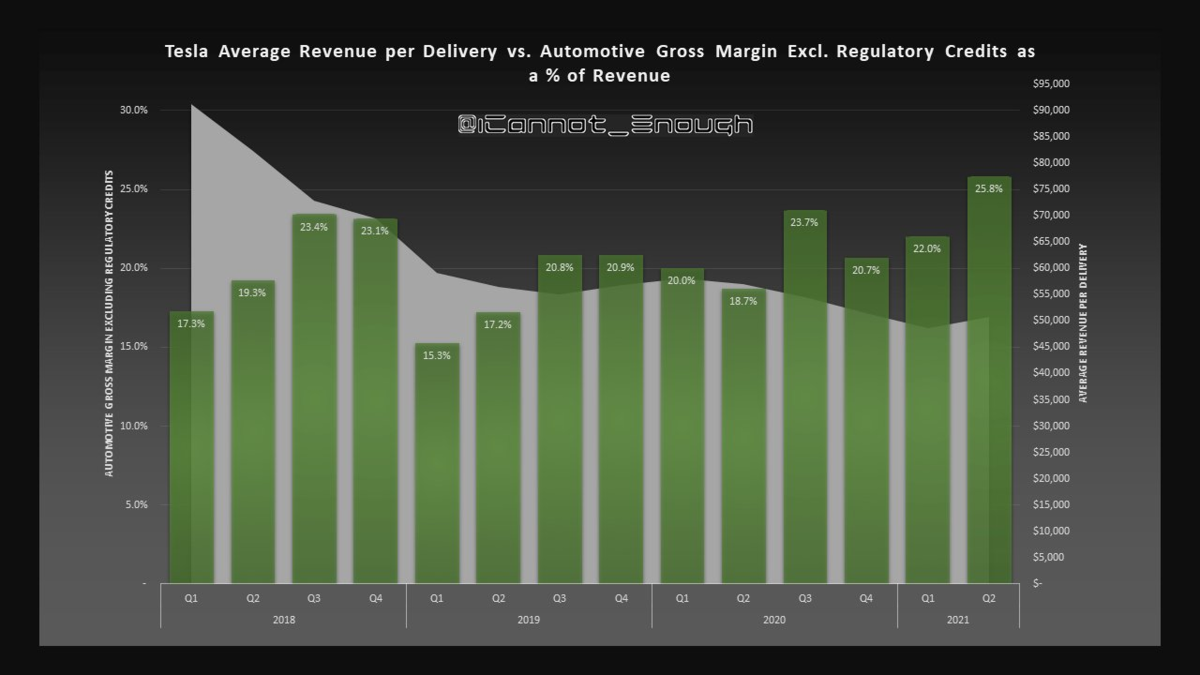
1台当たりの売上は、3とYの増加によって当然ながら減っているが、にもかかわらず、粗利益率は上昇している。どうしてなの?
この「マジック」は「ギガ上海の生産効率の上昇」によって達成されている
18
https://twitter.com/ICannot_Enough/

19
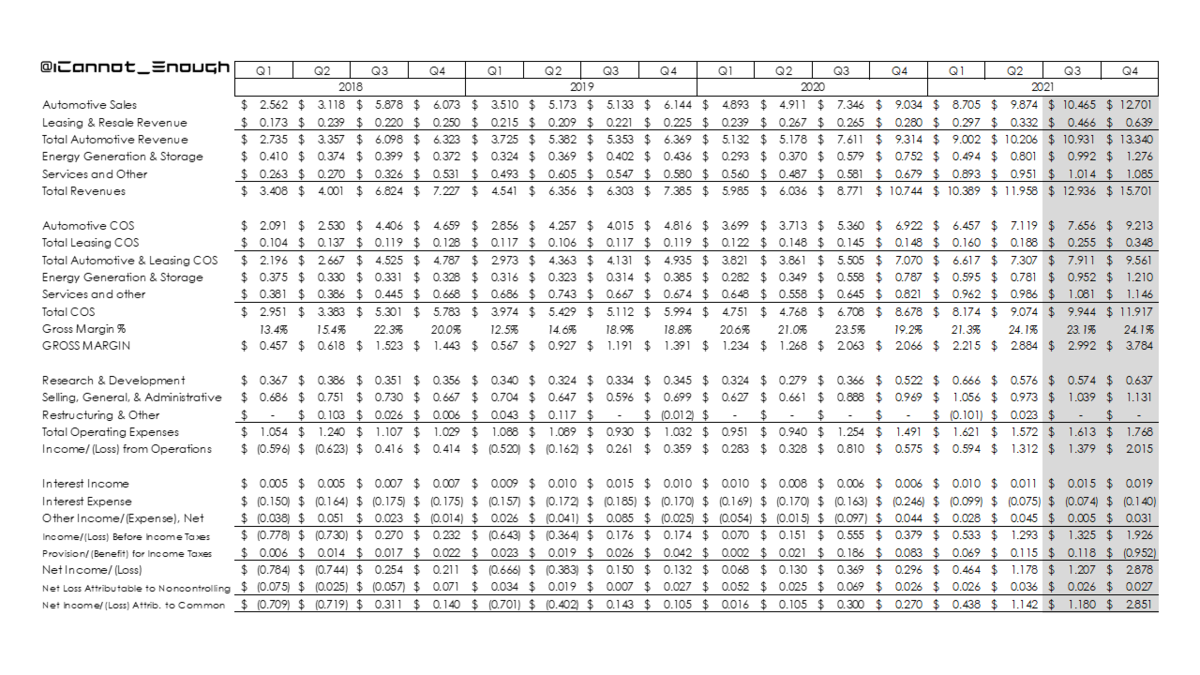
20
https://twitter.com/ICannot_Enough/
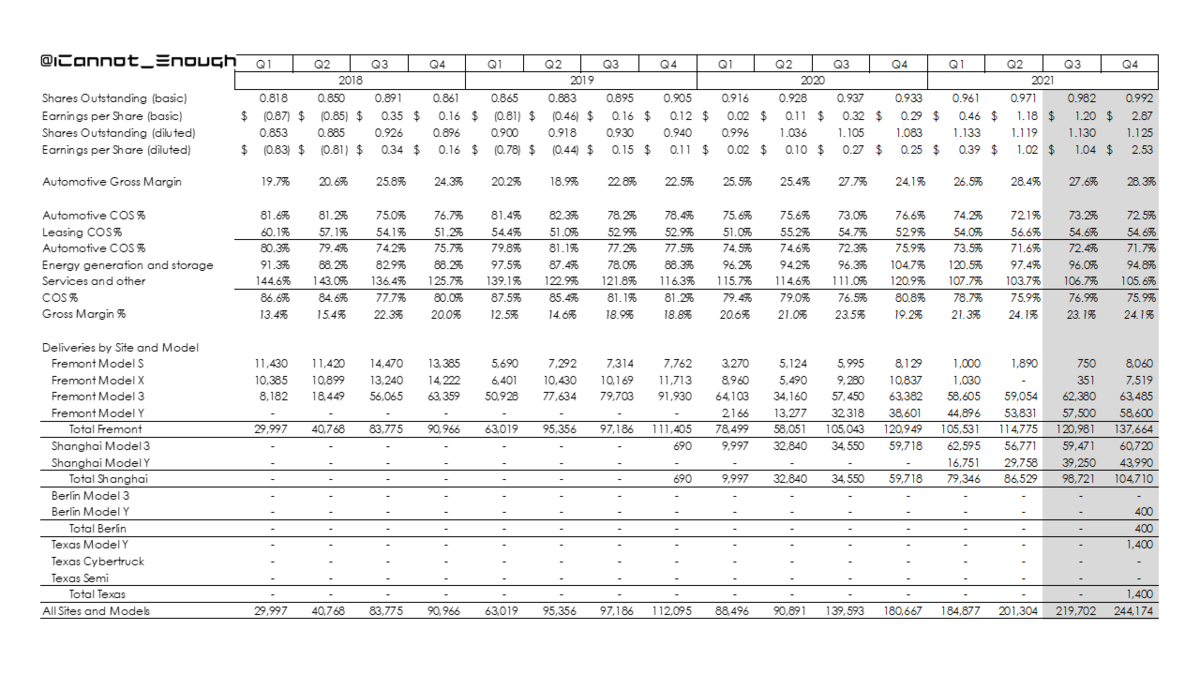
25
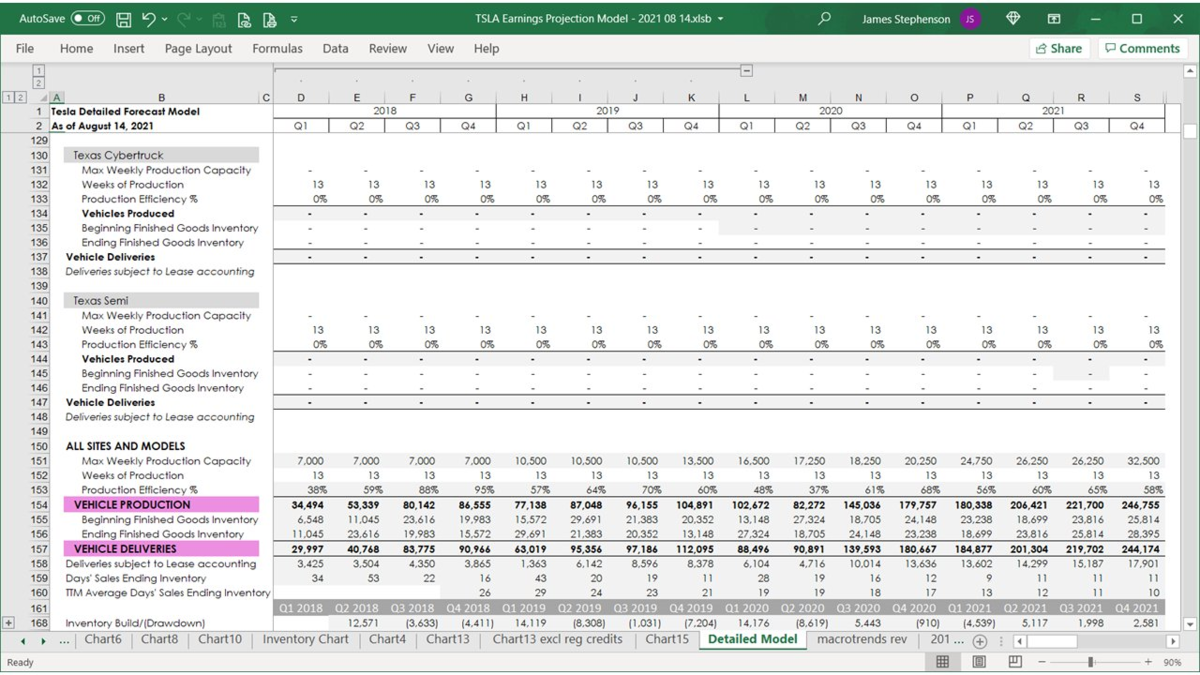
26
56

58
59
AIデー向けお勉強シリーズ③:ジェームス・ドウマさんその2
(Ep. 258)
テスラのAI担当であるアンドレア・カパーシーが2020年2月に、機械学習エンジニア向けのカンファレンス Scaled ML で行った講演の内容をもとに、ドウマさんが、テスラFSDの最近のイノベーションの一つであるBEVについて語ってくださっています。
この動画の視聴目的はBEVのアーケティクチャーの把握と、FSDへの影響を把握することです
BEVの設計自体は他の企業でも行えるでしょうが、使い物になるまでのプロセスには大きなチャレンジが待ち受けています。
バックボーン

BEVにデータが供給されるまでのアーキテクチャー
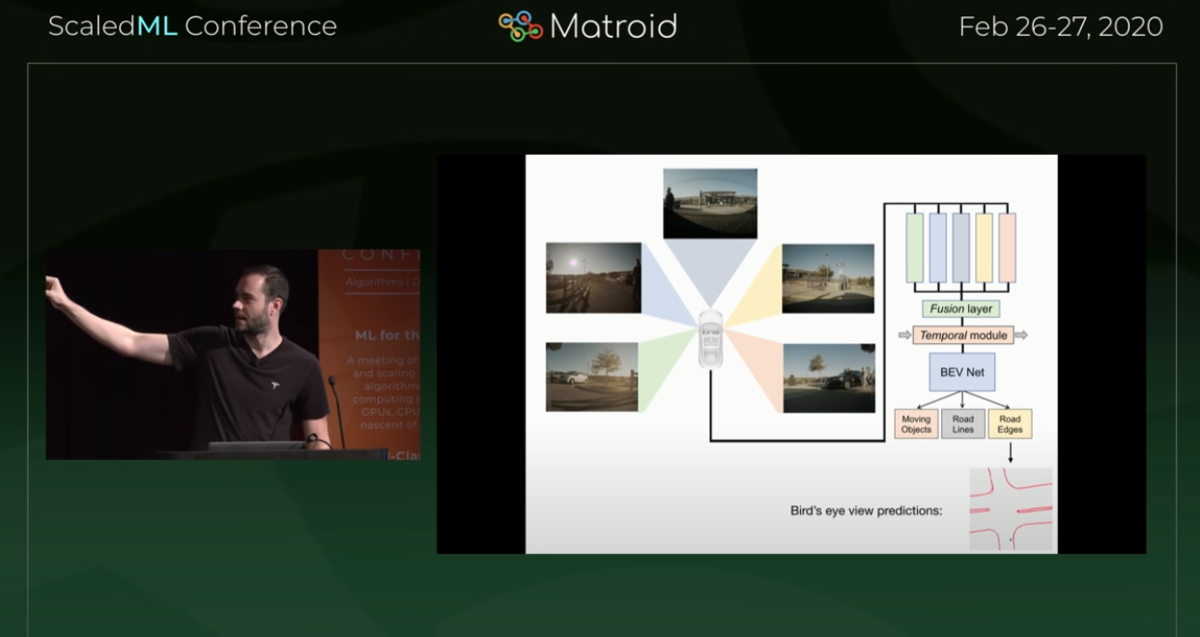
フュージョンの様子
スーペース・ディテクション

BEVを経由した場合のアウトプットデータ

個別のトピックは以下です
・機械学習エキスパート向けのリクルーティング講演
・バックボーン(個々のカメラネット)(図)
・個々のピクセルの関連性に基づいて処理
・演算のアウトプットを、モニター上の各カメラ画像に重ねて出力する
・動体検出
・道路上のライン検出
・道路のエッジの検出
・これらは車載用のNNによる検出
・8台のカメラ
・運転用に使用されるのは主に7台のカメラ
・フロントに3台、サイドに各2台ずつ
・メイン(通常→車2台分くらいの前方)
・フィッシュアイ(180度→サイドビューとの連携用)
・ナロー(90度のテレフォトビュー→200フィートくらいの前方)
・ピラー( 側面から前方)×2
・リピーター(フェンダーについてるやつ→後方用)×2
・後ろのライセンスプレート上に、リアビューカメラ
・APの初期バージョンでは、フロントの2つのカメラしか使っていなかった
・次にピラーの統合
・次にリピーターの統合
・この頃になるとAPは自動でレーンチェンジするようになっていた
・この2年で、サイドカメラの仕事量、使用量が増大
・すべのカメラにバックボーンNNが備わっている(図)
・フロントカメラには複数のバックボーン
・最新版では、動体検出、静体検出、道路ライン、道路エッジなどのメイン機能のために、それぞれ完全に独立したバックボーンが実装されている
・AP自体は現在でも、HD2 HD2.5 搭載車上でも機能している。
・ただしFSD用のNN大きさは、AP用の20倍もあるので、HD2.5上では実行できない
・もしかしたらHD2.5の上で走らせようとおもえば、実行自体はできるかもしれない
・以前はパースペクティブ・ビュー
・現在はBEV
・両者の違い
・a map of everything の生成 (ベクトル・スペース上での)
・パースペクティブ・ビュー上で、車はどこにあるのか?という質問を実行
・パースペクティブ・ビュー上でのキューボイドで、答えを返してきていた
・BEV上で、このBEVビューの中で車はどこにあるのか?という質問を実行
・100フィートか、200フィート上から見下ろしたとして(つまり高さを捨象して)、その視点のから見て、車の周囲の状況を記述しなさい、という質問をする
・その上で、車の位置、歩行者の位置、道路上の白線、縁石などをBEV上にプロジェクションさせる(パースペクティブ・ビュー上ではなくて)
・必要に応じて人間用インターフェース画面上にも表示させる
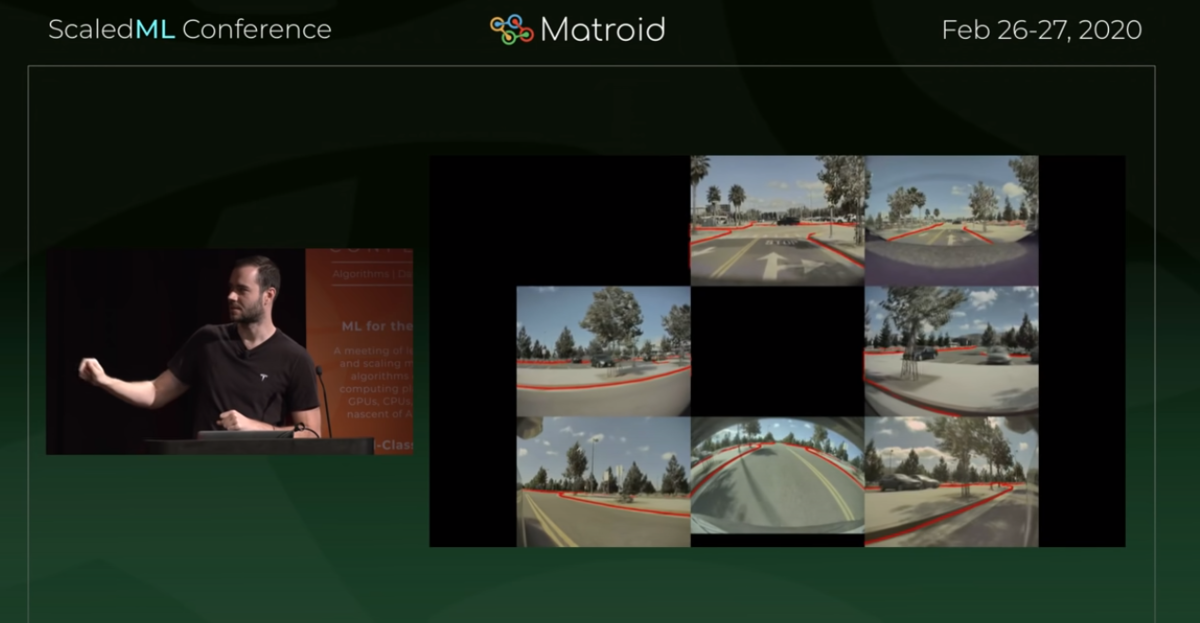
・パーキングロットでのスマートサモンにおける周囲状況の認識の劇的な改善(図)
・駐車場での自動運転は、ある意味で道路よりも難しい
・geometry、trigonometryアプローチは使い物にならなかった
・それらは画像認識の世界では、古典的なアプローチだった
・画像上のピクセル間の距離からの情報を、三角関数的なアルゴで、実際の距離に置き換えていたが、車両の近傍以外では上手に機能しなかった
・とりわけ水平線上の対象物の認識誤差は、ヒドかった
・geometryアプローチの放棄
・BEVの導入し、NNアプローチをメインの方法に据える
・劇的な改善
・グラウンド・トゥルースとその近似画像
・NNアプローチはすべてが新しい手法
・とりあえずの結果を出す(Demo out)のであれば、geometryアプローチで先ず始めるのは、自然なことだった
・フロントガラス自動ワイパー機能の度重なる改善
・テスラ車に、もはやレインセンサーは付いていない
・ジェネラル・デザイン・フィロソフィー 1.0と2.0
・複数の画像を統合して、統合画像を生成する
・各カメラ画像は、部分的に重なっている
・隣接したカメラと、エッジなどがコンシステントでなければならない
・スティッチアップ
・最低でも画像のローテ―ションが必要(temporal moduleにおける)
・それを並べると、時間経過を確認することができる
・1秒間前に見たものと、現在のものと、1秒後に見るもの、それらの間には高い確率的な連続性を想定できる
・時系列に並べた統合画像それ自体を、相互にチェックさせることができる。
・8フレームぐらいをローテーションして、相互チェックして、ベリフィケーションして、信頼性を高めている
・(ここでの議論に限れば)バックボーンは、もはや直接アウトプットを生成していない。そのアウトプットをフュージョン・レイヤー(ベクトル空間)へ供給している
・(ただそ。従来からの「バックボーンの演算データを、直接アウトプットへ供給」ルートが完全に消滅しているわけではない。)
・それを時間的な整合性もチェックしつつ、BEVにも投影
・信頼度のさらなる向上(図)
・ここでは、図より visceral difference (直感的な違い)を把握してほしい。
・アウトプットの目的対象が持つべきコンシステンシー
・テンポラル・モジュールによる時間的統合で、動体の存在のみならず、その動く方向、速度もより正確に認識できるようになった。
・アカデミアでは、BEV的なアプローチに関する論文は数年前から少しづつ出ていた
・アカデミアで論文が出た半年後くらいに、テスラからその成果を踏まえたその機能がリリースされることはよくある。
・(BEVアーケティクチャーを設計すること自体はテスラではなくても可能である。ただ学習のためのデータを集める方法にチャレンジがある)
・テスラは新しい機能を導入したとき、それまでの機能をすぐには捨てることはない。基本的には継ぎ足しで対応している。大まかなアーキテクチャーは、ほとんど温存してる。
・新しい機能の改善が十分に進み、もはや過去の機能を搭載することが意味をなさなくなるまで、そのままにしているのだろう。
・現在でもバックボーンは直接いくつかのアウトプットを供給している。
(FSD画面上ではBEVによるものか、バックボーンによるものかは識別できないはず。)
・このようなアプローチを数多くの機能で、同時進行で採用している
・BEVは二次元なので、高さがわからない。道路が極端に傾斜していたりするケースでは認識の難易度があがる。
・これはカメラビューレベルで対処しなければならない問題
・BEVによるアウトプットは、グランド・トゥルースの完璧な近似ではないが、FSDに必要な主要な特徴をすべて備えている
・FSDにおけるBEVの活用度合いの大幅な増加
・geometryアプローチのリファインメントよりも、BEVの導入の方が性能の飛躍をもたらした
・when you get these cameras to cross-correlate against each other and cross-correlate against time
・BEVでシングル・フレームから生成されるアウトプットの精度 と
BEVでタイム・コンポ―ネントを考慮して生成されるアウトプットの精度 を比べた場合
タイム・コンポーネントの方が必須度、優先度が高いだろう
・4Dでのトレーニング
・時間も考慮したフレーム群でのトレーニングが進めば、静止画像でのトレーニングはそれよりもたやすい
・オートノミー・デー(2019年4月)時点では、テスラはBEVについては言及しなかった
・おそらく2019年中頃からBEVの採用・開発を加速させていったのだろう
・NNコミュニティでは、時間的統合は昔から大きな課題だった。
・その有効性はだれもが認識していたが、実現する方法がわからなかった。
・(BEV空間へのプロジェクションを前提とした、スティッチアップとローテションの様々なノウハウに、時間的統合におけるイノベーション・ブレークスルーが詰め込まれているのであろう)
・BEVを経由する(という目的のために各カメラ画像から特徴を抽出していく)という方法でなくても、ブルート・フォース的に、パースペクティブ・ビュー上に直接オブジェクトをアウトプットさせるという方法もありえたかもしれない。
・過去の事例:グーグルのアニメーション空間の中での、別の視点の生成の実験
・一定の成果は残したが、訓練時間、計算コストの問題で現実的に採用できるソリューションとはならなかった
・small enough and sample efficient enough でなければならない
・例えば囲碁もブルート・フォース的に問題解決することはできない
・問題をある程度限定して、答えを出す
・解決すべき問題はコンピューテショナリーにトラクタブルでなければならない。
Tesla's Latest FSD Breakthrough: BEV Explained w/ James Douma (Ep. 258)
DAVE
so this is the most recent talk that Karpathy's done that has a decent amount of detail in it
and so that's why if what you are interested in understanding what's FSD beta
how is it different from what AP was before the non-FSD version and where is it going
what have they changed then this is like a good reference for that
you looked into from Tesla's full self-driving code
did that match up with some of the stuff that karpathy was talking about in his talk
DOUMA
i'm not really looking at code so much
i'm looking at the architecture of the NNs
we sort of figured out a way to figure out what the architecture of the NNs
that they some of the NNs
the ones that aree really big in the car
it's also possible to look at the code
it's a lot harder to interpret what's going on in the code and
that's a pretty significant undertaking
whereas at least for me having looked at a bunch of these things
just looking at the shape of the NN
it's kind of a fingerprint
you look at the shape of the NN and it gives you a pretty good idea
of what they're trying to do with this NN
because different NNs are for different objectives
they have different shapes
because we've got a few different snapshots
we saw the NNs a couple of years ago
we saw them a year ago and so we can look at the evolution and get an idea about
what's working for Tesla what's not
what they're experimenting with
DAVE
in karpathy’s talk he talked about Pseudo LiDAR image depth mapping and the overall architecture of Tesla FSD
DOUMA
the Karpathy in his talk he spends about the first half of it doing a general introduction to
what Tesla is doing like their development approach
for an audience the audience for this talk is people who know a lot about machine learning and who don't know very much about Tesla
so the first half he basically explains Tesla and your audience probably knows that part so i'd skip it
and then about halfway through he starts talking
and showing some examples of internal stuff that they're working on
that is recent developments in what they're doing and in particular i wanted to talk about things
that i thought were relevant to people's experience
and helping people understand what the NNs in AP are trying to do in particular
let's start with backbone here a minute
so this is a slide that shows one camera in the car conveys this
it takes an image that image gets a little bit of pre-processing
and then it feeds through the camera nets
and what karpathy here is describing as a backbone
and so this is basically a big NN
this just basically takes all these pixels
it processes them
looking at relationships between the pixels
according to the way that it's been trained
and then it squirts out a number of outputs
now he has three examples here
he shows moving objects
in this frame it's showing a box around a car
and then road lines and in this image
it's highlighting the lines in the center of the road markings
and then road edges
this output is the frame marked up showing where curve is here on the edge
these are examples of outputs
that a single backbone network on a single camera
might put out in the networks that are actually in the cars
we see anywhere from dozens to 100 of these outputs
depending on the camera obviously
the front camera side cameras they don't all look for exactly the same thing
they look for generally similar kinds of things
so that wasn't interesting
there's eight cameras
most of the driving is done with seven of the cameras
on the front of the car there are three cameras that look straight ahead
there's a fish eye which got almost 180 degree field of view
then there's what's called the main camera
which has about a 90 degree field of view it's a very recognizable field view
and they have narrow which is a telephoto view
it's looking well down the road narrow is interested in things that are a couple hundred feet down the road
main is interested in stuff that's close to the car within a couple of vehicle links
fisheye basically pulls in things from the side
if you're sitting in an intersection fisheye can also show you a certain amount to the left and to the right
so then there's four cameras on the sides of the car
there's two in the pillars that
basically look to the side and forward
then there's a set of repeater cameras which
repeater is the it's like a little turn signal indicator
that's on the front fender of the car on the side of it
so the Tesla's they have a camera that looks backwards
from each side of the car
so that's seven cameras
three to the front
and then two on each side there's another camera
which sits above the license plate and
when you back up your car it's the camera that shows you the rear view
the NNs are also capable of using that well
you don't tend to see the rear view camera used in a lot of the NNs
for instance the BEVs are they're totally dominated by the other seven cameras
DAVE
have you noticed over time Tesla incorporating more of the camera data views into their NNs
DOUMA
in early versions of AP
some years ago they were using like two of the front cameras for a really long time
and then they started incorporating the pillars
and then the repeaters came in
around the time
navigation on AP where it could start doing lane changes on its own
then it was really using all the cameras for the first time
really integrating everything
they've always done a lot of processing
on the front cameras
those are obviously really important to being able to drive the car
but the amount of work that they do on the side cameras
has increased a lot over the last 24 months or so
and so now all the cameras are basically have really big networks
and they're all doing a lot of processing but of course
there's three cameras to the front of the car
and some of the front cameras actually
have more than one backbone
they have multiple backbones that are specialized on different kinds of subsets
in this example Karpathy shows like
moving objects, road lines, and road edges
in the most recent version of networks
i saw they actually have completely different backbones for these big categories of objects
like they have a separate one
for moving objects
and a separate one for static stuff on the road and so on
DAVE
Is this more of a HD3 thing
where the old hardware just probably couldn't process fast enough all of the camera data
or did you see in the old hardware also used of all of the cameras
DOUMA
Navigation on AP was deployed before HD3 came out
but they're probably pretty close together in time
now that AP actually works fine on the older on the hardware 2.5 and hardware 2 versions of the car
but the amount of stuff that i see in FSD networks is way out of old hardware
it's 20 times too big to run on the hardware 2.5 processor
so they're definitely not running that on hardware 2.5
but the all of the functions that I saw in networks up until I started seeing FSD networks
it seemed like it was being scaled so that it could fit in hardware 2.5
so now Karpathy in this talk
he leads up to an explanation of the BEV networks and
using a NN how to develop this BEV
Tesla has recently gone to asking the car to give it a map of everything
asking a NN to generate a map of everything (Vector space they call it)
that's around the car in one field
and previously they had perspective views
if you ask to PVs "show me where the cars are"
and it would show you in the cameras field of view
like here's a car here's a car here's a car by putting boxes around those
the BEV it asks the network to take a step back
imagine you were looking at the car from 100 feet up or 200 feet up
and imagine all the area around the car
and then asking the network
tell me where the cars and the pedestrians and the road lines and the curbs are
in this view (vector space derived view)
one of the first places that this became really valuable to Tesla
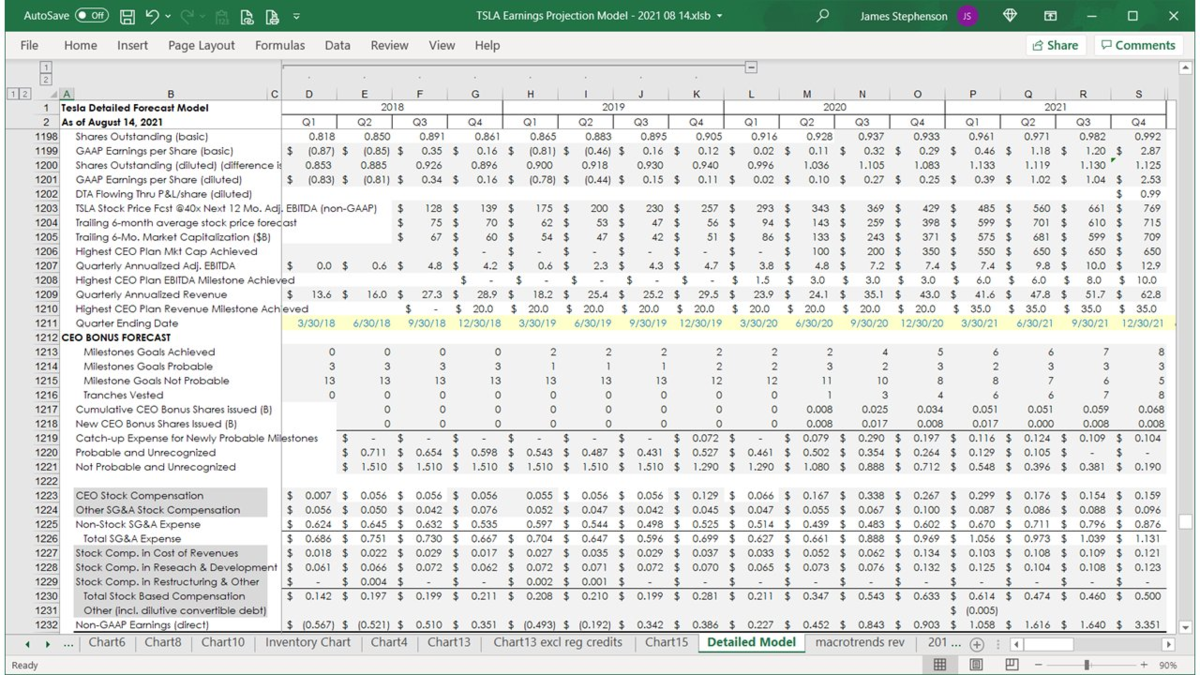
and a really good test bed for this is smart summon
so they have this advanced summon feature where you can
call the car to come to you from across a parking lot
in parking lots
it's really hard to tell
where the car is supposed to drive
they're not nearly as well delineated as driving on roads are
the car, the curbs can be in all of these complicated patterns
they wanted to do was
having the NN to tell me where is it safe to drive in the parking lot
and so he's talking in this section about how they tackled that problem
originally they had tackled that problem just with geometry
which is you have a camera and it's a projection onto the world
and you can use trigonometry to say
if i see the curb at this point in the picture (2D)
it must be at this position relative to the car in the real world
and they were using that to try to estimate
where the boundaries of
where it was safe to drive was
and they were getting that works pretty well
when you're really close to the car
but there's a lot of difference
if you look out the side of the car
it's pretty easy to tell when something is five feet from the car versus ten feet from the car
but when you're looking 40 feet from the car
and you're trying to tell if something is 40 versus 45 feet away
that's a lot harder to do
to understand that distance
the geometric approach wasn't doing it for them
when they switched using a NN for this BEV approach
they suddenly started getting much better results
so this is what the ground truth is
in other words this is what it would actually look like on a map
and then here's what the geometric thing was showing us and it looks terrible
then here's what the BEV NN was telling us and
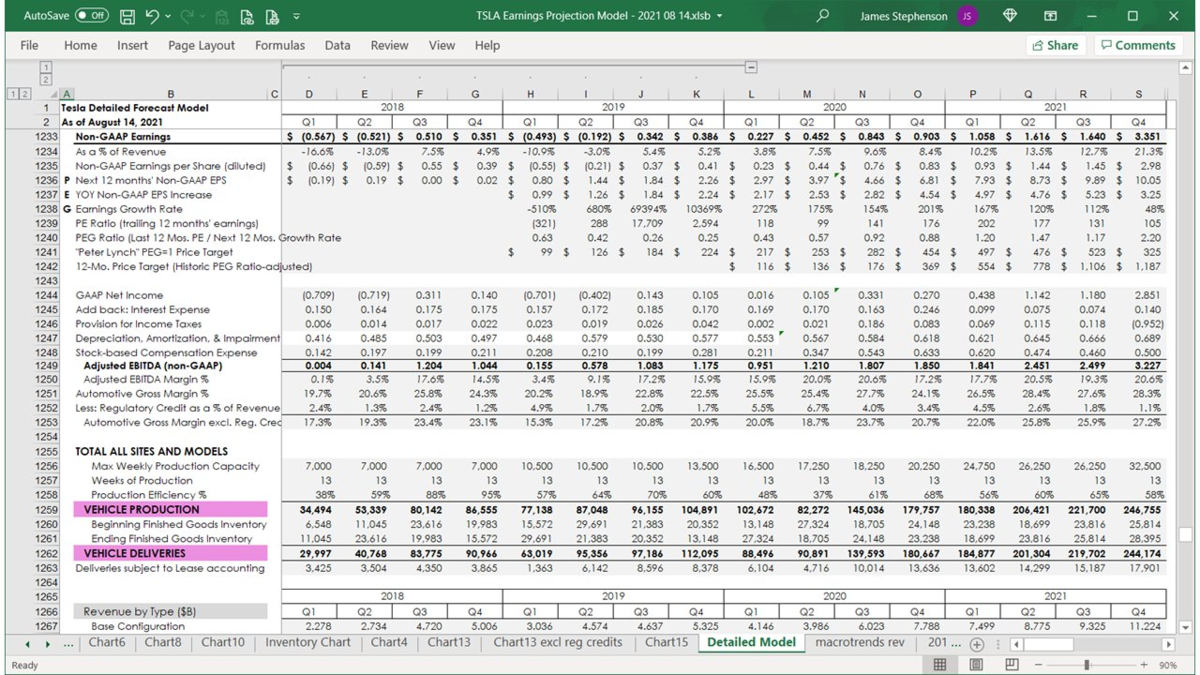
it's perfect it's like a really good match to the ground truth map
so you can see there what a leap forward it was
for them to step away from geometric approach to understanding the environment
having a NN take a bunch of camera views
and try to show what the world looks like
DAVE
when they were doing this a smart summon was the expectation that
a geometric approach, geometry approach would actually work
and then as they hit limitations
they're trying to explore other solutions with NNs
and so was this like on the fly adaptations
we're trying to solve this problem and
we're throwing different things at it
and then the NNs came out to be the winner
DOUMA
it's a little of both
i think their expectation is that
in the long run the NNs will win a lot of this stuff
but in the short run
NNs are new and the best way to use a NN to solve a problem can be not very obvious
and a lot of the geometric techniques are mature
they've been around for a really long time so
if they need to do something today
an approach they can take is
use a geometric approach to just get going
and then you start trying different things with the NN
to figure out what the right way to do it with a NN is
and looking at how the different NNs evolved over time
my favorites was the windshield wiper thing
because every time I saw a NN
the windshield(フロントガラス) wiper network it had radically transformed
like it wasn't this arc
where they started with this
and then they gradually moved in some direction
it went all over the place they did all kinds of things
trying to get the windshield wiper to work
that was an example of where they didn't think it was going to be that hard
when they started out and then it turned out to be surprisingly hard
and they had a whole bunch of experiments
and then eventually they found something that worked pretty well for them
and that's what they're doing now
he talks a little bit about their general design philosophy here
now when they tried to do the NN
how did they change stuff that was in the car
so now what they want to do to be able to use the NN to solve this problem
to understand the thing
you need to rotate the view at minimum
you need to be able asking the camera what would I see from above
in the field of view that you've got
then you want to put all the cameras together(fusion)
because no camera can see all the way around the car
and because the cameras really overlap a lot in their fields of view
they can act as a check on each other
and check overlapping parts
because each camera wants to see a consistent view
and its edge has to be consistent with the adjacent camera
the cameras all together end up being a good consistency check for all of them
so essentially when you try to put them all together and make it make sense
the accuracy of everything gets a lot better
so then another thing that you can do
once you've integrated all the cameras into a scene (virtual mono camera)
it should also make sense across time
there's continuity between what i saw a second ago
and what i see now
and what i will see a second from now
so another consistency check that all these things can do is
i do my top down BEV
and now i want to stitch several seconds of those together and
ask them to cross check each other and
then my accuracy goes up again
and this is what you see them doing here
he's just got an example of five cameras here
one from the front and four on the sides
and then this is what we were looking at before that was the backbone
now this time the backbone isn't making these outputs down directly
instead what the backbone is doing is
it's extracting all these features
and it's feeding them into another NN that takes the output from the individual camera networks
and it makes a unified view
the unified view combines all of them together
the next stage is the temporal one
where you look at several unified views over time
like maybe eight frames
so you take the last eight synthesized views that you have
and you ask them to all be consistent
so you have a network that that cross-checks all of those against each other
(Temporal module)
one side effect you get of time is
now you can see moving objects
if you see a car moving from frame to frame to frame
one of the things that this network can output is
not only it can just tell you there's a car there
but also it can tell you what direction it's moving and how fast it's moving
the last thing you do is you ask it to rotate the view
so that you're looking down on the car
now that you've integrated all this stuff together
both across space and across time now we rotate the view
and then in the rotated view
now we ask it all the things we were asking it before
where are the pedestrians
where are the road signs
where are the road markings
curbs and so forth
now in the rest of these examples
karpathy is using curbs in the summon as an example
for what they're doing
you would tend to see these benefits across all the different kinds of things
that they were trying to do
DAVE
this whole fusion of the different cameras into a BEV(vector space)
is this something you think that Tesla has pioneered with or
is this something that is growing more common with vision and NNs
DOUMA
Academics have been trying to do this for a little while
in the last couple of years
there has been several interesting papers out on BEV networks
my experience with looking at Tesla's networks is
i'll often look at the networks and i'll see some stuff going on
and then i'll go to the literature and i'll search for other people doing this
and i will frequently find that somebody just came out with a seminal paper on this topic
like six months or a year before Tesla did it
so they probably are innovating and
they're certainly adapting these ideas
typically what you see the research having been done on
is not exactly what Tesla wants to do
they'll be very similar
and this inspires Tesla to try something along those lines
and then they figure out how to adapt it to what they're trying to do
DAVE
you've got this fusion BEV and
then it seems Karpathy is saying that they're relying on this BEV
increasingly more over time to drive
how do you think they're managing these two views
meaning you have the old kind of forward-facing view
then you have this newer kind of BEV
when do you rely on the BEV versus when do you rely on the old forward-facing view
is there some type of switching going on or
do they have to match up or how does the logic work with that
DOUMA
AP's a product that's in development it has an arc
they do lots and lots of small revisions that they push out to the fleet
and for the most part what they do is they introduce new functionality
and then they gradually refine it over time
so we're at a point in time right now
where they still have all the outputs that they got from those backbone nets
that were on the original cameras
and they had a bunch of code that they developed
because they didn't used to have the BEV stuff
so they had some relatively mature functionality
that was using those capabilities
and they probably still have it in there
for instance you saw that
in the original backbone thing for instance
they have a moving object's output
like one of those would be cars
but identifying other vehicles that are on the road
is a big feature that these networks develop
so they had a function that was working reasonably well for quite a while
that they had developed to some level of refinement
now they bring in the BEV network approach(Vectpr space approach)
now the BEV network is answering the same question in a sense
but what you don't see is Tesla immediately throwing away the old way of doing it
and moving to the new one
because in the beginning the old one is going to be pretty competitive
because it's fairly refined and the new one is going to have some bugs
and it's going to have some accuracy limitations
as you use the new one more
it's going to get better
and once it gets good enough that the old one isn't really adding value anymore
then you can drop it
and so a lot of features end up being doing this thing
where you had the version that you were doing
before you come out with the new one
and gradually this new one gets better and better and better
and eventually "okay we don't need to waste our time on this anymore"
and then it comes out
and they're simultaneously doing this with a lot of different functions
at any given point in time
so every snapshot you see some things that are have been thrown away
some things that are brand new and being tried out
and some things are in a transition in between
that's what we're seeing right now with BEV nets
BEV nets are showing their success
at being able to do this and so they're doing more and more things with the BEV nets
they're adding more BEV nets and they're pulling more of the value out
i haven't yet seen them deprecate old stuff
but that's would be a function of when the BEV nets were doing it so well that you didn't need it anymore
there will be some things
that the BEV nets won't be good at doing
like they can't tell you how tall a bridge is that you're coming up on
there's some things that just require that vertical point of view
and there will be other things too
for instance in the BEV net
you can't tell the slope of the ground
so if you're driving around a curve and
the road is banked or counter banked
you don't see that in the BEV net
so that's something you always have to do in the camera view(2D)
we talked about the architecture here
they have
the backbones
they feed into a fusion layer
they make it sense across time
then they do the top down view, the BEV view
now they're pulling the objects out
so this is where Karpathy is showing the success of this method
in the specific case of predicting where curbs and parking lots are
this is the ground truth
so you got a map of the parking lot
which maybe you pre-mapped it or maybe you got this from google
this is what the geometry is telling them about where the curbs are
so you can see this is where the car is
it's this blue dot
and the stuff that's nearby it's not too bad
it's useful within one or two car links
you can tell what you don't want to run into
but it's not very helpful
not very good at helping you understand the shape of this intersection that you're coming to
and not very good at like what your options are for navigating it
because as you get farther away from the car
things get closer to the horizon line
the uncertainty of the positioning gets to be really large
and then this is the output of the NN(BEV=Vector space) and
while you can see that the NN is not a perfect representation of the ground truth
it's got all the important features
and this was a fairly early version of the BEV net
that they had developed in particular for summon
what i see in the FSD version of the BEV networks that i was looking at
was lots and lots of this BEV net getting used
they're using BEV nets everywhere
what i wanted to try to give you here was a sense of the visceral difference in the two
imagine this
if you're here in this car
and you're trying to decide okay i want to make a left turn
what do i need to do over the next five seconds
you look at this it's not too tough
i need to turn wide enough to miss this curb
and i want to end up going about this way
if you go over to this ( geometry ) scene and you try to answer that question
this is almost not useful
in other words the level of uncertainty that you get
just trying to predict these things from the camera views themselves
is large enough that you just can't even make sense of the shape of the network
so this is the basic what you get with that basic geometric approach
now you could refine this
you could keep working on the basic geometric approach
and you could get better at it by putting things in
but when they took the problem away from geometry and
they gave it to a BEV network and they told it
the constraints are like
whatever one camera sees has to make sense for another camera
these objects, this space needs to be continuous and make sense
and as you move through the scene it needs to be continuous and make sense
when you get these cameras to cross-correlate against each other
and cross-correlate against time
all of a sudden your accuracy gets dramatically better
and in this case you can see the differences
basically this center image might not be perfect but it's usable
they went from something that was totally unusable
which they'd worked on a long time they had summon working in parking lots for a while
before they went to the BEV nets
DAVE
so that BEV view in the middle
looks like almost exactly the same as the ground truth
how much of that is based upon using the BEV net over time
over a few seconds versus
just like let's say a standstill frame
are they able to get that type of accuracy with just a single frame
or is that because they're able to see it over a few seconds time
DOUMA
so there are two components to that question
say the car wasn't moving
you turn on the car
it's sitting in one spot
it looks out
what is it going to see at this intersection
so you haven't had any motion
it's probably not going to be as good as this but it's not going to be bad
when you are stopped at an intersection
you don't get to use the time component nearly as much of orienting yourself in the world
but it does add some value
it's going to make the network more accurate
when the car drives through a scene and it sees a curb move
from the distance into the foreground and slide past
that has to have a kind of consistency to it
in how it moves through
it shouldn't jerk
it should keep track with the motion of the car
so relying on that motion consistency does allow AP to make a bet
to be a better judge at any moment in time
where that curb is or that object actually is
but the place that really has a benefit is
when you train these things
as soon as you start training that temporal layer
your training material has to have time in it
so this is when Elon was talking about training in 4D
the 3D is including the BEV the top down look
we know where all these objects are in space
and we're testing against that
and the 4D is time
where we start stitching these frames together
that predicting the time dimension for the NN is really hard
and when it gets good at that
it's really good at the static frames
DAVE
autonomy day in 2019
did they mention BEV much at all
at that presentation because we fast forward to February of 2020
andre Karpathy’s scaled ml and
he's basically saying hey this is the big thing
we're building a lot of this stuff on
but on autonomy day did they have that type of conviction
back then or is it something you think
in between that today
DOUMA
They didn't talk about it at autonomy day for sure
I don't think they talked about it
that the literature doesn't seem to have used this terminology
much before a couple of years ago
but so Tesla obviously had done a significant amount of internal development of this
by February of 2020
so they must have started working on it
in some capacity around mid-2019 or something
and it was around mid-2018 that this started becoming a popular topic out
in fact in 2019 you do see a bunch of papers come out so
they probably knew generally that they wanted autonomous car
NN circles you can go way back and people knew that
if you integrated time
it was going to be super valuable
they just didn't know how to do it
what's the right way to do it and
they've known for a long time that
if you integrated multiple cameras together
that was going to be really valuable
because there's a way the NNs can cross check themselves
the camera NNs and you have to bring all this stuff together
and make it make sense
it challenges all the networks to get a lot better and
once they all get a lot better
then the unified view starts to get really good
we've known for a long time that
this needed to happen
it just wasn't clear what the right way to do it
there are these brute force approaches that you can take
where it's definitely got all the inputs it needs
you just put a giant NN on it
and you just process it and you train everything against everything else
and google did some early experiments several years ago
getting a huge cloud of computers
and asking them to do this really hard thing
proved that certain things were possible but they weren't practical on that scale
because you need billions of hours of training
so to make it useful in the real world
you want to figure out what do I not need to look at
what is essential to helping the NN understand this thing
that needs to understand to do a good job of this
and what's not important
and so you gradually whittle away all the things you don't have to do
and you get a NN that's small enough and sample efficient enough
is like how much data does it take to train this function
it's got to be a reasonable number and
how much computation does it take
that's going to be reasonable
we can use a big data center
but we can't use a thousand big data centers
there are limits
it's like the trying to brute force the game of go
it seems pretty small it's a 19 by 19 board but
they're more go positions than our atoms in the universe
i forget like dozens of orders of magnitude
there are problems that don't seem very hard
but you simply can't brute force them
you have to constrain the problem a certain amount
before it starts to be tractable
that was one of the problems and it continues to be a problem
with this whole getting a computer to understand that the world is 3D
brute forcing that problem has been intractable
google did a couple of really interesting things
some guys at google brain did some really interesting things
where they just brute force
they've made a little cartoon world
they really dumbed it down
which still has spheres and cones
and they wanted to train NN
and you would show it one view of the world
and you would ask it
what would it look like from this other angle
where you would give it an arbitrary angle
and the amazing thing was they got it to work
it took a significant amount of computation and it was very brute force
but they showed that the NN will eventually figure that stuff out if the information is there
but the approach that they took
nobody tried to duplicate that in any product
because it just takes too much data
and the world has to be too simple for it to work
so where's the good middle ground
where it's computationally tractable
it's a reasonable size NN and a reasonable size amount of data and training time
but it works in the real world
it deals with all of the complexity of the of the real world
and that's been the challenge
it's just been in the last couple of years
that people have come up with techniques
where this started to produce results
that were significantly better than what we could do before
for a long time they've been able to muddle along
but why do this super complicated technique
that isn't getting you better results
and now they're doing these complicated techniques
that are getting dramatically better results
and that's one of the things you see in this slide
you can see there's a dramatic difference between
what they were getting with the geometric technique that was a dominant approach before
and what they're getting now
and once again you look at the ground truth
it's not perfect but it's a pretty good facsimile of that
and it's a dramatic improvement over what they had before
AIデー向けお勉強シリーズ② ジェームス・ドウマさん(機械学習エキスパート)
ジェームス・ドウマさんです。
オートパイロットの初期バージョンから、FSDのいくつかのバージョンに至るまで、中身をハッキングして機械学習の観点から語れる人は、社外ではこの人以外に存在しないでしょう。
この2人の対談動画は16本もあります。
重複があるとはいえ、すべて中身がパンパンに詰まってる動画なので、一筋縄ではいきません。
この動画の視聴目的は
バーズ・アイ・ビュー・ネットワーク(BEV-net)(鳥観図ネットワーク )
のある程度のイメージをつかむことです。
BEV-netはテスラ車に実際に搭載される推論用NNにおいて、カギとなる存在です。
車両の個々のカメラに実装されているNN
それらをフュージョンしたNN(BEVの1機能)
テスラ社内の開発環境としてのBEV
など、車両レベルで起こっていることと、企業内、データセンターで起こっていることを分けて整理しないと混乱しがちです。
それにしても DOUMA さんなんで日本語しゃべれるのだろう…
この対談の個別トピックは以下です。
・APにおけるステディな改善
・テスラ流のNNへのアプローチ
・NNの巨大化していく様子
・カメラごとのビジョン・NNネットワーク(バックボーン)
・目的変数(従属変数)の大幅な増加
・画面上でのアウトプットの大幅な増加
・アウトプットに基づいて実行されるドライビング・ロジック
・ドライビング・ロジック=コントロール・コード
・カメラの生データに対して、NNが行っている処理
・NNによるパーセプション
・3つのステップ
・パーセプション
・プランニング
・コントロール
・コントロール用プログラムは人間が書く
・プランニングは、人間が書いたコードとNNが生成したコードのミックス
・プランニングは意思決定を含む
・FSDに表示される黄色のsplineはプランニング機能を示している
・プランニングはセンシング(パーセプション)の次の段階
・車両レベルでのNN推論の大部分はパーセプションに費やされている
・車両レベルでのNN推論は、外部環境の理解・知覚が大部分
・目的変数の増大
・目的変数の細分化
・問題ごとに常に新しい機能を開発
・FSD導入時点における飛躍
・NNが巨大化するということは、インプットデータにたいし、より多くの処理を行っているということ
・NNの大規模化は目的変数の増加を可能にする
・大規模化により、通常は出力データの精度(アキュラシー)が増す
・出力データの正確性は確率的に測定されたもの
・目的変数の確率が100%に近づくほど、人間はコントロール・コードが書きやすくなる
・コントロールコードにとっては、確率が100%に近いほど望ましい
・かつては一つのカメラに一つのNN
・NVIDIA GP106を使っていた頃の制約
・現在は一つのカメラに複数のNN
・信号停止時、高速走行時など複数のシチュエーションで、それぞれに応じた推論用のNNを切り替えているはず
・動的オプジェクト知覚NN
・静止オブジェクト知覚NN
・専門化された複数のNNも同時に実行されている
・カメラから見て、道路を基準として、それとの相対で動的か静的かを判断
・HD3によって、NNの数を劇的に増やすことが可能となった
・フュージョン・アーケティクチャーの説明
・個々のカメラレベルでの実行とフュージョンレベルでの実行
・個々のカメラNNによって2種類の出力データが生成
・フュージョン・ネット=コモン・ネット
・コモン・ネットワークへ向けてののデータ出力
・コモン・ネットワークによるフュージョン
・そのフューズド・データは、バーズ・アイ・ビュー・ネットワーク(BEV-Net)へ
・フュージョン→ローテーション(テンポラル)→BEV
・BEVはある種の「想像力」を獲得している
・想像力を獲得しているかのような質問を、BEV に投げることができる
・質問を可能にするプラットフォームとしてのBEV
・単純なカメNNは、見えないものを知覚することはできない
・BEVに与えられた2つの役割
・シンセサイズ
・見えないものの存在をguessすること(seeではなくguess)
・FSDでもそれが実行されている様子を見ることができる
・FSDで見えないものをguessしている様子
・BEVは時間の推移も考慮することができる
・各画像を大きなシングル・フレームに統合し、それらを並べることで時系列による分析が可能となった、それをBEVへプロジェクションする
・ハッカーコミュニティの解析結果とアンドレア・カパーシーがSCALED ML で語った内容はほぼコンシステント
・NNの大規模化→BEVにおけるトップダウンビュー関連の機能開発→時間的統合
・BEVの持つ2つの役割の言い換え
・1、 各カメラ画像のリコンシリエーション
→a way of asking the car to reconcile all the different cameras
・マシンへの命令はスペシフィックでなければならない
・マシンが答えを生成できる環境と形式を用意して、マシンに質問する
・(暫定的な)グラウンド・トゥルースの決定 → 損失関数を供給できる
・誤差情報のフィードバック → ネットワークの改善
・2、BEVのもう一つの役割→domain easy to write code or software in
・NNとプログラマーが対話するプラットフォームとしてのBEV
・各カメラ画像をBEVではなく、3D空間へプロジェクションするという方法もありえたはず(車両レベルで)
・BEV空間へのプロジェクションではなくて
・しかし、3D空間への直接のプロジェクションは難易度が高い
・NNに、直接に、世界は3Dだと理解させる方法は、多くの複雑な処理を必要とする
・NNはブランク・スレート
・NNはすべてのアウトプットを、入力データのみから生み出さなければならない
・欲しいのは現実の詳細なモデルではなく、あくまでシンプルでパワフルな、現実のレプリゼンテーションが欲しい
・BEV空間へのプロジェクションで、カメラと物体の位置関係を、NNに認識させることは可能である
・3D空間へのプロジェクションよりも、BEV空間へのプロジェクションの方がシンプルであり、FSDの目的のためにはその方が相応しい
・BEVへのプロジェクションは、現実空間におけるheightやvolumeをある程度捨象している
・(乱暴に言えば「背が高い物体だろうが、低い物体だろうが、車両とぶつかっちゃいけないことには変わりないのだから、高さが同じキューボイドに放り込んでしまえ」「ぶつからないために重要なのは、幅と奥行きであり、高さではない」ということ)
・以前と違ってコードを直接クラッキングすることは非常に難しくなっているので、アウトプットからNNアーキテクチャーを推測するしかなくなっているが、いくつかの方法はある
・BEVへの信頼度の増加
・テスラは過去のNNを捨てているわけではない
・徐々に過去のNNを改良しつつ新規のNNを追加していく
・プランニングのコードを書いていたプログラマーが、BEVを追加する過程においても、過去のNNやそのアウトプットはそのままにしておいて、BEVをインテグレートしていった
・the field of view or POV(BEV以前のやり方)
・BEVによって2Dだったものが疑似3Dに
・疑似3Dを並べることにより、時間性考慮した疑似4Dに
・ラベリングの必要性
・テスラもマップを使わないわけではない
・ただしそれはHD3Dマップである必要はない
・Accelerometers:加速度計
・1,ラベリングとその後の学習プロセスの大幅な自動化
・2,self-supervised training
・DOJOでNNアプローチが必要だとは限らない
・DOJO内部で3Dシーンモデルを構築する際にgeometric priors、geometric analysisで十分な場合もある
・まずは構築された3Dシーンの中で、人間が手動でラベリングしていく
・DOJOが構築した3Dシーンモデルの中で、その原ラベリングに基づき、プログラムが自動でラベリングを生成していく
・そのラベリング生成と、精度向上のの過程における学習において、NNを使うことは十分にありうる
・ラベリングは個別のカメラビューNN向けのラベリング、BEV向けのラベリングなど様々な用途が考えられる
・DOJOの中では、時間も含めて構築した3D空間の中で自由に往来ができる
・DOJOで鍛えたNNをフリートで展開して試す
・2,もう一つのDOJOでのトレーニング方法→ self-supervised training
・これにより「あるカメラからのシーンは、他のカメラからとらえた場合どのように見えるか?」を問える
・カメラ同士のそれぞれの視点からの「推論同士の誤差」が、エラー・ファンクションとなり、学習を推進できる
・カメラの視点はオーバーラップしているから
・もしくはDOJO内部では、この1フレーム後のシーンはどのようなものか、現在までのフレームに基づいて予測せよ、という問いを投げかけることができる
・DOJOにはすでに時系列3Dデータが取り込まれているので、問いの答え合わせができる
・DOJOで生成された3Dデータのアウトプットは、BEVでも利用できる
・より高い正確性のためには、more nuanced understanding of environmentが必要
・都会の走行では、通行人のボディーランゲージ、ポーズ、モーションさえも理解する必要がある
・膨大なコンピューター演算を可能にするためのDOJO
・ただしそれはFSD向けの演算に特化したシステム
・通常はコンピューターは想像力を持たない
・画像フレームの中に存在しないものを想像することはできない
・DOJOの4D空間の中で、あたかもNNが想像力を持っているかのような質問をすることができる
・「つい先ほどまで見えていて、現在は道端に停車しているバスの後ろに隠れているだろう歩行者を想像してください」
・バスに隠れているその歩行者をラベリングするためのフレームは存在しない。だって隠れていて見えないのだから
・バスに隠れる前ののフレームと、バスから出てきた後のフレームなら存在する
・FSDにおける想像力 (FSDで「想像」自体はかなりの程度まで実現されている)
・DOJOがその想像力の飛躍を可能にする
・場面ごとの予測は現在のFSDでも行われている
・交差点に差し掛かった時、自転車が近づいて来ているか、その自転車が道端で止まっているかどうかで、車両の挙動は明らかに違う
・聖杯としてのビデオ・オート・ラベリング
・DOJOでも最初は人間によるラベリングが必要であろう
・その後DOJOが自分でラベルを生成できるようになれば、人間の仕事はそのラベリングのベリフィケーションとなるだろう
・やがてそのベリフィケーションすらいらなくなるだろう
・DOJOは完璧な未来「予測」はできるが、現実に走行しているフリートは「推論」しかできない
・what three-dimensional dynamic model of that scene is most consistent with all the sensors saw all the way through the scene from beginning to end
→DOJOにはこれがわかる(アタリマエ)
・このグランド・トゥルースに基づいて、NNをトレーニングすることができる
・人を上回る推論能力をNNに持たせることが目標
・DOJOはトレーニングの主体ではなく、あくまでNNをその内部でトレーニングさせるための環境
・DOJO内部に構成されるのは、カメラからのインプットデータのみから構成された、時系列を持った3D空間であり、NNのトレーニングのために最適化されている
・現在のDOJOの進捗度
・DOJOインフラの、ハード&ソフトを構築している段階か?
・NNはセオリー・ドリブンではなく、エンピリカル・ドリブン
・NNのアウトプットを実験前から正確に予測することはできない
・DOJOのプロトタイプはすでに完成済みで、そこでの実験も行われていることだろう
・テスラがラベリングのために独自で開発しているツール群も、数千もの特徴を備えたものであろうし、それにより、ラベリング要員の生産性の向上に役立っていることだろうが、それは進行中のプロセスだ
・FSDはここまでで完成!といったプロダクトではなく、常にバージョンアップされ続けていくものだ
・テスラと同規模でテスラと同じ試みをしている企業は存在しない
・ラベリングツールを開発している企業も数多くあるが、テスラほどの規模に対応できるものはないだろう
・テスラはほぼすべてのラベリングツールを自社で開発しているはず、データ規模が大きすぎて、既存のラベリングツールでは対応できないからだ
・おそらくDOJO向けチップのファーストカットは完成させているだろう
・チップが完成しても課題は多い
・電源デザイン、冷却デザイン、コミュニケーションデザインなど大規模データセンターを構築するのは全く別の課題だ
・ただチップを完成させていれば、それを既存のデータセンターの枠組みの中で、ある程度の規模で運用することはできる
・しかしそれはDOJOと呼べるものではないだろう。
・DOJOの大規模運用が開始されたときには、NN計算コストが劇的に低下していくことだろう
・(Lidarに関しても多少議論されている)
Revealed: Inside Tesla's FSD Neural Nets w/ James Douma (Ep. 255)
DOUMA
the first version of the first Autopilot had a lot more code and very little in the way of NNs in it and over time that has expanded
over the last couple years I’ve seen little snapshots of the NN architectures
looked at what's the state-of-the-art for this particular architecture
like what are they able to achieve with a certain size network
What Tesla is doing is different from what researchers are doing with these network
so from the beginning I was looking at them from that standpoint
and up until FSD beta came out there's a pretty solid steady evolution we could see
the networks they would get bigger occasionally
they would change the structure of the way they were doing
the inputs
the system itself
you can think of it a couple different ways
one way of thinking about it is that
they have a vision network on each camera
what that vision network does is
it takes the video stream coming in from the camera
and it analyzes it
and then it produces a bunch of outputs for each camera
and the outputs might be
where are the stop signs in this frame
or where are the pedestrians in this frame
or where are the cars
or how far away are the cars that you can see
where are the stop lines
where are the markings
where are the curves
so a single NN they started out with a small number of variables
but over time as it's become more sophisticated
the number of variables that they get out of each camera has grown and grown and grown
and now there are like thousands of them literal
that they're asking for all these networks
for some things multiple cameras get used and the data between the cameras kind of interact
these NNs they're outputting a bunch of these variables
now there's more beyond those outputs
if the front camera, one of NN outputs is where are all the pedestrians in the frame
so the output of that is like a frame with little boxes
around all of where all the pedestrians are
say that's what comes out
so another piece of code has to take and make a decision on the basis of that
this is the driving logic
there's a couple of layers to this
there's the sensors themselves what comes out of them
and then what NNs are doing most is perception
which is taking the raw sensor outputs
and turning it into the kind of information
that you could meaningfully use in an human written program
for instance where are the pedestrians or
where are the center lines or
where is the car located in the lane
that's what i'm calling perception here
so taking the sensor input and turning it into something that's usable
after that there's planning which is given these inputs
what actions should I be taking
to pursue the goal that the car is trying to do
like if it's trying to drive down the street or if it wants to make a right-hand turn
it has to decide okay what are the things I need to do from this point forward
to achieve that goal
and then at the end there's
this layer called control which is
it takes one action at a time
it gets the car to do that
so the control stuff is it actually turns the steering wheel or activates the brakes
and so control is all written by people
the planning part is kind of a mix
at this point probably
i've seen some outputs from the cameras which are clearly intended for planning
they're not just what i'm seeing
the simplest one of those to understand is one of the things that NNs do is
they guess at a path through the scene that's ahead of it
the car is almost always moving forward
so in addition to here are the cars
and here are the lane markings and that kind of stuff
the NN makes a suggestion and it draws this three-dimensional spline
which is just a curve with a couple of bends in it
through the scene ahead of it and that's a recommendation for
where the car probably wants to go
this is the NN looking at this saying
this is probably the way forward
so on a curving road the spline would follow the curve
if you're in a lane and there's a car ahead of you
the spline might go around that car for instance
it'll make some suggestions along those lines so that's a planning function
it's not just a sensing function and
there are other things going on
that we can see in the camera networks
that are planning related
but the overwhelming majority of stuff is just answering questions about
what's the situation outside the car right now
the cars have been doing that for a long time
over time we've seen the networks get bigger and there have been more variables
some of the variables get broken up into small
you can tell that as they bump into problems in the development of particular features
they'll add additional variables to help them refine their understanding of some phenomenon
that they're trying to break down in a way that's easier for the code
that decides what the car is going to do
we saw a really big change when it went to FSD
first of all the network's got a lot bigger
there were a lot more networks and they were a lot bigger than they were before
now when a NN gets bigger that means you're applying a lot more processing to the input
because you're trying to generate more outputs
but a lot of times you just want better accuracy
so the bigger a NN is and the more you train it on
and the more computation you spend on a particular NN
the higher the accuracy of the output could be
so the outputs and NNs they're inherently probabilistic so
when it gives you that little screen and
it's telling you where the pedestrians are
it's drawing little boxes where it thinks it sees pedestrians
and each one of them has a probability associated with it
there's a 60 percent probability there's a pedestrian here
and I think there's a 90 percent here or a 95 percent.
of course what you want is for the NN to be as close to perfectly accurate as possible
especially when it's a really important question
and the bigger you make the network and the more training data
the more accurate those numbers will become
those numbers those probabilities will get a lot closer to 99 percent
and you won't see a lot of 50 60 70 percent things
because that's a problem for the people writing the code
what do you do if the car says I think there's a 60 percent chance
there's a pedestrian in front of you
do you break or do you not
you want the probabilities to get closer to 100 percent and zero percent as the choices
because that makes the programming easier
and it also means that you're going to have fewer overreactions or under reactions that
the vehicle does
and the bigger you make the network and the more data you train it on
the closer you get to that ideal of perfection of always seeing a pedestrian when they're there
always getting seeing the lane markings exactly right and so on
so that's one thing we saw
as we see more networks when we see them get a lot bigger
now previously I described it as if there was one NN per camera
and in the early days it was one NN per camera when they were running on the GP106 the NVIDIA GPU
they had a limited amount of processing power
so they didn't have the luxury of being able to run completely independent networks on every camera
for the purpose of getting different kinds of things
and now what we see is they do run multiple networks on different cameras
and probably the networks are somewhat context dependent
like they might switch networks
depending on whether they're stopped at a light
or driving on a highway or trying to maneuver through an intersection or something
but we also see the networks get kind of specialized
like their networks
that are looking for moving objects
because the moving objects have certain things in common
and if you build a network that just looks at moving objects
for instance the time domain aspects of that kind of stuff are important
then there might be another network for static objects which is to say
things that aren't moving relative to the road
like stop signs and trees and the road itself and curbs they don't move
so we see a proliferation of networks
where a single camera might have two three four
or more networks that all run on and all these networks run in real time
DAVE
I’m wondering what's the state of camera fusion are
and are the NNs being applied to that fusion view
or is it still being applied to individual cameras
DOUMA
they have a fusion architecture
where they take a bunch of cameras
so the individual networks still are still producing the outputs
they also have a really big output
that feeds into a common network
that brings all these cameras together
to create like a single fused view of that
and then the fused networks go into a bird's eye view sort of network after that
and what the bird's eye view network does is
it asks the car to imagine what would the world look like
if I were looking down on the car from a great height
like give me a map of the car and its surroundings
so when you look at the display in the car
if you've watched the FSD videos
that's pretty close to what's coming out of the bird's eye view networks
for instance if you're driving down a road the bird’s eye view network would show the curb next to you
and it would show things that were in the median or on the sidewalk next to you
and things on the other side of them also
the bird’s eye network it'll also guess
if you're driving past a wall or if you're driving past another car
the bird’s eye network doesn't see
what's on the other side of the car which is occluded
the car can't actually see what's on the other side of the car
it'll guess based on what it sees in front of and behind the car
if it sees a curb go extending past a car it'll guess that the curb is extending through
and the bird’s eye network is asked to come to bring together the top-down view from all these different cameras
to synthesize a unified view
and it's also asked to guess about the things that you can't see
and you can see this on some of the FSD videos
where it'll guess sometimes incorrectly about things that it can't see
so when the vehicle is driving past an obstacle
the things on the far side of the obstacle they might vary
or you might see a pedestrian will walk behind a car
and then the network will guess that the pedestrian continues for a little while
and then the pedestrian will vanish because at some point the car's not the AP is no longer sure
if the pedestrian is still there
maybe the pedestrian stopped walking
or maybe they turned and they went some other way
the bird’s eye networks also incorporate time
the camera networks all come together to create a unified view of one frame
and that those get fed into the bird’s eye network
then the bird’s eye network looks back over multiple frames
now so this is something
that is get pretty hard to see in the networks
by the nature of how this stuff goes
so I don't get to see a lot of it
but Karpathy's talked a number of times about this at scaled ML
where he talked in some significant amount of detail
about the architecture they were using in the vision networks and
how they were doing inthe bird’s eye networks
so everything I’ve seen is consistent with what he talked about
so my sense is that
what he talked about on scaled ML a year ago
is a pretty accurate representation of what they're doing on the car
to short answer your question
the network's got a lot bigger
they added a lot of this bird's eye top-down stuff to the systems
and they've added temporal integration
so they're looking across time in addition to just static frames
DAVE
how do you think the FSD software
for example the bird's eye view seems like it's giving a broader view
but then you also have this forward facing view
let's say the main view of the forward-facing cameras
let's say something is happening
when you're going through a turn
there's some type of obstacle
the forward facing cameras sees that obstacle
the bird's eyes view might see something a little different
how does the software reconcile those two different views
and what priority does it give
DOUMA
the bird's eye view is a product
the car of course it can't see down from the top
it's got no way of directly perceiving that
so bird's eye view it accomplishes kind of two independent things
one of them is that
it's a way of asking the car to reconcile all the different cameras
because if you're looking down from the top
no individual camera can see everything around the car from the top
so if you're going to generate a bird's eye view
essentially you've got a little square map and the cars in the center
that's one way of asking the NN to fuse all the camera views
because the front camera looks forward
and the other cameras look to the side
and if you ask it okay now put all that together
and tell me what the whole picture looks like
you can train NNs to take almost any kind of input
and generate almost any kind of output
but you have to have a way of asking a question that's relevant
so that you're challenging the network to come up with outputs that make sense
so that when you train it
you're training it to makes sense
in the context of what you're trying to accomplish
maybe the most important thing the bird's eye view network approach does is
it asks the car to synthesize to put everything together into a picture
that makes sense
you're asking a question that forces BEV to reconcile the multiple overlapping camera views
because if you don't challenge it to do that
it won't learn to do it
so you want to ask a question that's the simplest question you can ask
that at least includes the thing you want
if what you want is to integrate all the camera views into a holistic understanding of what the car's environment is
one thing you can do is
asking the network what would it look like
given all these camera inputs
what do you think it would look like
if I was looking down on the car from the top
so they're asking that question
and that's something they can answer
so that they can determine a ground truth
and provide an error function to feedback to the network
to challenge it to get better
so that's one thing
the other thing that a bird's eye network does is
it's a domain that's easy to write software in
so imagine that you have to write the software to control the car
if I have a camera view forward
and you've got a pedestrian in front of the car
you have to guess how far the pedestrian is
just having a pedestrian in front of the car isn't sufficient to make a decision
about what you should do
you're driving on a curve and that pedestrian's on a sidewalk
when you ask the NN to create a bird's eye view
you're also generating an output that's an easy output
for a programmer to write rules on
because a programmer can look at the bird's eye output
and he can say okay tell me where the road is
so here's the road
and you can ask the question
is this pedestrian in the road are they not on the road
it's not like “Are they in front of me or not”
once you've asked the NN to create this map of the environment
now your programmers have a map to work with
to make decisions about how they want to control the car
so you're getting two things out of the bird’s eye network
one of them is you're getting a straightforward framework
for fusing all these cameras together to get a kind of holistic view
which is way of asking the network to reconcile what it sees on different cameras
and then you're also getting an output that's actually useful
because the people who are writing the planning code and the dynamic control code
they now have a representation that they can work with
it's easy framework for a human programmer to work with rules inside
so bird's eye networks are a very clever solution to that
you could imagine another thing
I imagined that they were trying to make a full three-dimensional sort of virtual model
the world is three-dimensional
a vehicle that's in front of you it has a height a width and a depth and
it occupies some position relative to you
and so as a human being when you're sitting in a driver's seat
you see another vehicle
you have this sense of that thing in space out ahead of you
that you're in a volume of space and
because that's a simple and accurate representation of the reality that we're in
it's a good framework to be able to understand everything
and to work in
but the thing is
it's really challenging if you're asking the simplest thing
the NN could give you this completely all-encompassing depth with everything
which is complete description of the world
if you ask for that and if you challenge a NN to do that
eventually it'll be able to do it
but it's not the simplest thing you can ask that forces it to figure that out
it is just like asking NN that
well what would this scene look like from a different perspective than I am
that also requires a NN to understand that the world is three-dimensional
and other objects which occupy space separate from the vehicle
a NN it doesn't know any of this stuff
it's a complete blank slate
it doesn't even know what a child knows
when you start with it every single little aspect of what it learns about reality
is something it has to figure out from the data that you're giving it
so you have to ask it questions
that challenge it to come up with simple and powerful representations of the world
that you can also build on to write code to control the vehicle
getting a NN to understand that the world is three-dimensional is actually really challenging
we're giving NN a bunch of 2D images
though they're 2D projections onto a 3D world
but it's got to make decisions in 3D and somehow we have to stimulate it to understand that
it's looking at a three-dimensional world
it's not looking at four or five dimensions I guess it's four in a sense
it's a moving three-dimensional world and that's not at all obvious
in the way that we build the NNs
we have to challenge them to figure that out
and the bird's-eye view is a simple clever solution to stimulating the network to figure that out
because you only have a bird's eye view in a three dimensional universe
DAVE
let's say module or the planning code in these in FSD
are they relying more and more on the bird's eye view for planning
because before the bird's eye view
you didn't have that so you're relying more on just the camera view
are you seeing a shift over to more planning on the bird's eye view at all
DOUMA
so I’m mostly looking at NN architectures and
I have to infer what they're doing
based on the outputs
the bird's eye view outputs are going to be a lot easier to work with
than the field of view outputs are
I’m sure that they're making very heavy use of that
one of the things that we see in the evolution of these things over time is
when they had a new piece of capability come out
that we were going to see this discontinuous change in how they were doing things
it's never really been that way
they add new networks
they gradually transform the old ones
they consolidate old ones
I haven't seen them really get rid of anything so they still have all the
outputs that they had before
my guess is that
when the people writing the planning code
suddenly had bird's eye top-down stuff
they didn't immediately abandon the way that they'd been doing stuff
they started integrating it into the way they were doing planning
and over time they'll probably rely more and more on it
as they know they can trust it
and they figure out how to use it effectively
and then gradually the ways they were using the field of view or POV representations
will just kind of gradually go by the wayside
but bird's eye view is super powerful
and the integration they get the 4D stuff
they were in 2D before where they had snapshots
and now they're challenging the system to understand that it's a 3D world
and bird's eye view is a important component of how they're doing that
and they're asking NN to understand that
things evolve over time
if you see multiple frames in a row
if a block is traveling through a scene
and it's labeled truck and it's 90 90 90 80 90 you see it five frames in a row
well you're a lot you can be a lot more confident that the truck is actually there
if you see it in multiple frames
and so little variations in the probability
it doesn't affect your confidence that it's actually a truck
if you have to make decisions based on a single snapshot they do affect your confidence.
DAVE
how do they test and train like for example
for more stationary objects
the neural net will output different boxes or identify different objects
a cat, a car, a truck etc
then you could train it
you could show them the correct things and
you could go back and correct the incorrect object etc
to make the neural net improve but
with the bird's eye view
do you think some type of training is going on
in terms of correcting incorrect type of things
and how is that training being done
DOUMA
it's not nearly as straightforward as deep neural net training
if you show me where the pedestrians are in this photo
if I have a bunch of photos and I draw boxes around all the pedestrians
I can challenge the NN like this
just give me this output like
here's a pedestrian draw box around it
so I have a bunch of pictures with pedestrians which is pretty straightforward
but if I ask the NN like show me a top-down view
and now put boxes around all the pedestrians
that's a lot harder
so you can do a certain amount of labeling
by pulling in other sources that are naturally top down
as a maps for instance
and this is where it starts getting really interesting
so you can try to synthesize a true top-down view of the environment
and this is when Elon was talking about
video labeling and using DOJO to train in video
and the way that it works is you have a car drive through a scene
all right you capture all the output
from all the cameras the accelerometers
all the other sensors and that kind of stuff
you take all the footage from all those cameras
you put it in DOJO
you put in a really big computer
and that computer walks that data back and forth
and figures out what the ground truth must be
and you don't have to use neural networks to do this
you can use geometric priors and other sort of more straightforward geometric analysis
to figure out what the three-dimensional scene must be in that situation
then you can have a human being look at that three-dimensional scene
on a computer in 3D and say
this is a pedestrian
this is a fire hydrant
these are the lane lines
once the computer's got those labels
it can go back to all the frames that were used to make that scene
and it can label all of those inputs and
it can tell you because it's got the whole 3D scene built inside
if I was looking straight down on the car from the top
this is what I would see it at each instant in time
and you can create this three-dimensional model of the thing
then you can automatically generate all the labels
that you need for training
not just the cameras but also the bird's eye view
for instance DOJO can do a bunch of geometric back-end work on a stream of data
where it knows exactly what happened from the beginning to the end
and it can go back and forth over it a bunch of times
and throw a lot of computation at it
and eventually figure out what the 3D scene is
and generate all the labels what the car has to do with it
we're training a NN to figure out what DOJO can do
with a great deal of computation in the back end
and then DOJO can go figure out all this stuff to create the labels
and then we challenge the NN to do this on the fly while it's driving
so that's one way of doing it
there's another technique which Karpathy also talked about in scaled ML
which is a self-supervised training
in self-supervised training
you do a thing where you challenge a NN to tell you
what a scene looks like from one camera
when it's seen from another camera
or you challenge a NN to tell you
that you're the car is driving down a road at 30 miles an hour
and you look out one of the side cameras at the side of the road
and you see a scene the cameras take 36 frames a second
so 1/36 of a second forward in time the scene
will have shifted slightly
and I can ask the NN tell me what the next frame looks like
you can ask the NN to predict what a different camera would see
or what it will see at some point in the future
those techniques they're called self-supervised because nobody has to label the data
the system supervises itself
it generates its own inputs now
the inputs you're testing against aren't quite as meaningful to a programmer
because I’m not asking it tell me where the pedestrians are
that you're seeing out the side camera
I’m asking it tell me
what the camera will see in 30 milliseconds in the future
but the thing is
in order to be able to do that trick of predicting what it's going to see a moment in the future
or predicting what another camera will see at the same moment in time
it has to figure out a lot of stuff
about what the scene really looks like
and so that's a different trick that you can use
it produces kind of different outputs
it'll give you some of the geometric understanding of the scene
which the bird's eye view also requires
and which the bird's eye uses in a different way
so these things work together
when Tesla started doing this
you could just do scene labeling and you could just ask it
where the pedestrians were in the frame
as the systems become more complicated
and they're looking for greater and greater levels of accuracy
more nuanced understanding of environment is needed
an important thing when you're driving down the road
is what's that pedestrian going to do
so you see a pedestrian standing at a curb
this is a big problem when you drive down the street in San Francisco
you're constantly driving about two feet from a bunch of pedestrians
and there's a lot of difference to how you behave with a pedestrian
who's walking along the sidewalk towards you
and one who's looking at their phone standing on a curb
and you're wondering
if they're going to step out in front of you
so eventually the NNs will have to understand all that stuff in real time too
they're going to have to be able to read the body language and pose and motions
of pedestrians
as well as other vehicles and cyclists and that kind of stuff
so that they can predict what that person's going to do
and take appropriate action in San Francisco
you have to predict what pedestrians are doing and that's a pretty hard challenge
so as the challenges that the network needs to be challenging
as the predictions become more and more challenging
we have to get more and more clever
and not just ask it one way of getting the data
but ask it a bunch of different ways
so eventually when they've got DOJO working
they can really throw a lot of computer power at this
they'll be able to do a lot of that drive-through scene video
three-dimensional labeling back propagate all that stuff
that's really computationally intensive
DAVE
correct me if i'm wrong
with video labeling
let's say my model 3 goes through a scene
and right now it's using the NN
in my car to identify objects giving it to planning and then control
but with DOJO let's say
we take that video of the scene
we give it to DOJO
DOJO takes it through a super computer
crazy amount of computation doesn't necessarily have to be neural net
or machine learning
but it could be geometric as well and comes up with pretty much a 3D picture of that scene
and then a human labeler can go through that 3D picture scene
label the key objects
the car moving through
the person crossing the street
the dog going
then we can take those labels and then train back the neural nets
so that neural nets are more accurate in how they perceive that scene
so we're using the 3D constructing through DOJO
to create a more accurate picture of the environment
as we label it but then using that to train
the neural nets in the car
so in a sense you're giving these neural nets like super power meaning
they're on a different level now because they're using not only
what DOJO has constructed as the environment
but also you do this tens of millions over scenes
and you train the neural nets to identify the object as good as what let's say DOJO would do
you're giving NN an immense amount of increased accuracy
is that kind of the gist of kind of DOJO and video training
DOUMA
you get a lot more accuracy
because essentially you're gonna have a lot more data that's a lot more accurately labeled
so that's one thing that you get out of
but another thing that you get is
if I just label the pictures
and I’m just asking it okay tell me
a human says this is where all the pedestrians are
and I give the unmarked image to a NN
and okay you tell me where the pedestrians are
and then I compare that to reality
I compare that to what the human said
and I generate an error function
I propagate back to improve the network
but one of the things you can't do with that approach is
I can't ask the system to imagine something that's not in the frame
and require it to do a good job of doing that
when we start fusing the networks together
and we build the whole three-dimensional scene
I can start asking
I've got a pedestrian that walked behind an occlusion
a tree a bus or something
and I want the NN to understand that the pedestrian is still there
it's still walking along
I can ask it to imagine that the pedestrian is there
even though I don't have a picture to label
so DOJO can build the whole three-dimensional scene
including objects that are temporarily occluded
and I can ask the NN
tell me what's behind that bus right now
or tell me what's behind that car
because if it's a moving object a human will know this
if you see a car parked across the street from you
and another car transitions through the intersection
you understand that when the car's in the intersection in front of you
the other car is still at the stop light on the other side
humans know that
but neural networks that trained in a simple way, they don't know that
but with the DOJO approach they can do that
because I’m asking the NN to tell me the whole three-dimensional scene
including the stuff it can't see right now
I was super excited the first time I saw the FSD videos
you could see that the network was labeling stuff it couldn't see on the other side of obstacles
because we were giving them imagination
DAVE
so with the whole 3D creation through DOJO
you're mapping these objects and where they're going to be in the future
where they're headed
in a sense predicting
where they're headed through that whole scene but then teaching the neural nets
that movement
you're teaching them how to see ahead
DOUMA
that's the next step
understanding the situation instantaneously
which might include that
where the car is right now and here's its velocity
that's also an instantaneous thing because the vehicle has a velocity
another thing is tell me where the car is going to be in 100 milliseconds or 200 milliseconds
where is that car going to be when I’m 50 feet forward right
that's another level
beyond what we're talking about right now
they are doing that already
you can already see in the FSD videos
the car behaves differently like when
if it approaches an intersection and there's a cyclist coming
it behaves very differently than if the cyclist is stopped at the side of the road
there's already evidence that AP is looking at a scene
and it's predicting what the various dynamic objects in the scene are going to do
and responding to that
in the long run it has to be really good at that we expect that of humans
if you're going to pull out in front of another car
you need to have a sense of where
that car is going to be
when you can get done accelerating up to speed
is my path going to cross that other car's path
at any point in the future
if I do this maneuver so you have to be able to project both your path forward
into the future and the other thing and
understand if there's going to be any undesirable interaction there
DAVE
Elon Musk was saying that video auto labeling is the Holy Grail what does he mean by that
DOUMA
where you have a car drive through a scene
you take all the data that comes off of the car
you stuff that into DOJO
so DOJO recreates the 3D scene
you can auto label probably almost all that stuff
if so DOJO also has access to these trained NNs of the previous version of the car
so it can run through that scene with those networks and it can do a first pass guess
at where all the stop signs are
and as the networks get better
it's going to be doing a really good job of that
it's going to be 99.999 right so
when they first build DOJO and if they're first building these 3D scenes
they'll have to label a lot of stuff
there'll be a lot of details that DOJO isn't getting
but as it gets better DOJO will be able to build this three-dimensional scene
and pre-label thousands of things in the scene and
so then the human labeler's job will be mostly just verifying that DOJO is right
and of course at the tail end of that you don't even need a human in that loop
DOJO can create vast volumes of labeling data
and then you feed that into the NNs
and you close the loop with fewer humans in the process
right now their labelers are limited
they've only got so many labelers
and it's really labor-intensive
when DOJO is labeling it also knows the future
because DOJO's got the whole clip
the whole 10 or 15 seconds
so DOJO knows what the pedestrian was doing in the future
after your car passed the bus and looked back and saw the pedestrian was there
so whereas the NN on the fly
it obviously you don't know the future
but DOJO gets a whole complete thing
DOJO can run it backwards and forwards and can figure out
what three-dimensional dynamic model of that scene is most consistent with all the sensors saw all the way through the scene from beginning to end
and then we asked the NN at any point in time
to guess at the things the NN doesn't know
and eventually like people it'll get good at those guesses
say you have a pedestrian walk behind a bus
and you imagine the pedestrian keeps walking but maybe the pedestrian stopped
you can't know there's an inherent sort of uncertainty to that
DOJO can know what the pedestrian ultimately did
because it'll know after the car drove past the bus
that the pedestrian did in fact emerge from the back of the bus
and the pedestrians movement was consistent with walking
then DOJO knows what the pedestrian must have been doing
when they were included by the bus
of course the real fleet car will never be able to do on the fly
that because it just can't know the future
all the car can do is make a good guess about that but then that's just a limitation of reality
the networks will eventually get really good at predicting the things which can be predicted
but there will always be things that can't be predicted
you don't know if that the pedestrian trip behind the bus and fell over
that's just hard to predict
DAVE
how much of this effort do you think is Tesla
is already doing right now at this moment
creating 3D scenes using that as training is that
something that they're
venturing into right now or is this
something they're kind of waiting for until they get DOJO really up and running
DOUMA
They might be building the infrastructure to do that
and it'll be a work in progress for a long time
NN technologies are new enough
anything you want to do is pretty complicated
there's a good chance nobody's done it before
NNs they're very empirical it's not a theory driven domain
we have theories about NNs and why they do what they do
and they're not very good
so you can't use a theory to predict
if I build the NN three times bigger
and I give it this data and I include other data at the same time
well now what will my accuracy be? we can't do that
what we do is we build a rough sketch
and we test the idea to see if it makes sense
you can build a prototype that might be crude
the prototype will help you understand the benefit of doing it
so I think they did that
and they've probably got fairly sophisticated prototypes
now and they're probably building their way up the stack
their tools are going to constantly get better
the tools aren't one or two key features
there are thousands of small features that make the labelers more productive
and that improve the quality and quantity of the output
that you have available for training the networks
FSD is not a product like a toaster where it's just done one day
it'll just keep getting better for a long time
all the way along that every single tool in their arsenal
they'll keep refining as they go
they've probably already prototyped tools that they won't be using in production
for five years or three years or something
and they have other tools that they've been using
for a long time that they're still refining
DAVE
how cutting edge is this
Are other people other companies doing stuff like this
Is there anyone else doing this at scale
DOUMA
I don't think there's anybody doing what Tesla's doing at Tesla scale
there are certainly other people who train NNs
and use lots and lots of labeled data
and there are companies that are in the business of just making labeling tools
you have 500 labelers
and here's a tool that they can sit down at their desk
and it'll make them productive and help them avoid errors
so there's a market for those tools there are plenty of companies that are doing that
I kind of doubt anybody else is doing it at the scale that Tesla's doing it right now
I think they probably are building most of the tools that they're using
Because probably none of the commercial tools that are out there
can handle the scale that they're working at
so yes and no
other people are doing it
But I don't think anybody's doing it at the same scale that Tesla are
DAVE
do you think by the end of this year
Tesla DOJO will be up and running in some form or fashion
that it will make a significant difference to FSD and how accurate it is
DOUMA
so where is DOJO right now
they probably could have the first cut of DOJO silicon done
but DOJO is more than just they have a silicon chip
they want to make
that supports a particular computational architecture that they want
and Elon's already talked about the numerical format that they want to use
which is a numerical format that nobody else builds in silicon
so they're building their own silicon to do this
but to build a system at scale
that uses lots and lots of these chips requires a lot of power design
a lot of cooling design
communications is for these kinds of things is very complicated
and it takes a lot of work to get the communication networks to tile these things together
to build a big machine
and that is a bigger effort than making the silicon
on the other hand you can start using the silicon
if they've got their first version of their chip
they can run off a thousand of those
put them on motherboards go in the back room and pull a google
and use a regular computer racks and get that thing working and
they'll want to do that to start understanding how these things work together
and verify that the chip works and that kind of stuff
is that DOJO?
I think their aspirations are high enough
they want enough sophistication out of this thing
that there's a good chance that they haven't built a full up DOJO at this point
like a full rack of the final design
but they have early versions
my guess is that right now they can probably buy so much computation resources
that the hardware that they've built probably isn't moving the needle on it
will they do that this year?
maybe if they wanted to they could
I don't know if they'll have a final version of DOJO
when they get to where they start scaling DOJO then I think it'll matter
they'll very quickly get to a point
DOJO drops their cost of computation by an order magnitude
like out of the gate
so as soon as they get it for the same amount of money they're spending
they get 10 times as much back-end processing
and that'll move the dial on it for them
when they get that
maybe that'll be this year
AIデー向けお勉強シリーズ① ジェームス・ワンさん(前ARKアナリスト)
DojoやFSDを含めた、テスラAIのポテンシャルを理解するためのシリーズです。
テスラのAIデーを最大限に楽しむために、Dave Leeさんの動画をもとに勉強していきます。
やっぱりARKのアナリストは半端ないな~。このインタビューに知りたかった情報が詰まってる。
ご存じの方も多いと思いますが、ワンさんは、ARKに入る前は、NVIDIAで働いていました。金融界で最もGPUに詳しい方でしょう。
あとDoumaさんのFSD動画シリーズと、アンドレア・カパーシーのいくつかの講演を踏まえると、テスラのアプローチにかなり接近できると思います。
このインタビューのトピックを箇条書きすると
・テスラの保有するデータ量
・テスラがNNトレーニングにおいて直面している問題
・トレーニング用と推論用のハードウェアの根本的な違い
・トレーニング用NNと推論用NNの違い
・水平展開モデル
・水平展開モデルとしてのNVIDIA
・水平展開モデルに必要とされるカスタマーサービス
・本来は画像処理チップであるGPUをニューラルネットの行列演算に利用することの意味
・テスラの保有データを、NVIDIAの既製品でトレーニングさせた場合のコスト(時間、金額、最適化の度合い)
・垂直統合モデル
・垂直統合モデルとしてのテスラ
・Appleとテスラの事業モデルの共通点
・テスラがAIデーで示さなければいけないこと
・DOJOのスペックとして示されるべき内容
・OpenAIとGPT‐3
・GPT-3のエコシステム
・自動運転を解決するということは、どのようなAI問題を解決していることになるのか
・画像認識版GPT-3としてのDOJOとそのTAM
・新しいクラスをicrementallyに学習すること、インクリメンタル学習
・トランスファー学習の難しさ
・画像認識の一般モデル(ベースレイヤー)
・テスラが解決するの画像認識AI問題とその応用としてのFSD
・応用事例はFSDにとどまらないが、それはテスラの仕事ではない
・モービルアイ終了のお知らせ
Tesla Secret AI w/ James Wang former ARK Analyst (Ep. 318)
DAVE
you worked at NVIDIA you understand the chip side
you've analyzed Tesla's hardware etc
we know that Tesla has their so-called hardware3 in their cars
they're probably working on hardware4
now they're been working on this Tesla DOJO supercomputer
neural net training computer for the past year or two
and they're prepping for a possible Tesla AI
what's your take on Tesla DOJO
do they really have to create their own neural net training supercomputer
couldn't they use some other solution
and what are the implications for Tesla creating their own supercomputer
can they use it as a kind of AWS
neural net training as a service or
what's the kind of potential going forward with that
WANG
i was surprised when they talked about building their own training hardware
because training hardware is a lot more complex to design than inference hardware
inference hardware is the hardware you use to run the neural network
training hardware the hardware you use to create the neural network in the first place
the big difference is during the training hardware you have to feed it a lot of data
and it's the training happens in the data center
whereas inference is you've already got the software you just deploy it
it's like deploying your app on the iPhone
you just run it in the local environment in this case the FSD computer in the car
if you look at AI chip startups there are way more startups doing inference hardware
than training because training is a lot more complicated
when i saw the announcement came out
i was like why do you need to do this and i think it comes down to the fact that
they have a very specific AI problem
and they have the largest quantity of video training data in the world and for a specific application which is driving
i think the only other one you would compare to is YouTube
for this application of driving
they have more data than every car manufacturer included times probably a thousand
it's orders and orders of magnitude more
and if they were to use off-the-shelf hardware
if they were to order a computer from NVIDIA say like build together a cluster of NVIDIA dgx servers
i think it would cost them probably on the order of maybe 100 million dollars or close to that
it would be probably in that range
and the cost for them to build this in-house
given their already have a team for building FSD
is probably on the order of tens of millions of dollars
but that's not even the point
i'm sure it's not about saving 50 million dollars because Tesla's capex is in the billions
it's more about achieving what's not really plausible using off-the-shelf solutions
NVIDIA's hardware is designed to deal with all kinds of neural networks
language
speech
video
pure reinforcement learning
it's designed to solve
their strategies to launch one ship architecture for every industry-vertical
and then address the verticals using software
Tesla has a vertical use case a single use case problem
Tesla just want to solve driving
there are motivations basically saying we have this very specific use case
we have an abnormal amount of data that the current computers and supercomputers out there are not even designed to optimally handle
you would need a lot of them to fit it in
and we already have a generation of experience building our own chips using our internal team
think of it this way
Andrea Karpathy has a very specific set of software requirements
he can basically list in 10 bullets
if you can give me a computer with x
how much teraflops
how much memory
what kind of interconnect
and what kind of neural network architecture support
i would be able to train
at what rate
and if you plug in that kind of requirements back into what's available off the shelf or amazon
it probably costs an absurd amount of money
whereas if he looks across the cubicle at the hardware team
and say hey can you build that for me?
Peter(ピーター・バノン:テスラAIチップ設計主任) or whoever's running the show right now
that person will be like
yes we can build a five nanometer chip of this size
we can build a custom interconnect that's perfect for your video
in fact we can size the buffers to match the size of the video buffers
and build a super optimized chip
and attach storage and a memory really close to the chip
and we could probably ship it by the end of this year
and that would allow them to basically leapfrog any competition
not that they have any real competition but it would allow them to essentially take all the data they have
which right now is too large to plausibly fit in the training hardware you can buy off the shelf
but actually make it fit in this custom computer they build
and if they can make it fit
they can train the perfect neural network that would actually solve self-driving
and you optimize that, shrink it, ship it in FSD in the inference size
okay Tesla makes their own internal neural net training clusters
it's great it works well for them
DAVE
it seems like there's a couple paths here
one path is
fine it's an internal neural net training computer fine who cares Tesla does
and the results and the benefits are purely FSD
another route to go
can they use this stuff that they've learned and that they've built
to do something else
are there other business lines
can they open it up a service
is there any potential for that
is that even like some revenue that's significant or not what's your take on that
their own training hardware
WANG
it's easy to like go down the road of
oh you have a chip now you can build an AWS or diversify your business
i don't think that's how it works at all for this kind of thing
the whole point of this is how vertical are you.
your first business decision your first strategy decision you make as a business is
are you a horizontal business or a vertical business
If your are in a horizontal business
you build a component like NVIDIA and you try to sell it to as many people as possible
if you're a vertical business model like Apple
you build a very specialized thing for yourself and you keep it damn well to yourself and you don't give anyone and
if anyone even builds something that even looks like it
you sue the hell out of them
those are the only two business models that make sense
anything in the middle doesn't make sense
it's very confused and it's not optimized for anything
Tesla is pursuing the vertical strategy
even if lthey shouldn't have the desire to share this with anyone
because it's just literally throwing away your competitive advantage in the wind
and it's not like this is part of the mission of accelerating sustainable energy
this is not battery technology where it's just good for the environment if you share it
this is proprietary software technology that will help you differentiate against everyone else
doing it it's not part of that open ethos
and secondly horizontal business models have entirely different requirements
and operating realities than vertical business models if you want to sell this chip
as a service now you have to build out a whole team that is about supporting your customers use cases
let's say Tesla is like okay we're all image based sensor array
we have no lidar and and this is why we built the chip
this way you try to sell it to someone that's using lidar
they'll be like oh can you add support for a lidar image map
can you add support for this buffer that buffer
soon you're just like you need a whole team to service customers
that's not what Tesla does
Tesla does not service the needs of VW and GM
they're in the business of serving their own teams first and foremost
just looking through the lens of Apple
i wrote a blog on this
Tesla through the lens of Apple
the strategy is exactly the same
they're going to make their own things the absolute best first and foremost
and that's their level of differentiations against competitors
they neither have the desire nor does it make any business sense to make it horizontal
because it slows them down and it makes no significant revenue
DAVE
elon musk was saying that Tesla can become one of the largest AI companies in the world
at least like shallow-minded, not deep-minded like google but
and you've got this whole Tesla AI day coming up
and if you look at historically their events
with autonomy day and battery day
they have been very significant like strategy events five or ten year foundational events
that they've hosted for a Tesla AI day
one angle you could say
they'll just showcase some of the stuff they're working on autonomy or whatever that narrow case
but my question is like does that really deserve a whole Tesla AI day
then it's also in light of elon's recent comments
that they could possibly become one of the largest AI companies
is there something else you think that Tesla can showcase or really make Tesla AI day about
the other angle is like elon's saying hey we tried to solve autonomy but on the way along the way
we've had to solve a lot of real world AI problems as a physical world navigation
all this stuff in the busy world of humans and bikes and kids and pedestrians all this stuff and
there's a lot of expertise built up with that
that is not just for you're trying to solve autonomy
but you've built up all this extra real world solutions and expertise
like where is this headed
do you see potential for Tesla to get into other real world applications like robots like drones
WANG
that's interesting i wasn't aware AI day is coming
that's very interesting the last time they did i think was a battery day and they showcased some advances
the most obvious thing they need to show is material progress on FSD
because they've been in beta and trialing this out
they've made promises that they've broken over and over again
they need to show a demo that's far more compelling than the palo alto demo they did a few years ago
i think something on the order of complexity of busy streets san francisco
they need to show a like draw dropping demo
to put some of this criticism and skepticism from the press behind them
i think they may talk about certainly DOJO and the kind of the infrastructure side of
how they're going to differentiate and the mechanisms of training
on large-scale video data which is no one is doing
those are probably nuts and bolts
but if you were to speculate on future places they could go
what's interesting is Open AI has provided a perspective on what business you can build with really large scale models
Open AI started off as a research organization for AI like the deep mind of the US
but evolved to a commercial company
and their first product is a product called GPT-3
and it is a generative language model basically a neural network that can write call it english and it's very generalized in the sense that
it not only writes English it can write poetry
it can translate between languages
it can write JavaScript
it because it was trained on the entire corpus of text on the internet
so it's read every stack overflow
it's read every programming manual
it can actually output code
when you train across an extremely large data set
you can basically learn all the sub use cases expressed in that data set
what Tesla potentially could build with its video data set
is a generalized computer vision data set
if the result of DOJO and all this data is
with very little human labeling
it can build a neural network that has robust understanding of images and video
you could think of that as a GPT-3 equivalent but for video
and that could perhaps be deployed in all kinds of adjacent industries
it could be deployed in surveillance security robotics
there are many applications that could become conceivably a SaaS product or
like a API that they could offer to developers
that could just generate pure software revenue
DAVE
if you are solving real world AI where
you actually with vision have to identify not only every single object
but also have to identify its velocity how fast it's moving it's distance from you and from others
and make predictions on where things are going as well
you're solving all of these problems with understanding real world AI
actually maybe creating a 3d type of understanding of what's going on
this type of expertise in real world can possibly apply to many other scenarios or use cases
one angle is Tesla could possibly go into physical robots or drones where they it needs that type of real world understanding
another angle is maybe they can open it up as a web service or API or something
where if Tesla has not just data set but this neural net vision platform
where they can identify not just objects but again it's like everything going around in that environment
they could let other companies other people latch onto
one of the questions i was having was
okay but how does it get better
if a company is using it for a specific case and it needs to be improved in that specific case
let's say they're monitoring lizards or something really niche case
and Tesla doesn't have a lot of lizards
is there a way where Tesla can run a service
where this stuff is can be improved by the very developers that are using it
actually input these images labels or something
where it could actually train the whole neural net to make it better
is that too complicated or is that something that's possible
WANG
i think it's not very easy with current technology for that neural network to learn to incrementally learn a new class
it has to learn from scratch again
typically like human training
human training or human learning is incremental so
if you have to learn a new thing today
you can just write that on top of your existing knowledge
you don't have to delete or start from scratch
but the way neural networks typically is trained is that
if your neural network has been trained on 100 lizards
and you need to learn a new class
you basically add the 101st data set into your data pool
you run it again to learn it
because it all sums up to a probability of one
typically the way it's done is not easy
you can do transfer learning but you tend to forget the older stuff as well
and for GPT-3 there is no way the customer can augment the training data
Open AI does everything
it gives you an API and you have practically no control
you can condition your ass your prompt and answers
but you can't add to their training data set
and you can't certainly do a little bit of incremental training as a customer
and then use that as a custom solution to yourself
i think it's not very easy
like from a Tesla's perspective
instead of being that more flexible
I think it's more like addressing the
low-hanging fruit of
if we can just offer this base layer
generalized computer vision model
let's see what you can do with it and
without doing any customization
GPT-3 has proven out that model even with no customization with client side
actually works pretty good
can generate many useful use cases
thousands of developers are working on it
step one you don't have to get too fancy just give people access to an incredibly robust vision model and i'm sure they'll figure out what to do with it
that's fascinating
DAVE
GPT-3 for vision or real world
one of the the challenges is like with OpenAI they were able to get billions and billions of text from everywhere on the internet to analyze and feed their neural nets and but in Tesla's case it's more limited
it's a narrow niche of just driving
it's not really because there's so many ways to interact with the real world that isn't just driving
it's not as generalized as for example OpenAI's approach to language and text all that stuff
→この返しはちょっと的外れだな。ワンさんはそんなことは言ってない。
WANG
i think it's a vertical specific neural network
it's a driving it's a generalized network for driving
for general vision
yeah it's like it doesn't even have images of inside the house right by definition
i think that is challenging
i think probably the most easiest adjacent industry can do is
to maybe license it to other automakers who need help
because they have less than one percent of Tesla's data set
they could make that a licensing business to that industry vertical
that's probably the most obvious thing to do
but if you're a toyota or gm you would be at lowest to license this piece of software from Tesla
who's already killed you and now you're going to pay them to kill you more
(トヨタが死亡扱いされててワロタ)
But what is your choice
you're gonna use an intel mobile eye with chip which is not really a programmable stack
and still you have no data
there are not a lot of choices
テスラコミュニティに学ぶ AAPL の現状とテスラの強み
アップルは将来EVに参入することになるでしょう。なぜそうする必要があるのか、その場合にどのような条件が必要になるのか、テスラの持つアドバンテージとは何なのか。テスラコミュニティに教えていただきます。
VALUING APPLE AS AN EQUIVALENT BOND
— JPR007 (@jpr007) 2021年2月5日
Let's see what happens when we make some reasonable projections for Apple's future
1. The trend-line growth rate for Apple's Revenues is +7% per annum
- this takes us to $540 billion in Revenues in 2030 pic.twitter.com/i8q16mgmFM
1. Appleの売上の成長率のトレンドラインを引いてみると、年間+ 7% になります。このペースが続けば、2030年の売上は 540ビリオン(55兆円以上)になります。
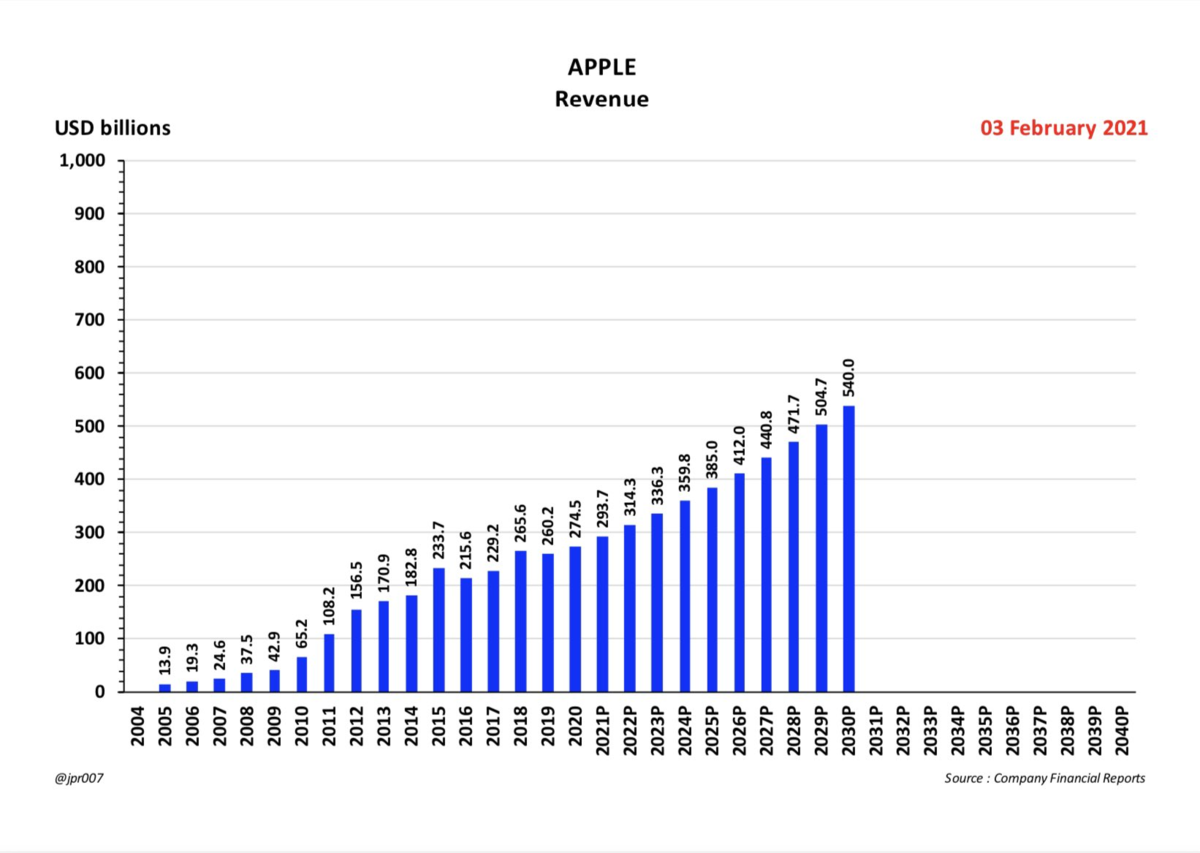
2. Appleが、粗利益率を現在の 38.2% で一定に保つと仮定します。
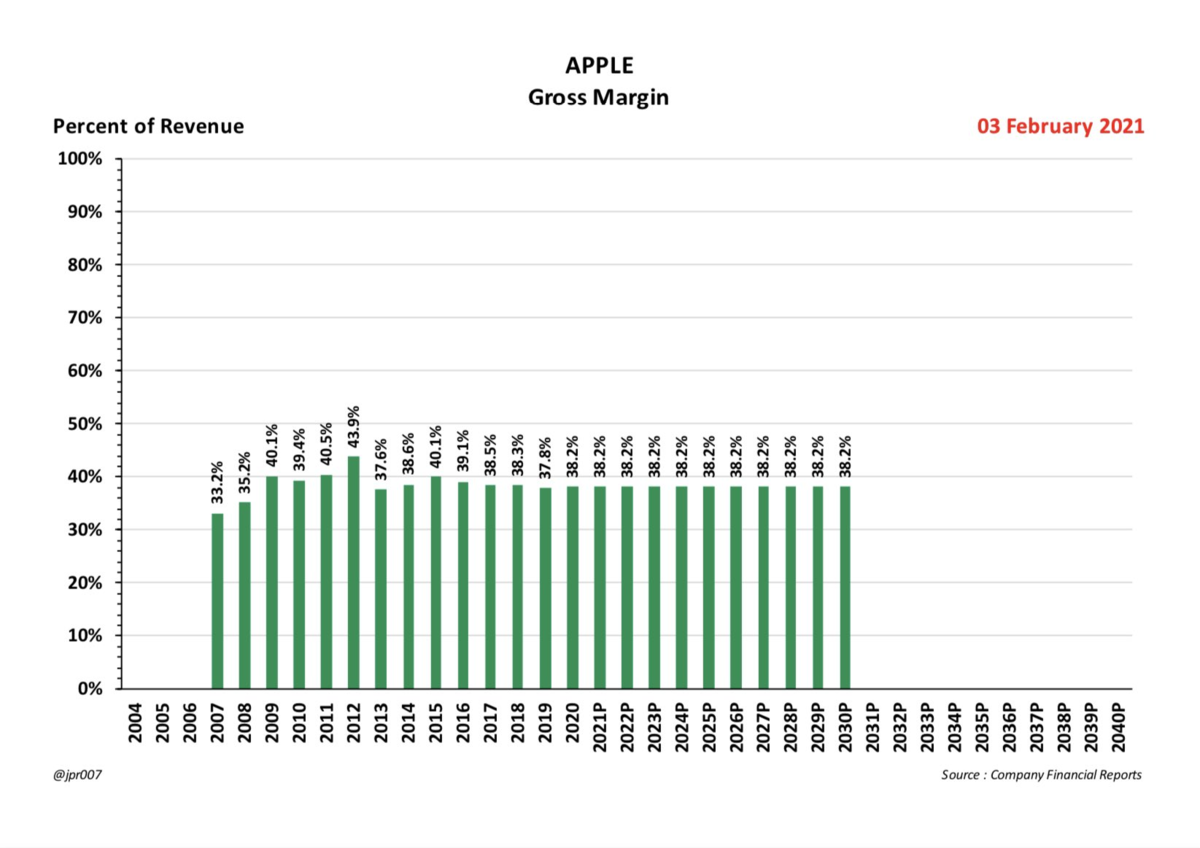
3.その場合、2030年のアップルの粗利益額は 206.5ビリオン(20兆円以上) になります。

4.このチャートはアップルの研究開発費、販売管理費の予測です。
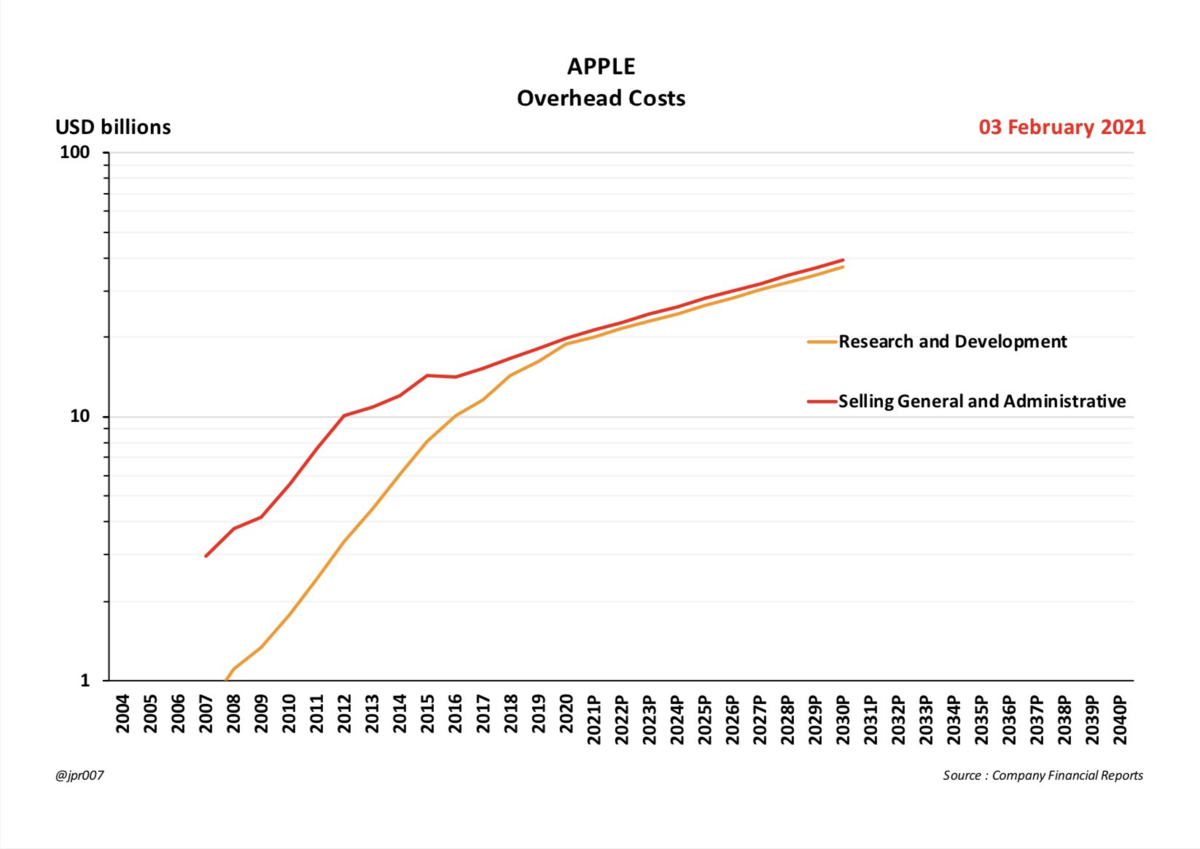
5.収益に対する間接費の割合は、一定に保たれると想定します。

6.アップルは2030年までに、大量のリソースを利用できるようになります。

7.売上と営業利益の変化は以下のようになるでしょう。
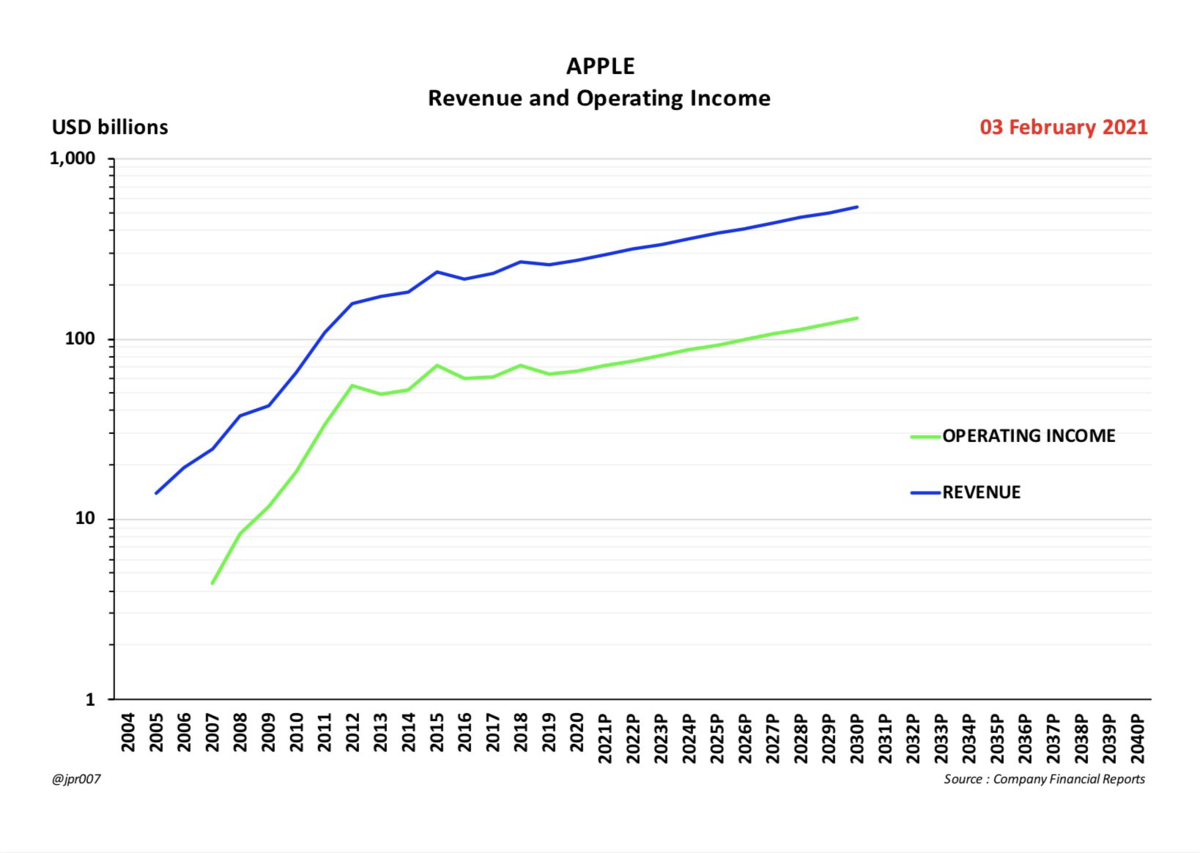
8. 営業利益率は 24.1% で安定すると仮定します。

9.営業利益額はは2030年に 130.4ビリオン に達するでしょう。

10. 現在の14.4%の所得税率が変わらないと仮定します。すると、純利益率は売上の20.8% になります。
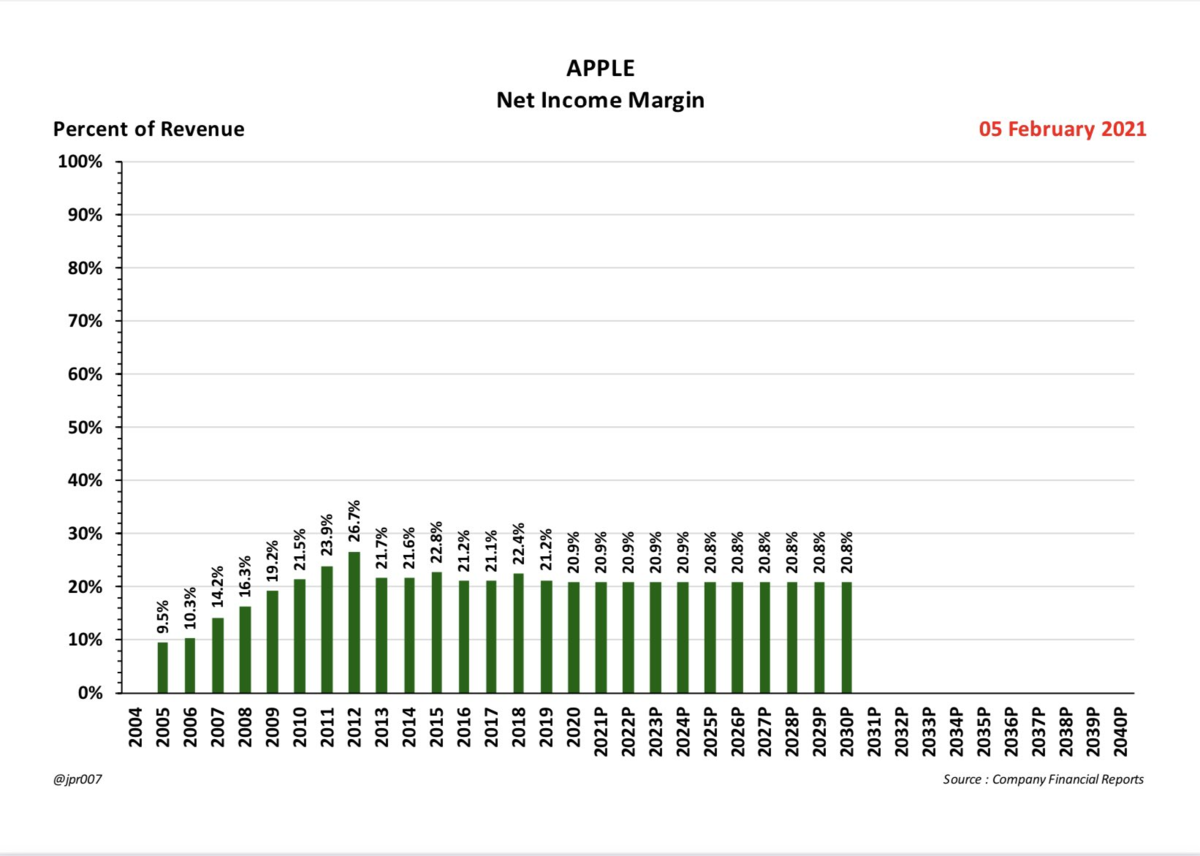
11. 2030年のAppleの 純利益は 112.3ビリオンになるでしょう。

12. 以上をまとめると、2030年のISは以下のようになります。
青色の項目は見積もりです。
緑色の項目は、現在の値と同じです。
この前提に基づくと、時価総額は 4.4トリリオン です

13. Appleが自社株買いプログラム(Stock Buyback program)を現在のペースの、年間 -5.5% で続けると仮定すると、将来の発行済株式数は、2020年の175億2800万株から99億5500万株に減少します。
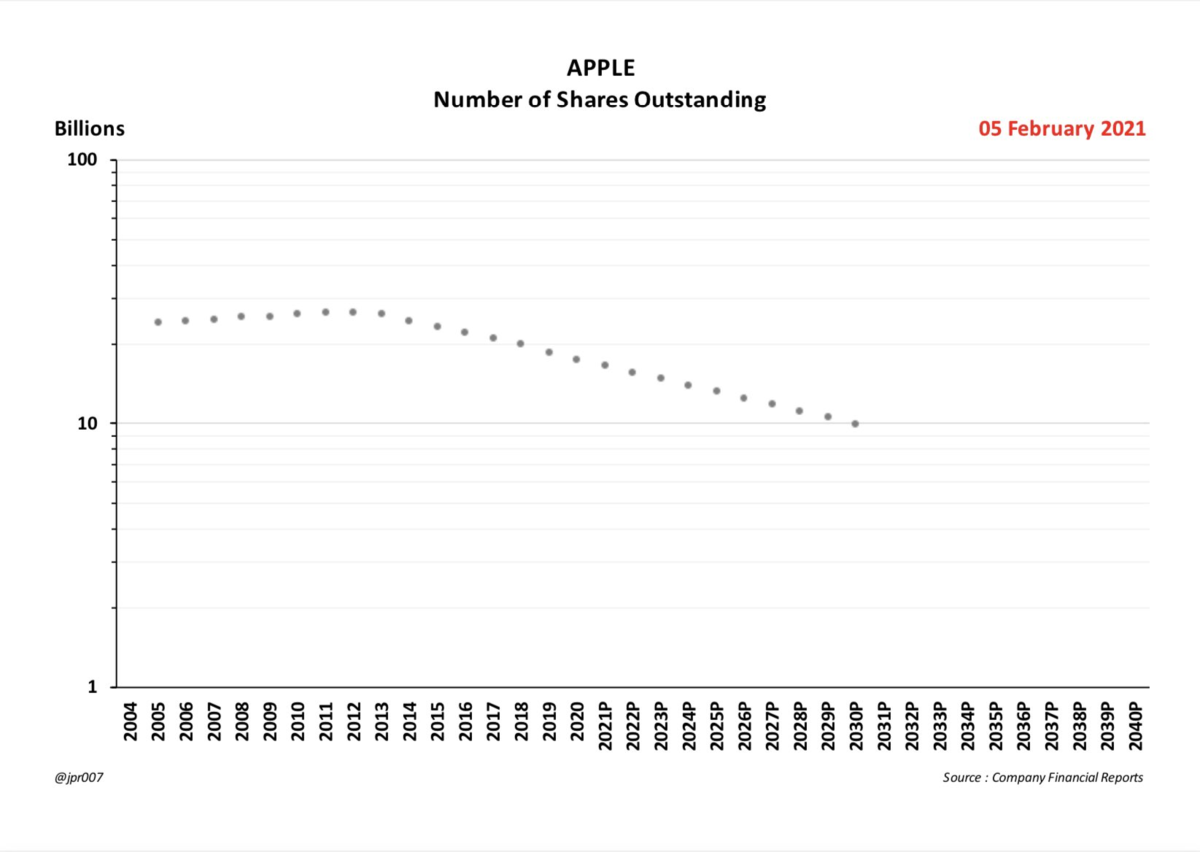
14. この自社株買いにより、2030年の予想株価は
$ 4,400 / 9.955 = $ 442
になると予想されます。
これに15%のディスカウントレートを適用すると、2021年には
125.64ドル
と計算することができます。
15. 株価の見積もりには、さらに現金配当の現在価値を加える必要があります。このために、純利益の25%の割合での、配当性向(continued Dividend Payout Ratio)を想定します。
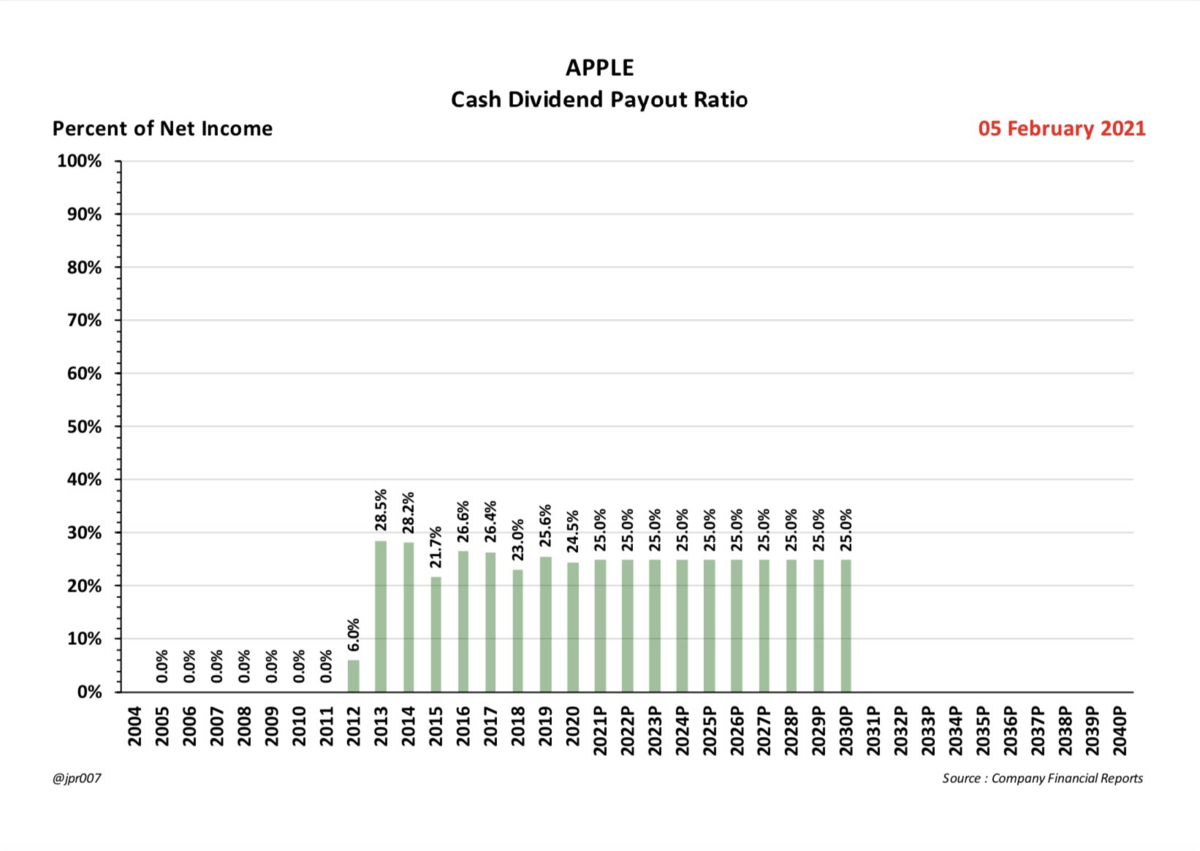
16. 以下のような現金配当の支払いストリームを想定します。
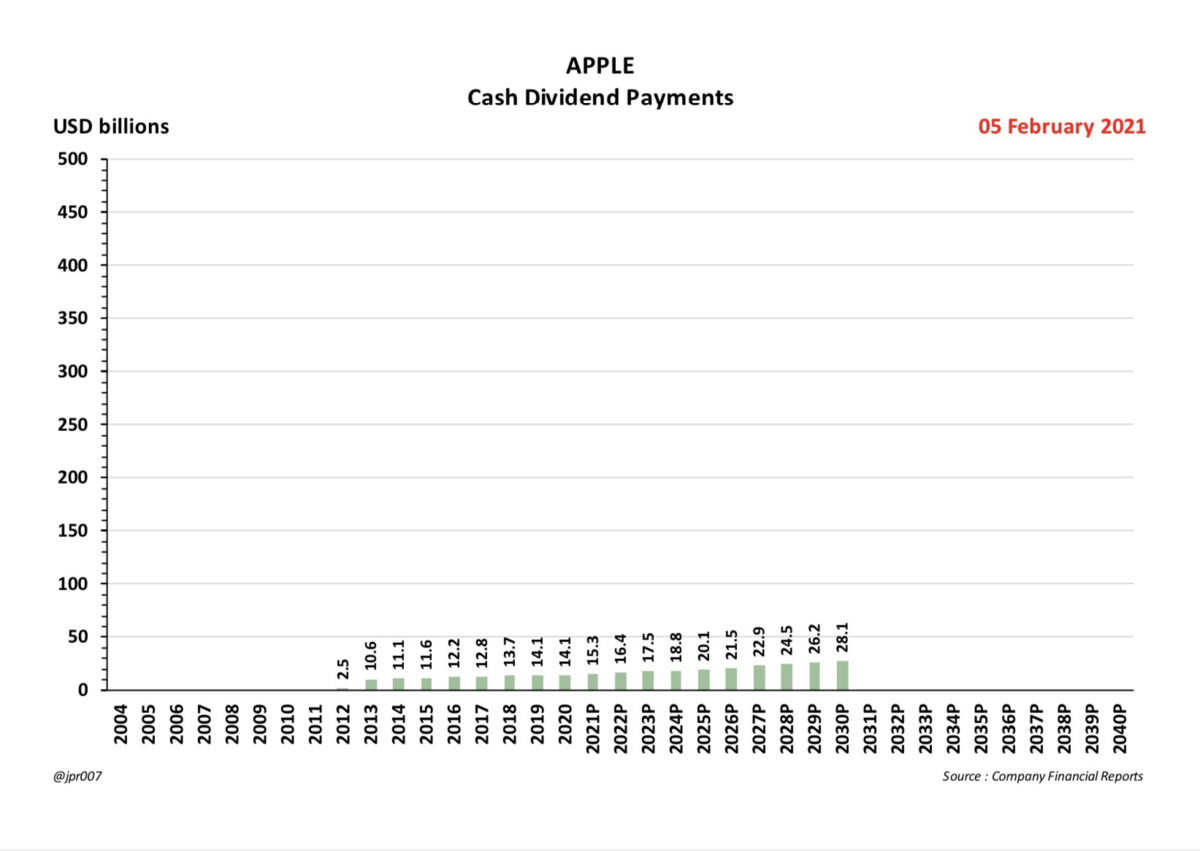
17.1株当たりの年間の配当金額です
同じ15%の割引率でこれらを現在価値に割り戻すと、1株あたり8.62ドルとなります。

18. $ 125.64 + $ 8.62 = $ 134.26 と現在の理論株価を計算することができます。
これはAAPLの現在の株価とほぼ一緒です。

19.それでは、このモデルに潜むリスクは何でしょうか?
このモデルの最大のリスクは、現在の株価収益率 39.2倍 が継続すると仮定していることです。

20.現在のPERは、S&P 500の歴史的水準に比べて、非常に高くなっています。ゼロ金利に近い状態であれば、現在の状態も正当化することができますが、2~3年後に金利上昇が本格化してくるようであれば、現状のような高PERは正当化することが難しくなってきます。ただしPERを20倍と想定するのであれば、長期的に(10年後)も許容することができます。
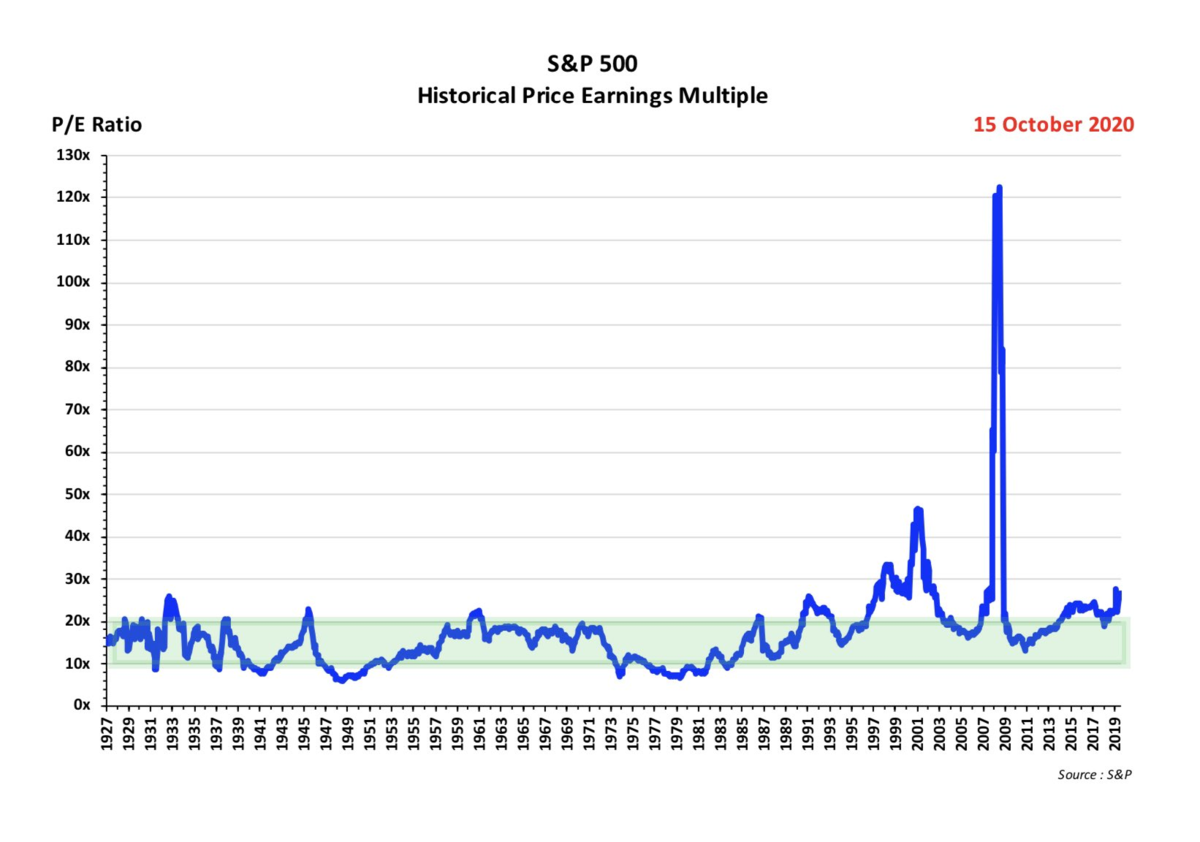
21. 高PER問題、これは「AAPLに限った問題」ではありません
現在の市場全体が、PER 39.57倍 のレベルにまで上昇してきています。
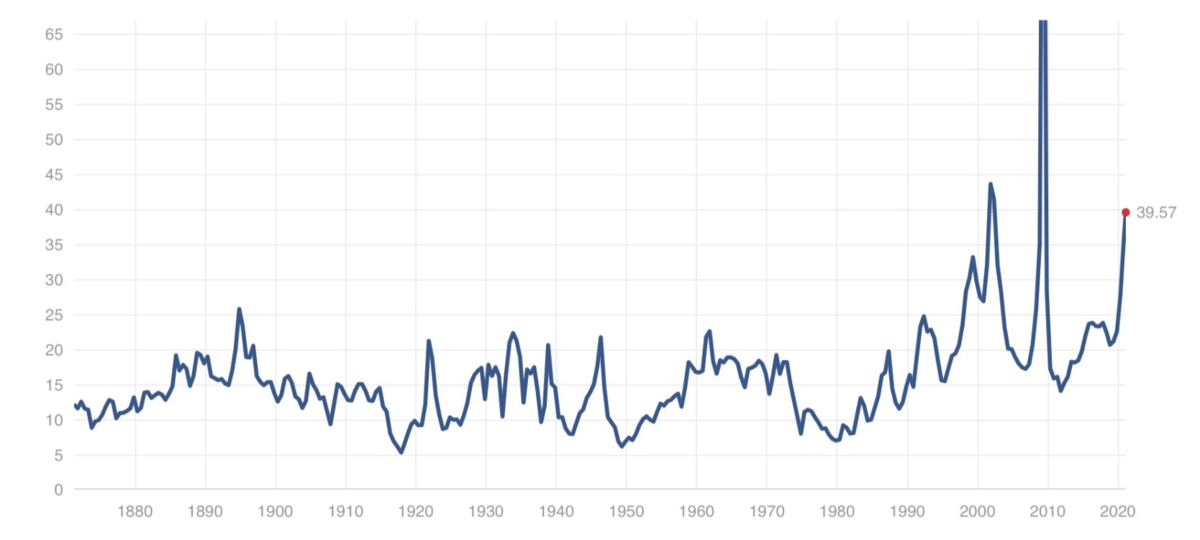
22. もし仮に、株価収益率が2030年までに、20倍に低下した時点から割り引くならば、企業価値の現在価値は $ 125.64 x 20 / 39.2 = $ 64.10 に低下してしまいます。
23. その際の株価の現在価値は、64.10ドル + 配当の8.62ドル = 72.72ドル になります。
24. その他の、明確なリスク要因は次のとおりです。
-実効税率はわずか14.4%と想定
-売上成長率の想定が楽観的
-コストの増加率をやや保守的に見積もっている
25. 「Apple Car」のような新製品は、これらの問題を解決するとは限りません
新しい売上は、コストの増加とマージンの低下をもたらす可能性があるためです。
個人的感想
↓
アップルは、アップルカーの販売台数を増やすと同時に、しっかりと高いマージンも確保していかなければ、現在の株価をさらに上昇させ続けることは難しいだろう。
↓
既存の製品での成長が飽和状態に達しているサインが随所に現れている。
↓
ただディスカウントレートが15%っていう、特大の数字を使っているので評価の難しいモデルではある。PEは楽観的で、割引率は保守的なモデルとなっている
↓
アップルは、ハイエンドのEVマーケットから攻めざるを得ないと思う。その意味では、年間10万台の販売目標は理にかなっている。
↓
ただし年間10万台ではマイナーな存在を脱却することはできない。そこからマージンを確保しつつスケールする方法は?
↓
また下請けに作らせるというスタイルは、既存ののOEMと同じで、テスラの超垂直統合とは対極なモデルである。統合ソフトウェアは素晴らしいものを出してくるであろうが、それとともにバッテリー供給や、プロダクション・ランプアップなどの問題をどのようにクリアしていくのだろうか。アップルの腕の見せ所である。
1/ Why #Tesla will be much more successful than #Apple, and much harder to compete against.
— David Wang (@DongyanWang8) 2020年12月7日
I am still admiring #SteveJobs and the great #Apple success, while I think #Telsa will have much greater success than Apple. This will have huge implications to $TSLA and competitors. pic.twitter.com/zFwBeXxTsW
1 / 今後テスラは、アップルが成し遂げた成功を、上回って成功する可能性が高いです。その分析を以下に記します。
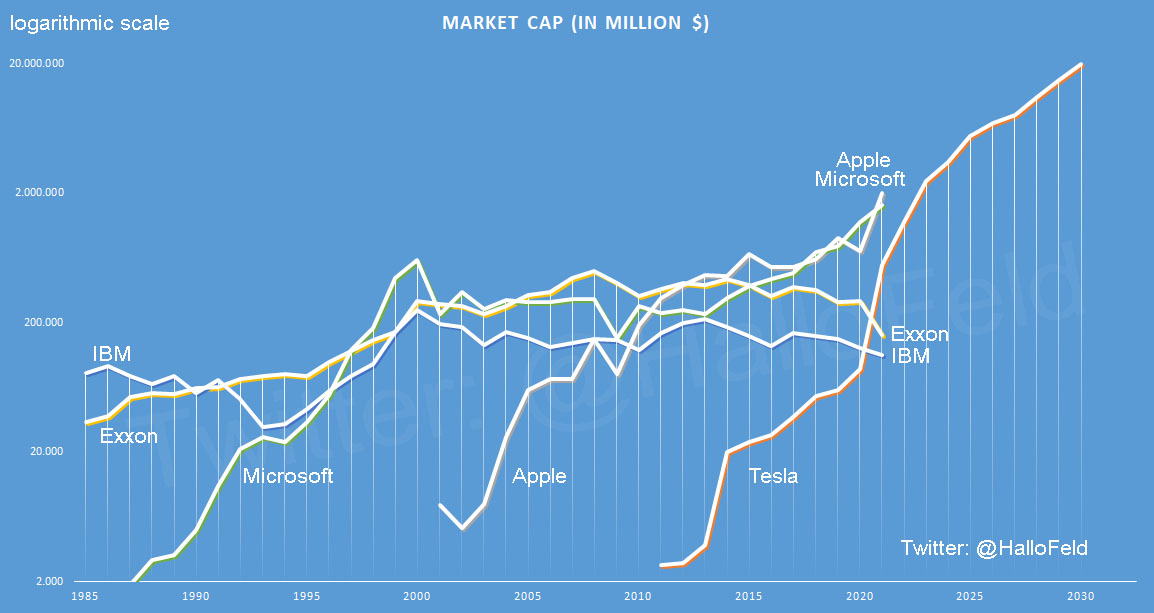
2 /
アップルは、過去10年以上にわたって機会損失を発生させ、戦略的ミスを犯してきました。
iPhoneを AT&T 専用にしてしまい、Verizonやその他のキャリアが、アンドロイドを選択することを許してしまいました。
3 /
スマホ画面の大型化を何年も遅らせた結果、Samsungなどの競合他社の台頭を許してしまいました。
iPhoneの価格を、高価格(高収益)に保つことを選択し、Huawei、Xiao Mi などの中国メーカーの台頭を許してきました。
それらのメーカーの端末は、本当に良いものとなっています。中国の私の友人の多くはHuaweiのスマホに切り替えました
4 /
MacBook Pro やその他の製品を高価格(高収益)に保つことを選択したため、TAMの中での市場シェア(market share of the TAM)はわずかなものにとどまりました。
ハードウェアは高価ですが、ソフトウェアは無料で提供してしまっています。
理想的には、より多くの顧客にリーチするためには、ハードウェアをより安く販売しつつ「Appleのソフトウェア」にたいして、少額を月額サブスクリプションで課金してもらう必要がありました。
5 /
Appleは、競合他社もアクセスすることが可能な、外部企業に、製造を委託しています。製造に関してアドバンテージがないということです。
6 /
アップルの近年のイノベーション速度はとても遅いです。新製品リリースの発表会は、ICE車のリニューアルの発表会と同じような印象を与えます(カップホルダーイノベーションに陥っているということ)。新機能を一気に投入することなく、小出しにしている感じを抱かせます。
上記の決定の多くは、主に「利益志向」の考え方に基づいて推進されたものです(最近のNVDAもこれに陥っている可能性がある)。
7 /
テスラとは何が違うのか?
イーロンとテスラの使命は、持続可能エネルギー社会への移行を加速することです。したがって、彼の最初の動機は決して利益ではありませんでした。正しい考え方はすべての基盤です。
8 /
テスラの製品は、とても速いペースで、あらゆる面で改善し続けています。同時に価格が下がり続けています。
テスラのような製品は見たことがないです。プレミアムな製品が、以前よりもより安い価格で販売されて続けているからです。
さらに、OTAのSWアップグレードで製品が常に改善し続けます。
9 /
さらに垂直統合があります。テスラは機械を作る機械(the machines that build the machine)を作り上げています。
製造プロセス全体を、他のメーカーにアウトソーシングするのではありません。これにより、テスラの技術に競合他社がアクセス、コピー、およびキャッチアップするのがはるかに困難になります。
10/
SpaceXファクターがあります。 SpaceXのテクノロジーはテスラを助け、逆もまた同様です。
ロケット・サイエンスをEV産業に応用しているのです。SpaceXロケットまたはスターシップが打ち上げられるたびに、テスラのカスタマーは、自分たちが特別な企業の車に乗っていること思い出します。
11/
テスラカルトの存在です。私はAppleファン・ボーイでしたが、Teslaファンと比べると、取るに足らないものでした。彼らは毎日何時間もかけて調査し、オンラインで投稿し、他の人にメッセージを伝え続けています。
12/
他社がテスラと競争していくのは、非常に難しいでしょう。
テスラは非常に多くの分野でイノベーションを加速させています。
(FSD、バッテリー、高度な生産技術・生産プロセス、AIチップ、OTA SW、自動車、ストレージ、ソーラー、スーパーチャージャー、保険、eAirplane)
13/
◎極度の垂直統合
◎最高のエンジニア集団とタレント集団にアクセスできる
◎莫大なTAMを抱えており、隣接する市場にも足を踏み入れることもできる
◎忠実なカルトフォロワーと顧客ベースを持っている(OTA SWのアップグレード、Elonのツイート、またはRocketのローンチによって常に更新される)
14/
強力なコスト競争力を持つ中国メーカーでさえ、テスラと価格競争していくのは難しいでしょう。
中国政府はテスラという「サメ」を招き入れ、テスラとの競争により、自国企業が競争力を高め、それにより自国のEVサプライチェーン全体を成長させる戦略を採用しました。これは本当に賢明な判断です。
だから私は強く信じています。テスラは今後10年間で、アップルが過去に成し遂げた偉大な成功を上回って、さらなる成功するでしょう
テスラコミュニティに学ぶ 2020Q4 ERのポテンシャル

Q4決算を受けて、テスラコミュニティで分析が進んでいます。EPSが「ストリート予想とかいう勉強不足のアナリストどもの平均値」に届かなかったことで、失望決算とかいう輩もいますが、個人的にはポテンシャルしか感じない超絶決算だったと思います。
とくにカンファレンスコールには今後の事業展開についての素晴らしいヒントがちりばめられていました。
とくに Dojo。 これは、アマゾンにとってのAWSと同じストーリーをテスラにもたらす存在だと感じました。
EV、エネルギー、ロボタクシー、Dojo これらのポテンシャルが全て開花した暁には、テスラの時価総額1,000兆円余裕で越えているでしょう。
1/11
— David Wang (@DongyanWang8) 2021年1月28日
My key thoughts for Tesla Q4 earnings:
1. Q4 Gross Margin (GM) is lower than expected, but:
. Auto GM is actually higher than Q3, after taking out noisy one time factors like investing in S/X refresh/single piece castings, big Y price cut in China (great for long term...
1. Q4粗利益(GM)は予想よりも低かったです。ただし、
オート部門GMはリカーリングで見れば、実際はQ3よりも高かったと思います。一時的な費用がかさみました。
「S / Xリフレッシュ」
「シングルピース鋳造(single piece castings)導入にともなうコスト」
「中国でYをマージンを圧縮して販売」
「Covidによるロジスティクス費用と人件費の増加」
などなどが加わり、マージン・レートを一時的に悪化させました。
エネルギー部門GMは、ソーラールーフのランプアップによって低下しました。ただしそれにより業界でベストのコスト構造を作り上げ、業界1位に戻る準備ができています。
R&D費用の大幅な増加
サービスセンター、モバイルフリート、スーパーチャージャーの急拡大に伴う費用増
転換社債の早期決済による100ミリオンの利息
イーロンに対する株式ベースの報酬
これらは長期的には素晴らしい結果をもたらします。CFOのザックは、営業利益率が引き続き増加していくことを認めています。
2. 展望(Outlook)
テスラは「これから何年も」50%成長し続けます。
2021年のデリバリー数は「実質的に」50%のガイダンスを上回り、「2022年も同様に上回る」でしょう。
2021年後半は、さまざまな新製品の増加により、デリバリー数は年前半よりも多くなります。
イーロンは2021年が素晴らしい年になると考えています!
多くの新製品、工場の新設・拡張が進行中です。
テスラの売上規模が急拡大するにつれて、売上比での営業費用の割合は低下していきます。
テスラは、WSの短期的な期待に応えるよりも、50%以上の長期的な成長を継続することに集中しています。これは絶対に正しいことです。
3. FSD:
1〜2か月以内に、FSDの月額サブスクリプションが導入されるでしょう。
FSDは急速に改善されています。フィードバック学習も急速に進んでいます。1000人以上のベータユーザーが新規に追加されました。
イーロン「私たちはたくさんの実データを持っています、大量の実データは素晴らしいAIのために必須です。」
イーロン「聖杯となるのは、ビジョンシステム上での、自動ラベル付けです」「これは私のようなAIの人にとっては夢です。」
もう1つの重要なことは「FSDは現段階のテスラのNNチップで実現でき、新たなv2チップ + ハイレゾカメラは必要ない」と述べたことです。
人の運転よりもFSDのほうが100%安全となるだろうこと。この実現のための障害はありません。
イーロン:「オートノミー実現に関して、誰が2番目になるか見当もつきません(現段階でテスラが圧倒的なリーダーということ)」
Dojoはトレーニング用スーパーコンピューターです。
イーロン「Dojoが、世界最高のニューラルネット・トレーニングコンピューターになると信じています」
この発言は「グーグルが現段階で何を実現しているのか」をイーロンが、的確に把握してることを意味します。NNチップを用いたサービスでグーグルを越えられると考えているのです。ゆえにこの発言は素晴らしいです!
Dojo これは新しいビジネスラインになるでしょう。AIのSaaS、AIaaS です。
4. バッテリー
4680セルに対するショー・ストッパーは見当たりません。また2022年までに100GWh生産を達成するでしょう。
5. 新しい モデル S/X
これは素晴らしく未来的な車です。1ヶ月程度でデリバリーされるでしょう。
イーロンは、おそらく今週後半に改めて、新しいモデルS / Xの発表会を行うだろうと述べました
6. CyberTruck
ほぼすべての開発・エンジニアリングが終了しています。
工作機械を発注できる段階です。
CT用の8000トンの鋳造プレス(8000 ton casting press )の導入が決まっています。
2021年に一部デリバリー開始される可能性がありますが、大規模なデリバリーは2022年になるでしょう。
7. テスラの企業価値
イーロンによれば、Teslaを$ 1T企業として、評価するのは簡単なことです。Robotaxiに2倍の車両使用率を適用するだけですから。(only using 2X vehicle utilization for robotaxi.)
↓
これはなんとなくはわかるが、細かい計算式がよくわからん発言だった。
CFO:キャパシティとテクノロジーへの長期間に渡る投資のメリット(将来の爆発的成長)を理解しています。
アフターアワーの下げに惑わされないでください。Q4 決算は驚きに満ちています。
〇付いたコメント
イーロンによると、中国でのFSDの購買率が1%であると述べました。多分それはマージンの低下と関係があります。 FSDサブスクリプション と Plaid S / X は、マージンが改善されてくるのに役立つでしょう。
↓
同じことを考えていました。中国でのモデル3の値下げと、モデルYの低価格でのローンチ、さらに低いFSDテイクレートは、マージンを引っ張っています
明晰な頭脳と根性を併せ持つ若き投資家フランク・ピーレン
1/12
— Frank Peelen (@FrankPeelen) 2021年1月28日
Tweet thread with my thoughts on $TSLA earnings.
A bad ER for investors focused on the short-term (financials), but it contained some really great nuggets for long-term investors.
Let's start with the reasons why financials were weaker than deliveries might've suggested:
短期的な財務のみに焦点を当てた投資家にとっては悪いERでしたが、長期投資家にとっては「素晴らしい金の卵」がいくつか含まれていました。
デリバリーの数が事前に示唆したよりも財務結果が弱かった理由から始めましょう。
自動車部門のGMは大幅に値引きされたモデルS&Xにより苦しめられました。(旧車両のテスラへのトレードインなどで、実質的な割引を受けることが可能)
カンファレンスコールで示唆されたことは、在庫を売却するための措置だったこと。また 新しいモデルのローンチを踏まえて、現行の「古い」バージョンを、割引いて顧客に提供するためであったことです。
顧客の利益のために正しいことをすることは、長期的に見返りがあります。
エネルギー&サービス事業GMも、将来に焦点を合わせたために苦しみました。
ソーラールーフのランピングは、エネルギー事業のGMの重しとなっています。しかし、これらの投資は今後数年間で大きな成果を上げるでしょう。
サービスGMも将来への投資により弱含みでした。これらは両方とも一時的なものでしょう。
営業費用(OPEX)は大幅に増加した可能性がありますが、今期のOPEXの多くは、CEO CompPackageに関するもので、1回限りの費用でした。
また営業費用の増加は、売上成長に伴うものとも予想されます。これまで大幅な売上成長にもかかわらず、過去4〜5四半期で、OPEXがほとんど増加しなかったことの方が驚異的なことでした。
テスラのようなハイパーグロース企業にとって、各種のマージンとコストが変動しつづけることは当たり前であり、正常なことです。
普通株を保有しているだけの場合は、短期的な財務にこだわるのではなく、長期の成長に焦点を合わせてください。
私にとっては3つの重要なポイントがありました。
①カスタマーサービスとコミュニケーションに関して。
ジェロームの取り組みは素晴らしいです。何をしているかについて詳しく説明しているのを聞いてとてもうれしく思いました。数年後には驚くべきものになると信じています。
テスラがライセンス供与をするかどうかは少し懐疑的です。
ただテスラはEV生産でも、自動運転でもテスラと本当に競争できるレベルの企業は、もはや存在しないことに気づいています。
テスラは将来的にEV産業、自動運転産業で(準)独占的な位置を占めるでしょう。そうなれば、テスラのサイズとパワーは巨大なものになり、規制当局の監視に直面することとなるでしょう。
その時点までに、当局に協力的であり、独占志向( "walled garden")とは反対の志向を持っていると認知されている必要があります。
そのエクスキューズのためのライセンシングを行う可能性はあります。政治的な理由でのライセンシングです。
③テスラAIのポテンシャル
このERで私を最も興奮させたのは、テスラのAIのポテンシャルです。将来、AIが世界でどれほど大きな役割を果たすかについて、正確に見積もる手立てはありません。
AIが大規模な産業になるとすれば、最高のトレーニングコンピューター(サービス)と最高のAIチップを揃えた企業は非常に価値を持ちます。
TeslaのAIチップ(Dojo と組み合わせて使用すると相乗効果があるだろう)は、Dojo as a Service となるでしょう。これは莫大な価値を生み出す可能性のある事業部門が、Teslaの一部になることを意味します。
$NVDA の関係者は、テスラがこの領域で何をしようとしているのか、注意深く見守っているでしょう。これはHVACなどよりもはるかに高い成長可能性を秘めていると思います。
おそらく、テスラAI は Energy&Automotive と同様のサイズまで成長する可能性があります。
要約すれば、$TSLA将来への成長投資により、財務結果は予想をわずかに下回りました。しかし、長期投資家にとって心配することは何もありません。
長期のビジョン、生産台数の増加、FSDの進歩、およびAIの成長機会に焦点を合わせてください。
AIデーが待ちきれません!
〇質問者とのやり取り
2つのギガファクトリー建設の影響あるのでは?
↓
それはCapexに現れるもので、マージンには影響しません。
マージンに影響を与える成長のための投資の例:
-新しいスーパーチャージャー/サービスセンターが完全に利用可能となるまでには、ある程度時間がかかること
-ソーラールーフのランプアップの前に、より多くのインストーラーを雇うこと
-人員増強(hiring spree)に先立って人事部門を拡大すること
鋳造機(casting machines)はマージンに影響しますか?少なくともフリーモントのものに関してはどうか?
↓
完全に稼働したら、マージンを改善するでしょう。
I currently use Google Colab - which runs ontop on Nvidia chips in Google Datacentres. They would just need to provide the same with their own chips. This would mean, no shipping required. All in the cloud. The demand for this would be enormous.
— Ashley Rudland (@AshleyRudland) 2021年1月28日
現在 GoogleColab を利用しているエンジニアです。このサービスはGoogleのDatacentresに設置されている、Nvidiaのチップ上で実行されています。
テスラは独自開発したチップを使い、グーグルと同様のサービスを提供することになるでしょう。エンジニア観点からすると、テスラのこのサービスは、比較的簡単にローンチできると思います。これは、EV事業と違いデリバリーなど必要としません。すべてクラウド上で完結するサービスです。私は、このサービスに対する需要は莫大なものとなると思います。
私の周りで、GoogleのTPU をトレーニングに利用している人は誰もいません。ほとんどのエンジニアは、Nvidiaのチップ上で実行される PyTorch を使用しています。
テスラも PyTorch を使用しています。テスラは、独自開発のチップ用にいくつかのカスタムドライバーセットをすでに構築しているはずです。
PyTorch が Nvidiaチップ上で実行される方式もこれと同様です。
このNN計算サービスを、オンライン上で提供するのが、テスラにとっての最善です
そして、PyTorch で NNトレーニング を実行しているすべてのエンジニアが、すぐにこのサービスを利用し始めることは明らかです。
最終的な需要規模を想像するのが難しいほどです。
この部門のマージンも巨大なものになるでしょう。
〇別の方
トレーニングのスピードは大きな問題です。優れたNNはどれも、高品質のデータを必要とし、そのトレーニングにはまだまだ長い時間がかかります。
テスラのサービスが、5倍~10倍のNNトレーニング時間の短縮を可能とするならば、劇的なものになるはずです。
DaaS (Dojo as a service)は、NvidiaのNGCのようなものです
NVDA出身のARKのアナリスト↓
"We think Dojo could be the world's best AI training computer..we might offer it to others as a service. Dojo could be a business line by itself." –Elon
— James Wang (@jwangARK) 2021年1月27日
Tesla just entered the AI hardware business. 🤯🤯
「Dojoは世界最高のAIトレーニングコンピューターになると思います。サービスとして他の企業に提供するかもしれません。Dojoはそれ自体がビジネスラインになる可能性があります。」 – イーロン
テスラは「AIハードウェア事業」に参入したといえます。いうなれば
cloud AI as a service
すなわち、クラウドAIaaS です。AI /ニューラルネット・クラウド・プロバイダーと言ってもいいです。またそれはAWSの AIサービス版ともいえる存在になるでしょう。
↓
また業界の他のプレイヤーへ「Dojo ニューラル・ネット・トレーニング」をサービスとして提供する可能性もあります。
イーロンはバッテリーデーで、FSDは遠い未来に最終的にはコモディティ化されると言っていました。Robotaxisサービスを提供しながら、FSDのコモディティ化を、収益チャンスにすることは理にかなっています!
テスラに起こっている恐怖の「無限スクイーズ」(フラグです)
テスラが節目の800ドル(分割前4,000ドル)を越えてきて、改めてARKのキャシー・ウッドの慧眼を称えたいと思います。
ターシャさん結婚して下さい(違)
史上最高値からアフターも含めてさらに10%上昇した日に、こんな記事を書きます。
天井フラグ感満載なのですが、長期で持つ人には下がってもあんまり関係ないと思うので書かせていただきます。
今日は他の株もみんな上がっているので目立たないですが、昨日のように他のメガキャップグロースが大きく下げている中でも、日中にほとんど買い場を作らずに、しっかり上昇してしまう最近のテスラの株価の動きは明らかに異様です。
こんなツイートがありました。
In my years and years of trading stock, I've never seen anything like what $TSLA is doing. No dips. No concern for valuation. No gaps. No lightening of volume buys. No concern for anything. Hits PT's within days vs. months. It's very unique for sure.
— squawksquare (@squawksquare) 2021年1月6日
「マーケットの状況にほとんど左右されず淡々と上がり続ける、こんな光景見たことない!」。
もっともだと思います。しかも出来高もさほど大きなわけでもなく、奇妙な静寂の中で株価だけが淡々と上昇しているのです。静かな買い圧力が、常にわき続けてくる感じです。
この史上最高値の水準でだれが買ってるんだ?
しかも小型株ではなくて、時価総額80兆円近い株です。この後におよんでロビンフッダーが買い上がっているのでしょうか?彼らにそんなパワーがあるのでしょうか?
I believe this is the "Infinity squeeze" of active funds still effectively short TSLA compared to their benchmark.
— 𝗧𝗲𝘀𝗹𝗮 𝗙𝗮𝗰𝘁𝘀 🔋 (@truth_tesla) 2021年1月7日
Up to ~25% of the Tesla float has to be bought by them: ~55% more than the 16% passive index funds acquired on S&P 500 addition.https://t.co/xQzB0bAtl3
この疑問に一定の答えを与えているのが「テスラ・ファクツ」さんです。
この方は超絶クレバーな方で、「ゲーリー・ブラック」さんと並び、テスラ・ウォッチャーの中でも最高位レベルに位置するお方なので、まだの方はフォローを推奨します。
テスラ・ファクツさんはこの現象に「無限スクイーズ」の名を与えています。
「無限スクイーズ」というワードが最初に使われたのは、下記の時だと思います。リアルタイムで経験してないので、詳しくは知りませんが。。。
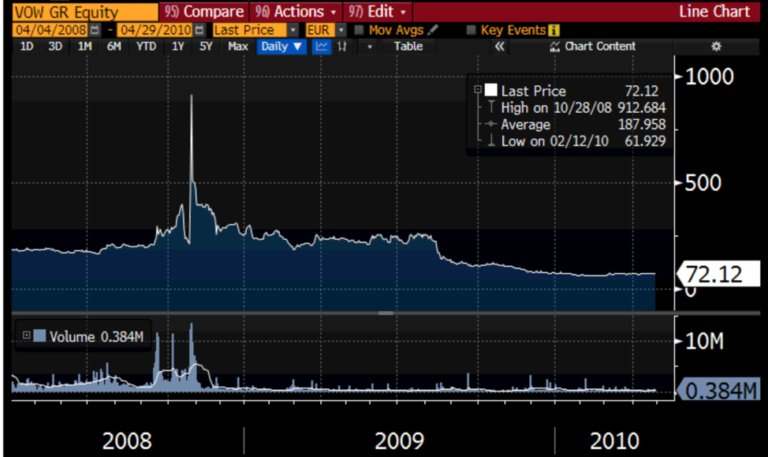
こんな感じですね。注意してもらいたいのは、これは対数グラフなので、メモリはゼロから1,000まで刻まれてます。株価が70ドル近辺から910ドルまで一瞬だけテンバガーしてますね。
これは経済危機のあとで、VWのショートが溜まりまくってる状況で、ポルシェがVWのステークを拡大するとアナウンスして、それが一気に巻き戻された時の現象です。
ショートが溜まっている状況で、フロートが極端に少なくなると発生する現象だといえます。
そもそもショートは玉を借りてきて売り建てするわけですが、そうするとフロートはカウント上増えることになります。
ショート・ポジションをクローズすれば、借りてきた玉を返済することになるので、その逆でフロートはカウント上減ることになります。
この時は一斉に巻き戻しが起こったがゆえに、結果的に市場から売り手が全くいなくなってしまって、マージンコールも巻き込んで、こんなことになってしまったんですね。
以前記事にしたように「ゲーリー・ブラック」さんは、株価が$450の時点で、S&P500組み入れに際し、インデックスファンドの買いその他もろもろが、株価を押し上げる現象をさして、「インデックス・スクイーズ」というワードを使いました。
でゲーリーさんは、株価が12月18日に、最終的に$695ドルまで押し上げられる過程を詳細に分析し、組み入れ前後までの株価動向を当てまくったわけです。
そしてその過程で「テスラ・ファクツ」さんや他数名により、さらに上位版の「無限スクイーズ」の可能性が指摘されていました。
その時の主なトピックはベンチマーカーでした。
インデクサーは18日の終値で買わなければならないので、その値段がいくらであっても買うだけです。またトラッキングエラーが怖いので、彼らは前もって買うこともさほどしません。
インデクサーと違って、ベンチマーカーは前もって買うことができましたが、出来高から推定して、ベンチマーカーの買いは、結局ほとんどありませんでした。
で買ってたのは短期の個人投資家やヘッジファンドばかりでした。ベンチマーカーはほとんど様子見していたのです。
しかし組入れ発表時点では1パーセント強に過ぎなかったテスラのウエイトが今や2パーセントに迫ろうとしています。
仮にあるアクティブファンドがテスラを一株も持っていないとすると、組入れ時点で695ドルで、現在が830ドルということは、その分だけすでにベンチマークに負けていることになります。
別の言い方をすれば、ベンチマーカーである限り、ベンチマークの組入れ株を、自分のファンドで持たないということは、その株を事実上をショートしているのと同じ効果を、彼らのパフォーマンスにもたらすのです。
Only 10% of big actively managed funds owned any TSLA in the study below, many and @garyblack is estimating their size at $8t, which at 1.82% S&P 500 weight means ~180m shares and $135b of TSLA buying - about 24% of the float.https://t.co/yrL76IJGs8
— 𝗧𝗲𝘀𝗹𝗮 𝗙𝗮𝗰𝘁𝘀 🔋 (@truth_tesla) 2021年1月5日
12月上旬の時点で、およそ8トリリオンあるベンチマークファンドのうち、テスラを持っているのは10%に過ぎませんでした。
彼らは組み入れ後にボチボチ買い始めればいいと考えていたことになります。もしくは明確なカタリストがなかったがえに、買う理由を作れなかったといってもいいでしょう。
バリュー志向なベンチマークファンドに、ブルームバーグ端末の予想PER見せてから、テスラ買えといっても無理な話です。そもそもテスラに全く興味なかったでしょうし。
これがキャシーがアークを作った理由でもあるんですが。
ところが年明けから
メイドインチャイナモデルYの発表で、ショールームに中国人が殺到! とか
プレオーダー1日で10万台! とか
デリバリーがが年間50万台達成! とか
モルスタの1年前まで「目標株価$10」だった野郎(アダム・ジョナス)が、ここのところ急に手のひら返して「目標株価$810」へとさらに上方修正
RBCのアナリストの「私が間違ってました、テスラさんごめんなさい」宣言
とか、
カタリストが相次いでしまいました。
これらはテスラウォッチャーには当たり前のことでしたが、興味ない人達には衝撃的なニュースでした。
しかもデリバリーの数字を受けて、Q4の決算は超弩級のものになることは目に見えています。
これでベンチマーカーたちにはいよいよ買わない理由(顧客に説明できるレベルのまともな理由)がなくなってきました。
いよいよ焦ってきているわけです。
このままベンチマークから劣ってしまっていては彼らは今年職を失います。
これ以上の負けを回避するためには、テスラをオーバウェイトにせずとも、せめてイコールウエイトにする必要があります。
2/
— 𝗧𝗲𝘀𝗹𝗮 𝗙𝗮𝗰𝘁𝘀 🔋 (@truth_tesla) 2021年1月6日
These Tesla "benchmark shorts", up to 24% of the float, are much larger than equity shorts, which are only 6% of the float (much of which are synthetic shorts related to convertible notes).
株価が$830とすると、テスラのSP500に占める割合は、約2%です。ベンチマークファンドの規模は8トリリオン以上と推定されます。
で、その買い圧力を、完全希薄化ではなく、実際に流通しているフロートで換算すると24%前後です。
つまり、ベンチマーカーたちが、もしSP500とイコール・ウェイトのテスラ株式を保有しようとしたら、フロートの24%買わなきゃいけないのですね。
またテスラの現在のショートインタレストは、フロートの6%です。これはさほど大きくはありません。
合計すると、で30%の潜在的買い圧力がたまっていると考えることができます。
そこで現在のフロートを、どのプレイヤーがどれほど保有しているかを推定してみます。
①インデクサーはもう買い終わっていて、16%のフロートを市場から奪っていっていきました。インデックスファンドの定義上、彼らはテスラがSP500から除外されない限り、もう絶対に売らない。つまり彼らの目標株価は無限大www。
②またテスラのオプションマーケットは通常の個別株オプション市場の10倍の規模があり、デルタヘッジ需要でマーケットメイカーは常にフロートを奪っていきます。しかもこの需要は、原資産のテスラ株式の値段が上がっていくほど増えていきます。この算定は非常に難しいですが、およそ20%~25%だと思われます。
③さらに、熱狂的なイーロン・ファンクラブの連中は目標株価最低でも10,000ドルとか、2040年まではイーロンと心中とか言って、ちょこちょこ買い増すばかりで、1株も売ってくれません。値段が上がれば当然売る人はでてくるのでなんとも言えませんが、コアなファンクラブの保有玉は、フロートの10%~20%だと思われます。
④長期で保有するファンドはテスラのポテンシャルに注目して昔から持ち続けているので、キャップ制約がかからない限り、なかなか売りたがらない。これがおよそフロートの30%はありそう。
⑤ショート玉でかさ上げされていたフロート玉もカバーされちゃって、サーキュレーション総量がそもそも減らされちゃっている。
⑥インクルージョンプレイで買い上がっていたヘッジファンドは、12月18日当日やその後の数日で全部売り切ってしまって、売り玉はスッカラカン
大げさに言えばまともな売り手が一人もいないという事態に突入してしまった可能性があります。
特に②と③はテスラの株式に特有な現象です。こんな株他にないです。
①~④を足し合わせて、さらに。。。
⑦ここにベンチマーカーのイーコールウェイトにするための買いの24%を加えると・・・
なんということでしょう!合計が100%を越えてしまいました。
どういうこと?
市場に出回っているテスラ株式買いつくしてもまだ足りないってこと?
どうしましょう。新たに売ってくれる人を探してもあんまり、見当たりません。
これこそまさにインフィニット!無限スクイーズです。
So the thing is, TSLA is still well below fair value as far as I'm concerned, and it can run up to fair value as long as it wants to.
— 𝗧𝗲𝘀𝗹𝗮 𝗙𝗮𝗰𝘁𝘀 🔋 (@truth_tesla) 2021年1月6日
Active index fund buying is a big question - but trading volume is still low, net accumulation is maybe 5m shares per day ... 195m needed ...
多くの熱狂的テスラホルダーにとって、現在の価格はフェアバリューよりも大幅に下であること。
ベンチマーカーが200ミリオンのフロートを必要としているとしても、出来高から推定して、1日当たりせいぜい5ミリオン集めるのが関の山。年明けから今まで50ミリオン集めていればいいほう。
目標の4分の1。。。
後はもう言わなくてもわかるね。
私ですか?
まあ10, 000ドルいったら少しは売ってやってもいいかな。
なんせファンクラブなもんで!!(爆)
(フラグです)
テスラコミュニティに学ぶテスラのエネルギービジネスの可能性
HOW BIG COULD TESLA’S ENERGY STORAGE BUSINESS BE ?
— JPR007 (@jpr007) 2021年1月8日
1. We have estimated that the size of the Global Energy Storage Market using current storage battery technology would be around $3.65 trillion per year
- the market price of Energy Storage Systems is assumed to be $500 per kWh
テスラのエネルギー蓄電事業はどれくらいのポテンシャルを持っているでしょう?
現在の蓄電池技術を使用した、グローバルなエネルギー貯蔵市場の規模は、年間約3.65トリリオンです。
ここでは「エネルギー貯蔵システム全体での価格」は、kWhあたり500ドルと想定されています - the market price of Energy Storage Systems is assumed to be $500 per kWh
テスラがこの事業の20%の世界市場シェアを獲得すると仮定します。
するとテスラの売上は年間で730ビリオン(70兆円以上)になるはずです
粗利益率を25%と仮定すると、粗利益は年間182.5ビリオンになります
R&Dコストと間接費は、テスラの損益計算書でカバーされていると仮定します。
テスラの営業利益は年間年間182.5ビリオンになります
純利益は年間146ビリオンになります(実効税率20%とする)
するとこのセグメントによる、時価総額の追加分は
-10倍の株価収益率で1.46トリリオン
-20倍の株価収益率で2.92トリリオン
になります。
(オートビッダーなどのグリッド関連に基づく収益は考慮されていないことに注意→もしくはグリッド関連のハイマージン事業も含めての25%のGMレートなのかもしれない)
1/ I like the structure of your analysis JPR - a few thoughts:
— Matt Smith (@MatchasmMatt) 2021年1月8日
$500 / kWh is roughly the price of existing powerwalls. Megapack pricing is closer to $300. In order to get the penetration you are targeting here, I do believe pricing would have to come down much further still.
論点を補足します。
500ドル/ kWhという価格は、既存のパワーウォール並みの価格です。
他方でMegapack関連の価格設定は300ドルに近いです。
市場シェア(20%)を得るためには、価格をさらに下げる必要があります。
かりに全体のコストが 100ドル/ kWh (ラッキングコスト、設置費用などを含む総コスト)になれば、真に革新的でディスラプティブなビジネスとなるでしょう。
その場合には、25%のGMは難しそうです。簡略化のために 12.5%のGMとなるとします。
するとJPR007さんの想定の 約1/10のマージンになってしまいます(価格が5分の1になり、マージンレートが半減しているので)。純利益は年間15ビリオンほどになってしまいます。株価収益率20倍とすると、ビジネスの価値は約300ビリオンにしかなりません。
私は、エネルギー事業のプロダクトの製造マージンが低くても、それは理にかなっていると思います。その上でエネルギー事業は、10%代後半~20%のGM率を達成できると考えています。
エネルギー製品事業の次に、テスラによる「定期的なエネルギーサービス(recurring energy services)」の可能性を考慮します。
パイロットプログラムでは、バッテリーが生み出す収入が、月額で約$ 8 / kWh でした。しかし、この値段では、テスラが事業を大規模に展開するためには、サービス需要者にとって経済的訴求力がありません。またテスラはこれらのサービス需要者からの収益をアセット・オーナー(たとえばneoen)とシェアする必要があります。
このビジネス(RES)が真にディスラプティブなものになるためには、このビジネスにおけるテスラの最終的な取り分が 月額で 約$ 0.50 / kWh になる必要があると思います。
仮にテスラが 1.5 TWh の蓄電容量を保有し、その出力を10年間維持するとします。すると、設置された分散型バッテリー容量(installed distributed battery capacity)は 15TWh に達するでしょう。
その規模までスケールできれば、これは年間90ビリオンの営業利益を生み出します。
税金を考慮したのちの、純利益を40倍(PE40)すると、約$ 2.7トリリオンとなります。このビジネス価値が、上記のエネルギー製品製造によるビジネス価値に追加されます。
上記の分析からは、多くのニュアンスが欠けています。現実には、設置されたフリートのすべてが、このレベルの収益を生み出すわけではありません。それでもサービスからのマージンのほうが、ハードウェアのマージンを上回ると思います。
(2人が見ている未来はそんなに違わない。エラボレーションの仕方が違うだけ)
Gross Margins are primarily a function of management decision
— JPR007 (@jpr007) 2021年1月9日
1. I expect Tesla to seek Gross Margins in the range of 25~30% on the average for their Automobile business pic.twitter.com/tzCfUoNv5S
粗利益率は、経営陣の決断に左右されます。
テスラはEV事業で平均25〜30%のグロスマージンを追求すると思います。
「生産規模拡大」と「数々の技術革新」と「独自設計のバッテリーの生産(製造が社内か社外かに関係なく)」とを組み合わせることで、テスラは2031年までに「低コスト生産が可能な自動車メーカー」になっていると思います。
この観点から、粗利益率は25%ではなく30%に達すると期待しています。
業界で一番コスト競争力があり、EV販売から30%の粗利益率を得ているとします。生産するバッテリーも当然それに準じたコスト競争力を持っているはずです。それらのバッテリーを粗利益率30%未満の別の高額商品(big-ticket items)すなわち、別の事業に投入することには意味がありません。
もしそれをするならば、「EV販売」が「エネルギー貯蔵システムの販売」を補助することになります。そんなことをする理由はありません。
「バッテリーセル生産」において、最低コストで生産できる生産者は、「バッテリーエネルギー貯蔵システム」でも最低コストで生産できるはずです。
その場合にEVビジネスにおける市場シェアと、バッテリー競争力からもたらされる収益性は、エネルギービジネスにおいても同様の結果をもたらすでしょう。
上記の図が示すように、獲得可能な利益のプールにおいて最大のシェアを持つこと。このために「市場を占有する」必要はありません。美味しいところをいただくために、市場を完全支配する必要はないのです。
あなたの利益ポジション(profit position)に明らかなプラスの作用をもたらさない場合には、自然な価格設定レベルを下回った値段設定をして安売りしても、それが報われることはありません。
例えばFDASの販売それ自体は、EV販売とはまったく別のビジネスです。
同様に、Electricity as a Service すなわち EaaS から別に売上を得る場合にも、それは完全に別のビジネスと考えるべきです。たとえEV事業が、エネルギー事業の成立のためのツールとハードウェアを含んでいるとしてもです。
テスラが事業を大規模化する際に、粗利益率は25%になると確信しています。そうでなければ、この事業を拡大する意味がありません。
〇 質問者
将来の蓄電池システムの価格が、kWhあたり500ドル に設定されているのはなぜですか?
モデルSのバッテリーのコストは、現在 kWhあたり100ドル です。4680セルで kWhあたり60ドル に下がるとされています。それで他の400ドル以上は何のためのコストですか?
↓
kWhあたり500ドルという数字は完璧な数字ではありませ。テスラの損益計算書から導き出しました。実はこれは特定する(pin down)のが最も難しい数字です
↓
ただしストレージシステムにかかるコストはセルだけではないため、kWhあたり100ドル という数字は明らかに適切ではありません。
↓
例えばインバーターにも費用がかかります。3.5kWhのソーラーモジュールの場合は1000ドル~1500ドルのコストがかかります。ただしソーラールーフ、バッテリーストレージと必要なインバーターの関係の計算方法がわかりません。
またインバーターのサイズは、家庭用なのかどうか、バッテリーの充電と放電の頻度、速度はどれくらいなのかによっても異なります。
またインバーターのコスト自体をどれだけ下げることができるかも問題です。
よって、現時点でのおおよその見積りの数字として、500ドルを使用しました。
↓
正しい答えは100と500の間のどこかにあるように見えます。それを特定するには客観的で独立したデータポイントが必要です。
〇 別の人のコメント
テスラのエネルギー事業は、いつかテスラのEV事業をはるかに凌駕すると思います(Tesla energy will far eclipse Tesla automotive)。
エネルギーははるかに大きな市場であり、混乱の危機に瀕しています。化石燃料の時代が始まって以来、現在のレベルの変化はありませんでした。原子力はコストがかかりすぎます。水力は地形に依存しており、限定的です。「ソーラー+バッテリー」という組み合わせは、スケーラブルで、地球上どこでも展開できます。
テスラコミュニティに学ぶテスラのバリュエーション
https://twitter.com/jpr007 テスラ株価分布予測

2021年のテスラの株価はどうなるでしょうか?
2021年1月4日現在、株価は744.49ドルで史上最高値です。これは過大評価でしょうか?
私の2031年までの株価レンジ予測からすると、
PE10x = $657 per share= 1株あたり 657ドル
PE20x = $1,315 per share= 1株あたり 1,315ドル
すなわち現在の最高値水準は、2031の収益を現在価値に割引いたモデルで評価すると、PEで11.3倍を意味します
https://twitter.com/jpr007 PEプロジェクション(対数グラフ)
ある企業が年率15%を超えて成長している場合は、将来を見据えて、その企業価値を評価する方が実践的です。将来価値を算定したら、それを現在価値に割引きます。
https://twitter.com/jpr007 2031年におけるテスラのIS

将来におけるBEV市場の規模、市場シェア、製品価格を仮定します。
それにより将来の純利益を導き出します。
https://twitter.com/jpr007 バリュエーションの前提の数字
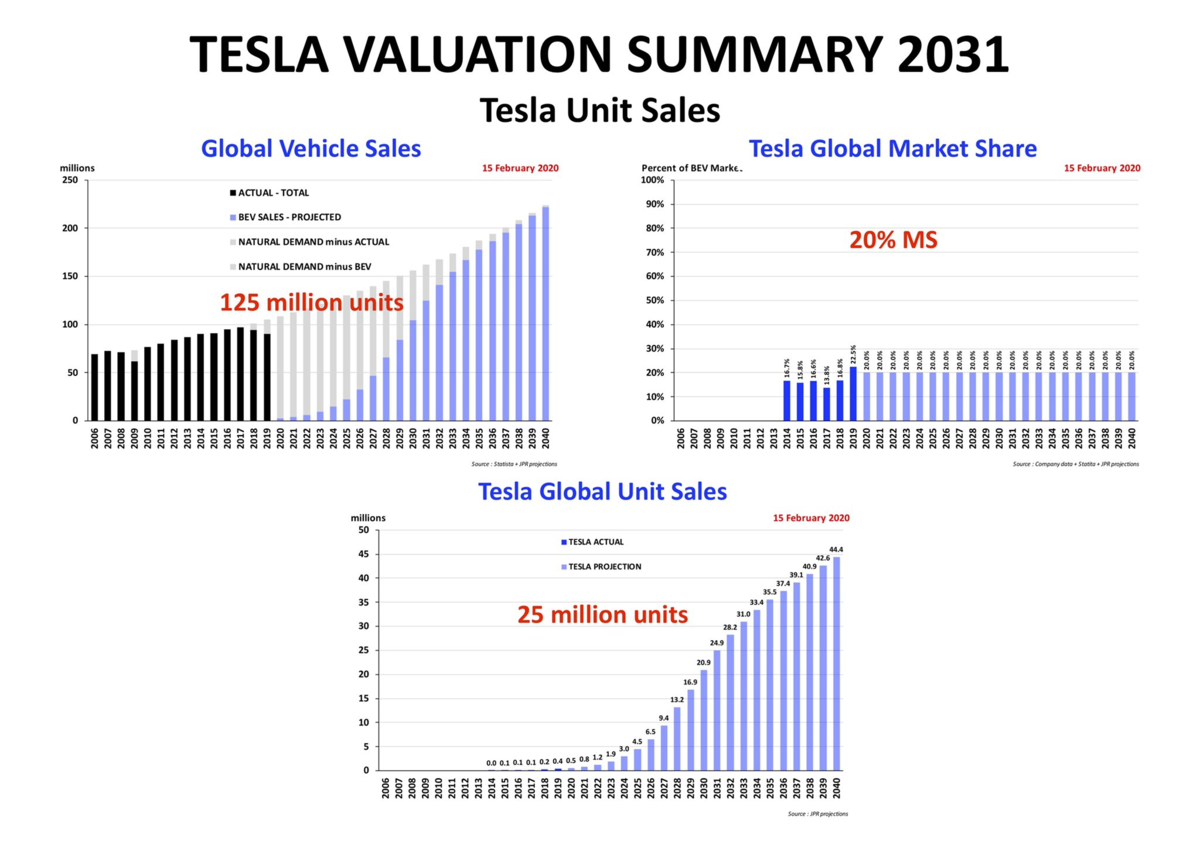

考慮すべきセグメントが複数ある場合、まとめて足し合わせて評価します。
その合計値を1株あたりの将来価値とみなします。それを現在価値に割引きます。
これにより、「現在の株価」が将来の見通しをどの程度評価しているかを把握できます。
投資家にとって重要なこと。
-将来の売却価格、その可能性
-今日の購入価格
これだけです。
https://twitter.com/jpr007 時価総額の最大値のプロット
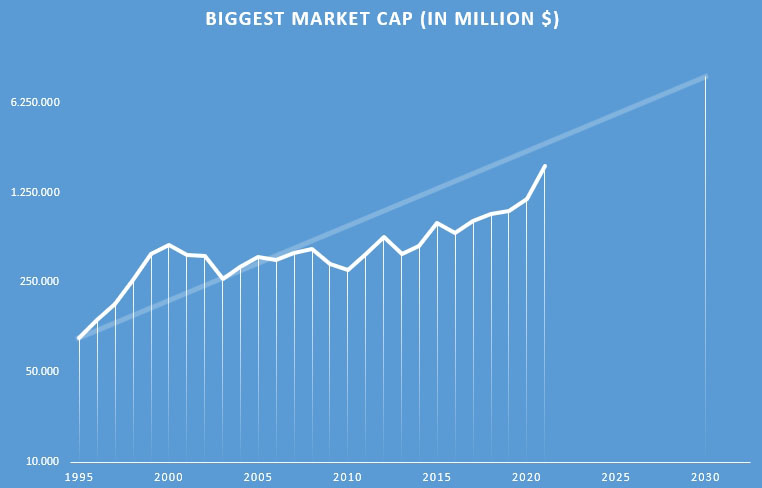
2030年にテスラが5兆ドルのバリュエーションを与えられていても驚きません。
私には対数的増加( logarithmic growth)のように見えます。
この傾向を続ければ、2030年に最大の時価総額の企業は6トリリオンを与えられていてもおかしくはないです。
別の方
My Xmas gift for you: A #Tesla valuation that arrives at a share price of 2'181 - as of now! Seriously.
— Roger Rusch, ceo plus (Leadership, Teamwork, EVs) (@ceo_plus_ch) 2020年12月23日
Here are my (admittedly rather simple) assumptions and the math (thread):
1/6 pic.twitter.com/NiV9dKdpsM
https://twitter.com/ceo_plus_ch 5年間の予測バージョン
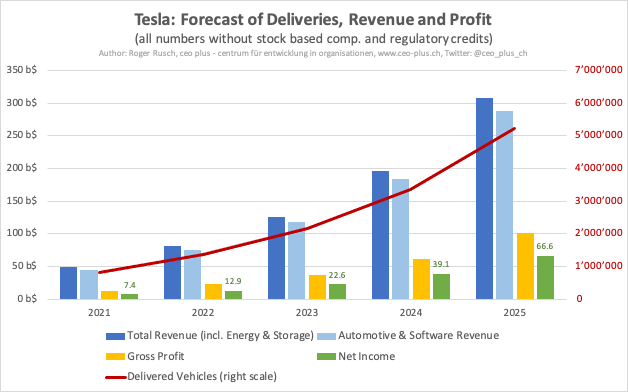
a)前提
a.1)自動車部門
テスラの販売台数は、テスラのEV市場シェア、テスラの生産能力に依存します。これらとテラファクトリー建設計画を考慮すると、今後の販売台数推移は
2021 0.83m
2022 1.38m
2023 2.15m
2024 3.35m
2025 5.23m
で推移すると考えます。
ASP :2020年に52kだが、1k/年 の減少率と想定
粗利益率 :23%(Teslaはマージンが高くなると製品価格を下げるため、増えない想定)
a.2)ソフトウェア(主にFSD)
2020年の車両1台あたり9k @ テイクレート30%
販売価格は 2k /年 の割合で増加し
テイクレートは 2.5%/年 増加するとします。
ソフトウェアは、基本的に売上原価はありません。つまり売上=粗利益です。
a.3)エネルギー
自動車と同じ成長率を想定
粗利益率:10%
a.4)OpEx(除くSBC):
償却コストは2020年には2.3bで、年率20%増加
R&D / SG&Aは2020年に1bで、年間20%増加
b)2025年のデリバリーと財務予測
-デリバリー:5.23m
-ASP:47k
-EV売上:245.8b
-ソフトウェア(FSD)売上:42.2b
-エネルギー事業売上:19.7b
-粗利益:100.7b
-純利益:66.6b
-EPS 49.98ドル(3%希薄化/年 を想定)
c) Valuation
- 2025のEPSの現在価値:31ドル
-理論PE 70.3 を想定
PEG 2 x EPS CAGR 2026-2030は35.15
(5年後のPEを現在のEPSに想定)
-2020年12月現在の理論株価:2,181ドル
↓
エネルギー事業や、販売台数増を考慮しているので、ゲーリーさんの見積もりよりはだいぶ高い。
しかしソフトウェア収入がFSDだけであり、またロボタクシーなどは考慮していないので、実現可能性が高い保守的な想定だといえる。
販売台数は5ミリオンだし、十分達成可能な台数である。
https://twitter.com/ceo_plus_ch

2030年にはEVが現在のICE車以上の販売台数水準(年間9,500万台)を達成するとしている人が多いな。
テスラは2,000万台でシェア20%強予測
市場規模、テスラのシェアのどちらの変数が変わっても将来価値が大きく変わってくることには留意。
ただEV市場の予測はある程度見積もることができても、テスラのエネルギー事業の規模を見積もることは相当に困難。本格展開には至っていないかもしれないし、EV事業をしのぐ巨大ビジネスとなるポテンシャルを見せているかもしれない。
テスラ Q4決算展望(注意:わかりにくいです)
※この記事はモバイルで見ると、さらに意味が分からない可能性があります。
S&P500組み入れ完了、MICモデルYの発表など、順調にカタリストをこなして、テスラの株価もそれらを反映して好調を維持していますが、Q4のデリバリー台数の速報を受けて、各所でQ4決算見込みのアップデートが行われています。
その中でも
(@ICannot_Enough) https://twitter.com/ICannot_Enough
のジェームス・スティーブンソンさんのツイッター投稿をもとに決算を展望したいと思います。
https://twitter.com/ICannot_Enough

コロナ禍の2020年でも、テスラの販売台数増加を止めるものはなかった。
今回のQ4決算は当然好決算が予想されますが、ちょっとトリッキーです。
Q4の決算はEPSは一見すると超絶サプライズに見えるものが出てくる可能性があります。
しかし、これは現在はBSに2ビリオン分のっかっている「繰延税金資産の戻り入れ」による特別利益による部分が大きいです。その部分を除外すると、普通に好決算となりそうです。
投資判断的には、リカーリングな収益のみがカウントされますので、「繰延税金資産の戻り入れ」のような一時的な収益は重要視されません。
ただヘッドラインに反応して、一時的に株価が大きく変動する可能性はあります。
決算で重要なEPSを予想する場合、完全希薄化後のノンGAAP EPS (fully dilutede non-GAAP EPS)を用いるのが通例なので、それに照らすと。。。
ストリート予想EPS $0.93 ですが、
ジェームスさんの予想EPS $1.06 となり、14% のビートとなります。
普通の好決算ですね。ジェームスさんの予想に基づくならば、決算発表が株価のカタリストになることはあまりなさそうです。発表までに織り込む動きになると思われます。
I have updated my $TSLA forecast with the reported Q4 deliveries.
— James Stephenson (@ICannot_Enough) 2021年1月3日
Q4 looks like a ~$2.3B GAAP profit to me, including an unusual ~$1.6B benefit (deferred tax asset from prior years' losses) that will surprise many.
Adj. EBITDA is highlighted below for better comparability. pic.twitter.com/hti3KMwzFk
https://twitter.com/ICannot_Enough

全体の売上は四半期ベースで、初めて10ビリオンを越えて来ます。
つまり四半期売上高が初めて1兆円を超えるということです。そのうちオート部門の売上高は9ビリオンです。
さらに目を引くのが 2021Q1 の売上高予想です。Q1はオート売上にとっては各社ともに鬼門で通常は売上を落としますが、その中でもテスラは販売台数を維持し、売上を伸ばすことが予想されています。
また、Q4の GAAP 純利益はなんと$2.3ビリオンが見込まれます。これは前年同期比で22倍ですね。この利益水準には、多くの人が驚くかもしれませんが、これはあくまで一時的なものです。
この中には特別項目として、$1.6ビリオン規模の「繰延税金資産戻り入れ益」が含まれているからです。これは上述のように投資判断的にはカウントされません。
これを除外すると$0.72ビリオンとなり、前年同期比で6.89倍の利益増となります。すごいです。利益が7倍になってるので、今までに株価が7倍になっていても全くおかしくないですね。
ただハイライトしてある、Adj. EBITDA を見た方が、業績の推移がよくわかります。 3Qと4Qと連続でEBITDAが急拡大しているのがわかると思います。このトレンドはもう止まりません。この拡大が続く限りは株価の上昇も維持されるでしょう。
また予想EPSの計算方法ですが、以下となります。
$1.26
— James Stephenson (@ICannot_Enough) 2021年1月3日
$2.324B GAAP Earnings $2.46 EPS basic
+$0.226B addback Elon's SBC
+$0.239B addback All Other SBC
$2.788B Non-GAAP Earnings $2.95 EPS basic
-$1.600B Deferred Tax Asset ($1.69) EPS basic
$1.188B Non-GAAP Earnings excl. DTA $1.26 adj. EPS basic pic.twitter.com/x7Mdi1IJGR
まず「GAAPベース」純利益を「ノンGAAPベース」純利益に戻して、そこからノンリカーリング項目を除外して、完全希薄化後の株式数で割るという手順となります。
ベーシックEPS換算
GAAPベース利益 $2.324B $2.46
イーロンのSBC +$0.226B
その他のSBC +$0.239B
ノンGAAP利益 $2.788B $2.95
DTA分の利益 -$1.600B -$1.69
調整済み利益 $1.188B $1.26
↓
$1.06
(完全希薄化後の調整済みEPS)
→これがストリート予想のEPSと比較される。
このようにして $1.06 という数字が出てくるわけです。
※SBC = Stock Based Compensation = 株式ベースの報酬
※ DTA =Deffered Tax Asset = 繰延税金資産
ちなみに繰延税金資産の概要は以下です。
企業会計では、会計上は損失であったものが、税務上は損失とみとめられず結果的に課税対象となる項目が常に発生します。損金不算入というやつです。
この差異が、将来的に損金として認められる可能性がある場合に、その際の税金軽減効果を見込んで、資産としてBSに積んでおくことができます。
ただ利益が発生しなければ、課税も発生しませんので、軽減効果を受けることができません。よって、今後しっかりとした収益が見込めることが、資産取り崩しの前提となります。
取り崩すか否かの判断は、これは監査法人(テスラの場合はプライスウォーターハウスクーパース)とCFO(ザック)との交渉により決定される項目です。
Q3で行われてもよかったのですが、行われませんでした。Q4は絶好の機会となります。これ以上先延ばしする意味がないからです。
ただし、いかに利益がでようとも、一回の取り崩しは最大80%までというルールがあるので、Q4とQ1の2回に分けて行われると思われます。
https://twitter.com/ICannot_Enough

1台当たりの売上高(ASP)はわずかに低下します。
セールスミックの変化によるものです。
モデル3とYが↑、XとSが↓ なためです。
またモデルYの売上が四半期で2ビリオンを越えて来ました。
自動車部門の売上は、記録的だった3Qを、塗り替えるでしょう。
https://twitter.com/ICannot_Enough

全体のグロス・マージン比率 22.3%
自動車部門グロス・マージン比率 26%
排出権クレジットがない場合、自動車部門のグロス・マージン比率 24.3%
(ARKのブルケースのグロスマージンはオートの粗利が、2024年時点で40%目標)
→これにはFSD、バッテリーコストのさらなる低下が必要
→現状では粗利が30%以上にいかないように、値下げをしているように見える。
上述の「繰延税金資産の戻入れ(The DTA benefit)」 は、
the Provision/(Benefit) for Income Taxes
の行に反映されています。
https://twitter.com/ICannot_Enough
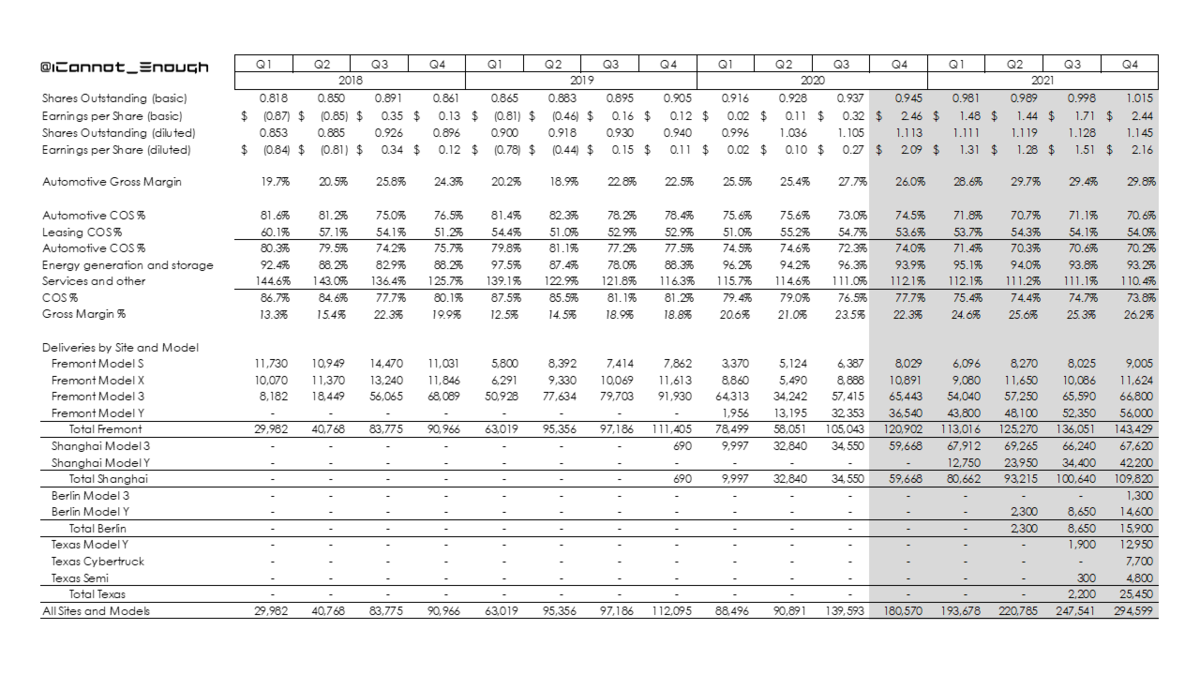
上海のモデルYのデリバリーはQ1から
ベルリンのモデルYのデリバリーはQ2から
オースティンのセミ・トラックとモデルYのデリバリーは Q3から
オースティンのサイバートラックのデリバリーは Q4から
になると予想します。
ベルリンローンチ、オースティンローンチ、サイバートラック、セミとカタリストが目白押しです。
ギガ・オースティンの建設がやや遅れている問題は、そのうち解決すると考えています。
自動車部門の原価低減が進むことで、グロスマージンは2021年を通じて改善していくことでしょう。
↓
(この予想値だと上海のモデルYのデリバリー数は随分控えめですね。 もうちょっとランプアップスピード上がってもいいとおもうけどなぁ。いずれにしてもフル生産は2022年ということか。)
(ベルリンとオースティンも本格的な収益貢献は2022年になりそうだが、生産台数見積りが保守的すぎるかもしれない。)
https://twitter.com/ICannot_Enough
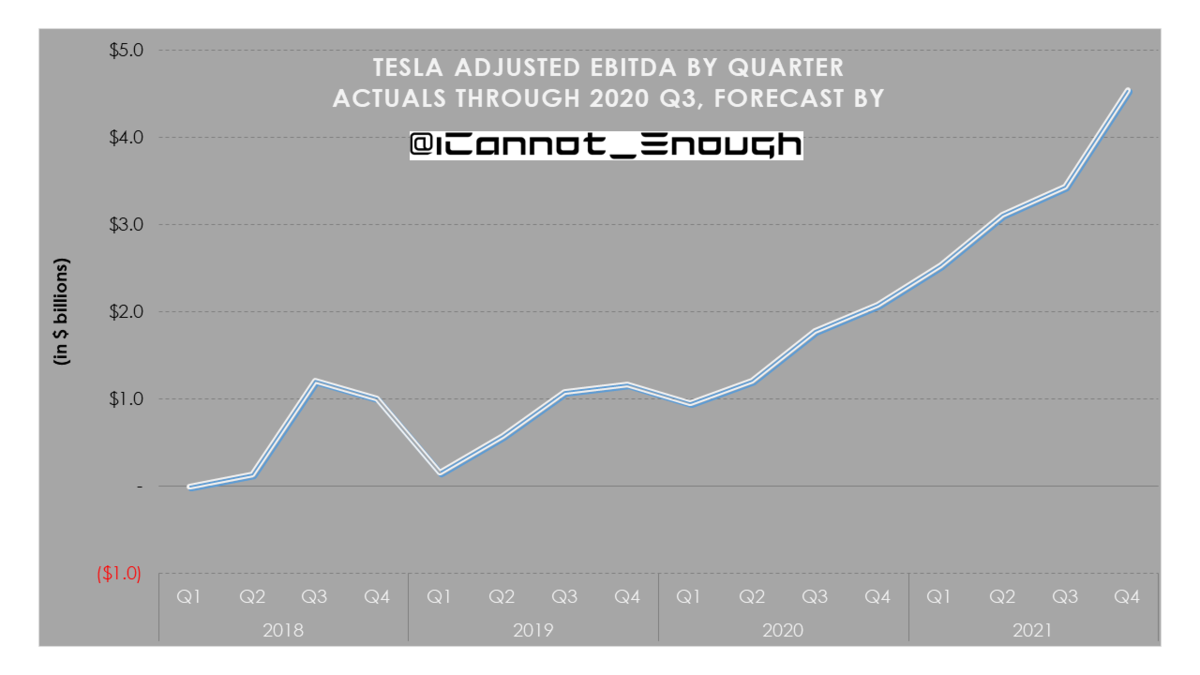
調整済みEBITDAのクオーターごとの推移です。
キレイな右肩上がりの予想です。このトレンドが続く限り、株価の上昇は維持されます。
またこの利益指標が、イーロンの株式報酬付与計画の根拠となっています。
またこの数字には、特別利益のインパクトは反映されていません。EBITDAなので、税前利益をベースに計算されているからです。
https://twitter.com/ICannot_Enough

車種別の販売台数推移です。モデル3の売上が頭打ちなのではなく、単純に生産キャパシティの問題でしょう。 3とYがテスラを支えている構図がはっきりとしています。今年後半には、サイバートラックが3本目の柱として加わってきます。
「モデルSがポルシェをディスラプト」とか、もはやそういうレベルの競争をしているわけではないのです。
https://twitter.com/ICannot_Enough
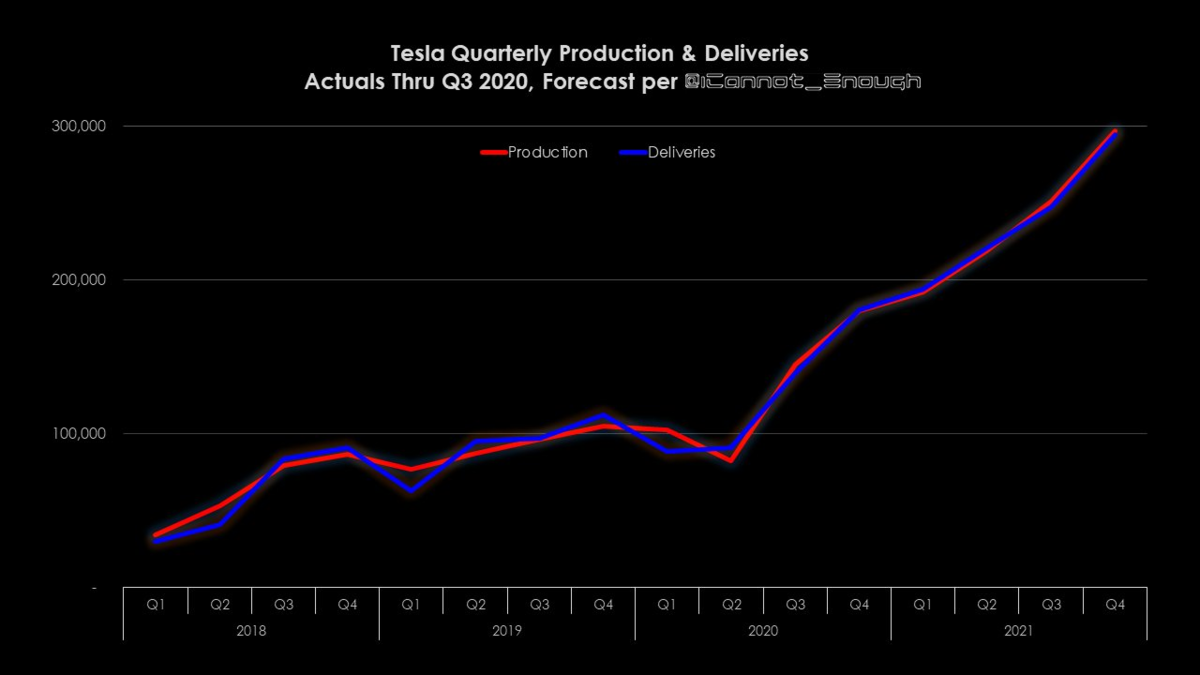
生産台数と出荷台数の差異。テスラは在庫マネジメントも秀逸です。作ったそばから売れていく様子がわかる。
https://twitter.com/ICannot_Enough
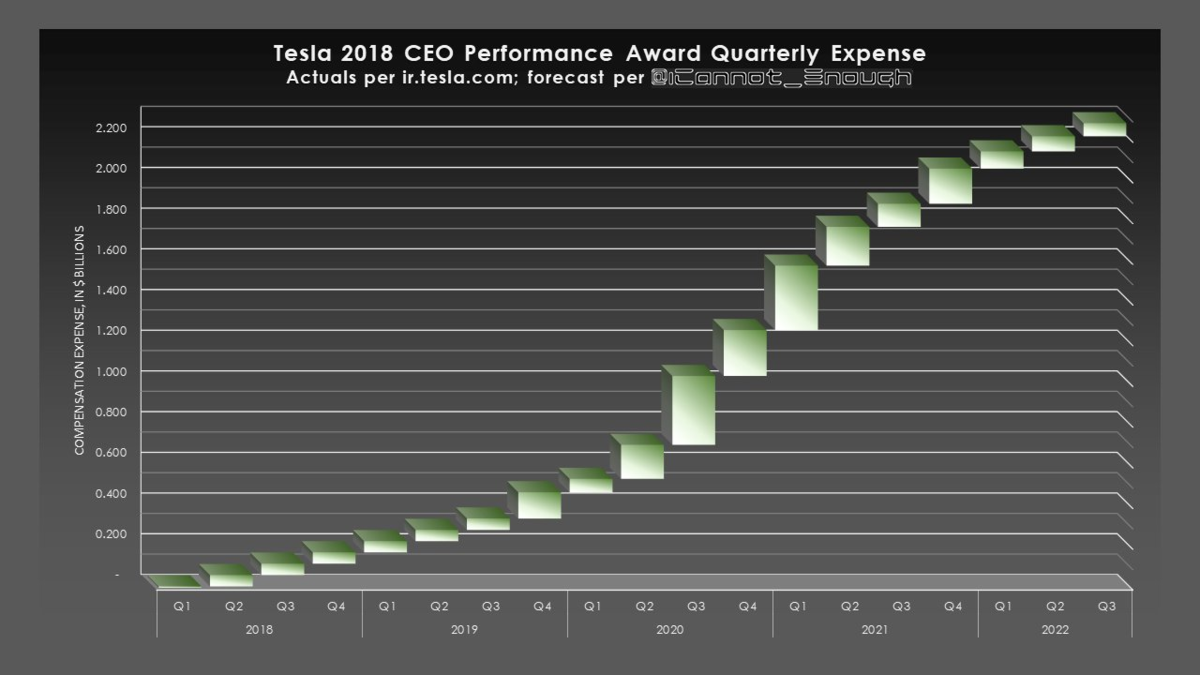
非常に予測が難しい項目です。
おそらくイーロンへのストックオプション付与はこのようなペースで 行われていくはず。
発生主義ベースで計上するので、テスラからの現金支出ではなない点に注意。
また、ロックアップ期間が数年(5年)あるし、イーロンは権利行使してこの株を手にするためにテスラに相応のキャッシュを支払わなければならないので、これらの株がフロートとして市場に放出されるには何段階もステップが必要です。
また事実イーロンは今まで1株も売ってない。
https://twitter.com/ICannot_Enough
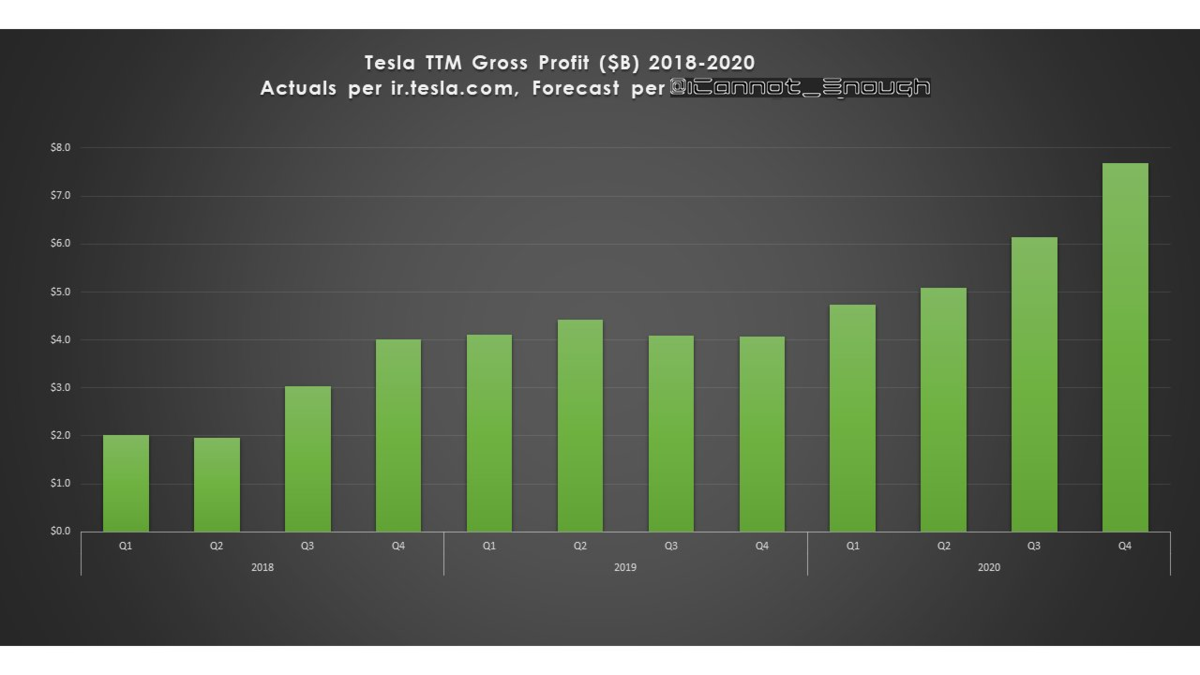
グロス•マージン額が急上昇し始めているのがわかる。この傾向はもう止まらないよ。
https://twitter.com/ICannot_Enough

売上1ドルあたりのセグメント別の貢献割合。
今はオート部門が売上を引っぱっているが、バッテリー供給制約問題が解決されてくれば、エネルギー部門が、急にキャッチアップしてくるはず。
やがては、オートと匹敵するレベルになって、共に大きく成長していくでしょう。
特に Autobidder のポテンシャルはマーケットに全く評価されていないと思う。
またこれらに含まれない新たなセグメントが主力事業になっていく可能性も高い。
ロボ・タクシー、ロボ・フリート、自動車保険、テスラ・アップストアなどなど。
アップルの時価総額を抜くのも10年はかからないでしょう。
もしかして5年かからないかもしれない。
https://twitter.com/ICannot_Enough
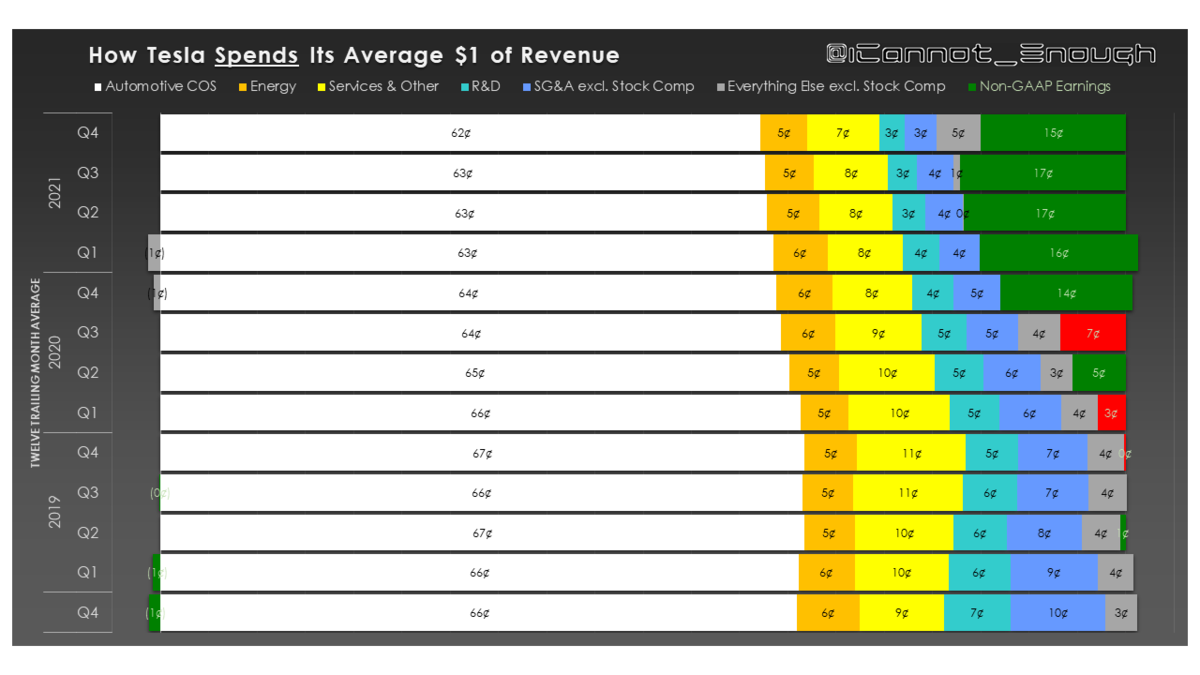
利益として残る部分がこれから安定して拡大していくだろうことがわかる。
もはや利益の増加に、設備投資の増加が追いつかないフェーズの、その初期に入ったといえる。
テスラは将来的にはアップルのように、自己株式を買い戻す選択を迫られていくことになるでしょう。
キャッシュ持っていても使い道がなく、インフレで劣化していくだけだし、負債コストよりも株式コストのほうが圧倒的に高いのだから。
https://twitter.com/ICannot_Enough
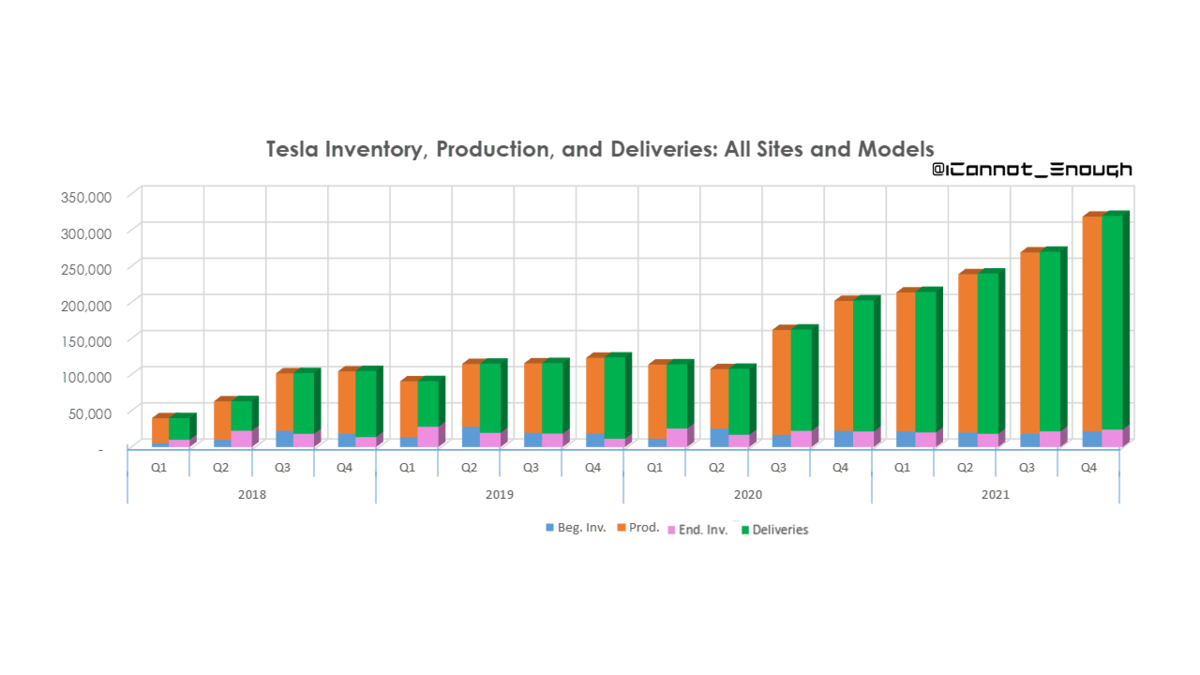
生産、在庫、出荷の推移のビジュアライゼーション。
販売在庫を2週間程度分しかもたいないのは、ロジスティクス的に非常に優秀。
https://twitter.com/ICannot_Enough
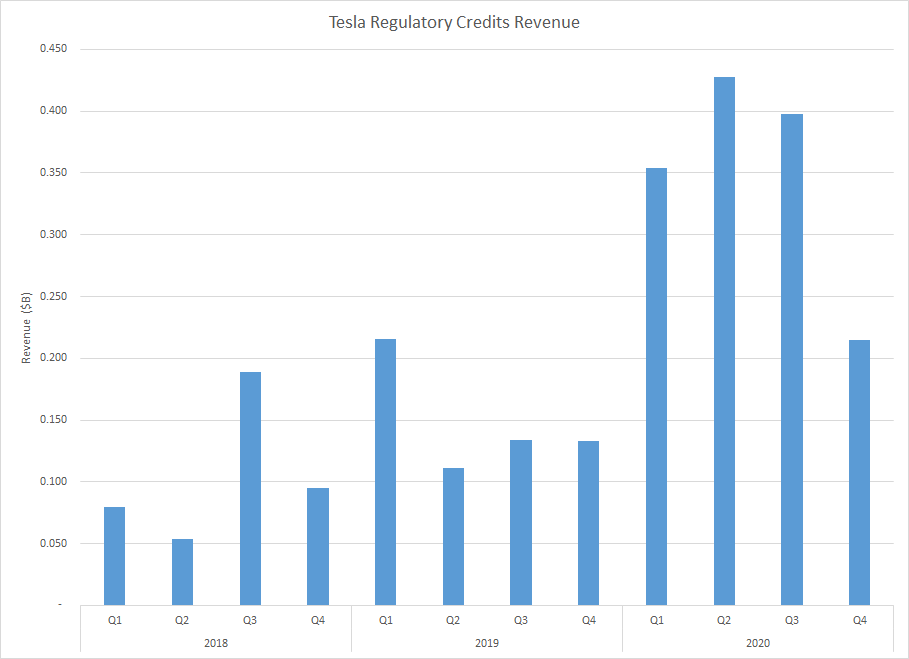
これは将来的に消滅していくが、全く問題ない。
https://twitter.com/ICannot_Enough
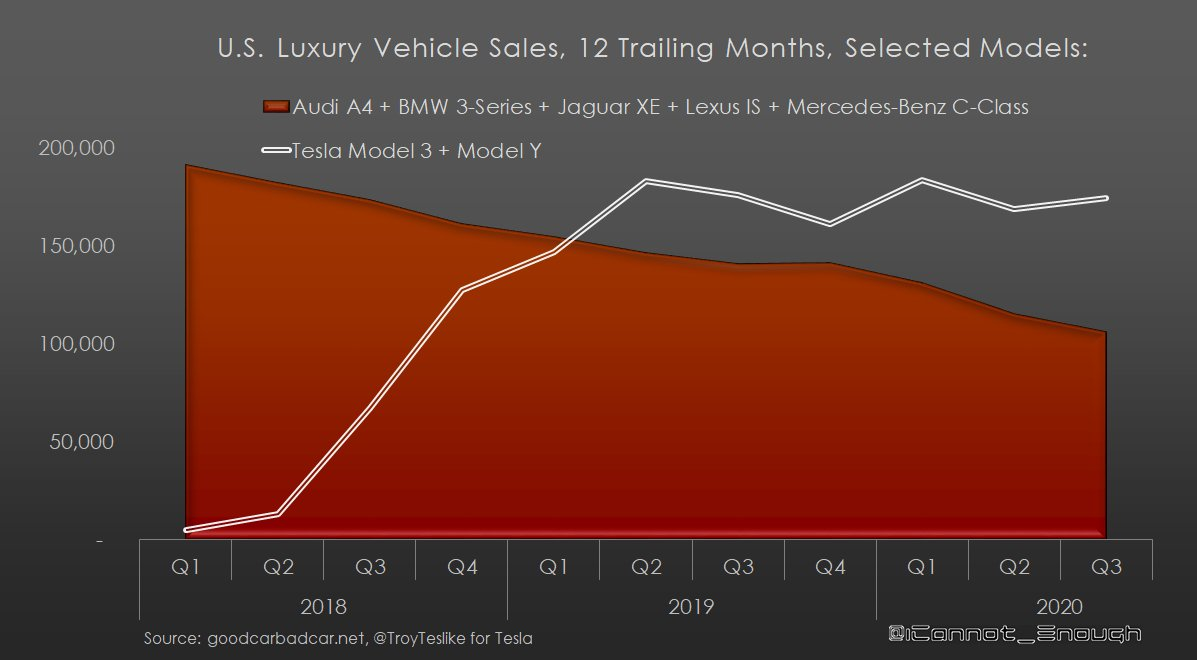
パンデミックの中にあっても、米国ラグジュアリー車マーケットにおいて、テスラは競合のエンジン車メーカをディスラプトし続けている。
テスラの競合はEVメーカーではない。テスラがディスラプトしているのは、ICE車メーカーであり、EV同士の競合に過度に焦点を当てるのは間違い。
EVのシェア争いがないわけではないが、それはあくまで年率50%で拡大しているマーケットの中での話であって、比較的マージナルなトピック。
要はテスラの心配する前に、自分のところのエンジン工場の心配しなさいよっていう話です。
https://twitter.com/ICannot_Enough

2020Q3までの数字だが、ヒドいね~。
米国市場ではテスラ以外のすべてのメーカーが販売台数で前年比マイナスであった。テスラのみプラス。
GM,FORD,FIAT,TOYOTA,NISSANと、名誉ある前年比30万台減クラブwww。
ドイツ勢、韓国勢は減らしつつも相対的には健闘しているといえる。
その販売台数の減少幅は、各社合計でマイナス240万台
↓
Q4含めた全体の数字は以下
https://www.goodcarbadcar.net/2020-us-auto-sales-figures-by-manufacturer/

トヨタ、ホンダは、栄えある「30万台減クラブ」入りはまぬがれた。Q4にインセンティブで相当に押し込んだね。GM、フォード、FCA、日産はクラブ入り。コロナ禍で前年より販売台数を伸ばしたのは、テスラ、ボルボ、マツダのみ。
https://www.goodcarbadcar.net/2020-us-auto-sales-figures-by-manufacturer/
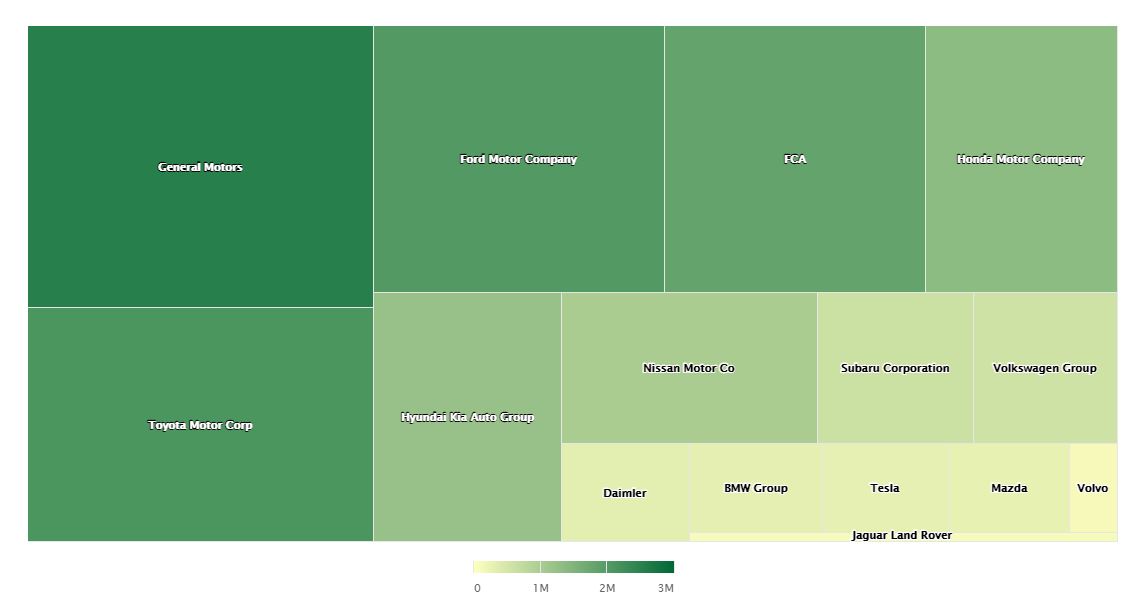
US市場では、テスラ2021はスバル、VWレベル、2022はホンダレベルまで行くだろうね。25,000ドルモデルの発売で、一気にトップに躍り出るだろう。
https://www.goodcarbadcar.net/2020-us-auto-sales-figures-by-manufacturer/
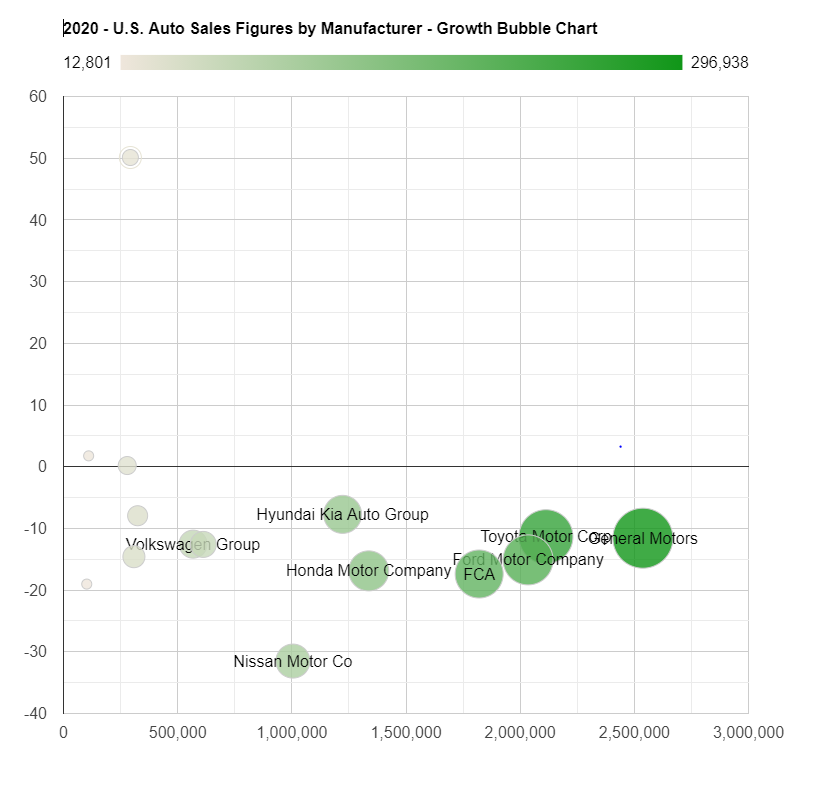
左上の50%成長しているのがテスラ。テスラだけが別のゲームをプレイしているのがわかる。ICE車メーカーは滅びるしかない。
https://twitter.com/ICannot_Enough
Q1は出荷台数が落ちるのが、米国自動車市場の通例なんだけど、テスラに限っては落ち込みは限定的というかQ4と同じ水準を維持しそう。FSDスポット購入などなどもあって売上は増加するでしょう。
↓
でもこの図もわかりやすいんだけど、上海のモデルYの生産見込みが保守的に過ぎるんだよね。
https://twitter.com/ICannot_Enough
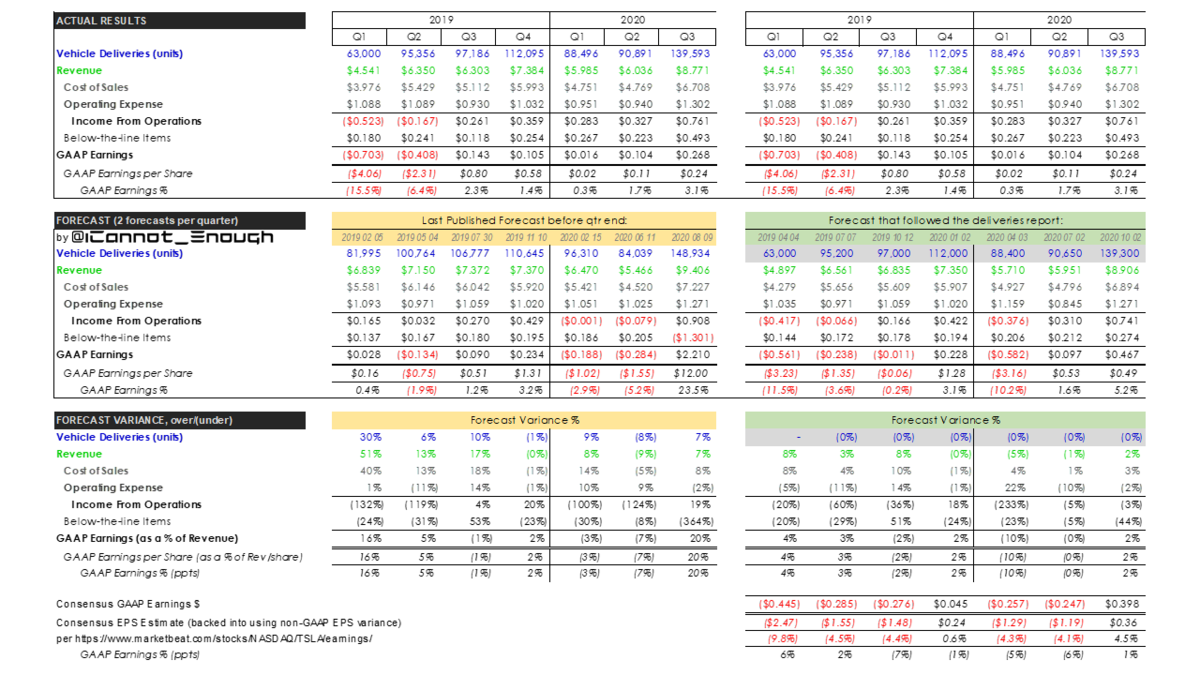
かなり正確に結果を予測してきている。
https://twitter.com/ICannot_Enough
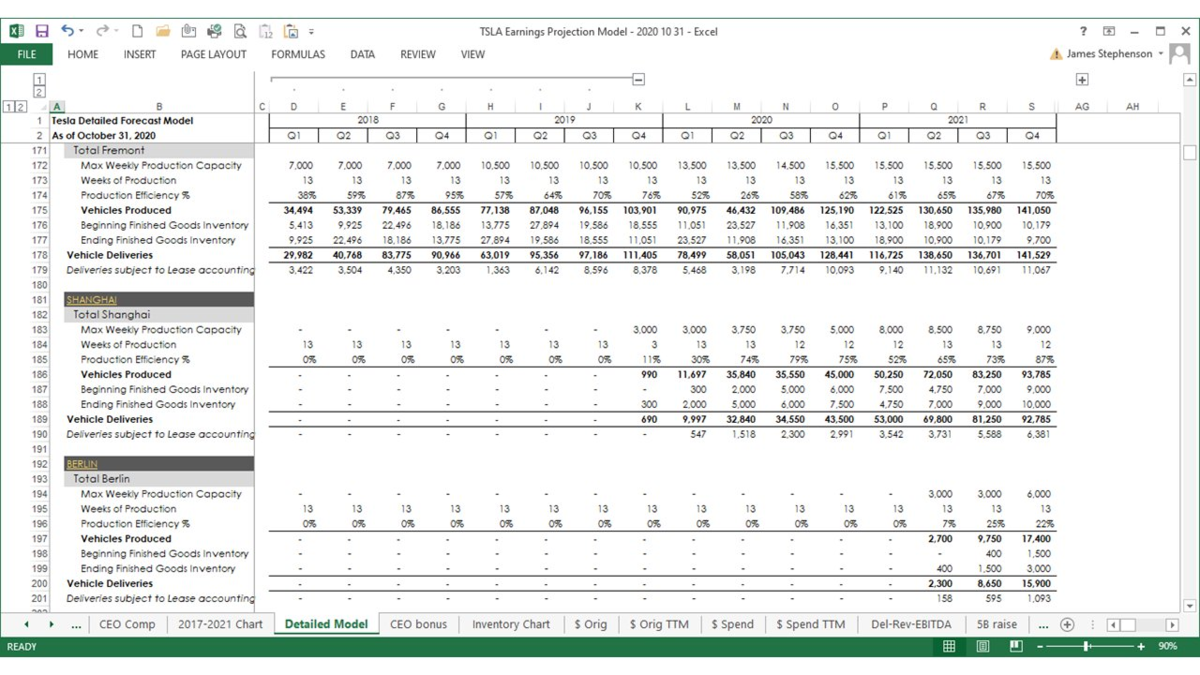
https://twitter.com/ICannot_Enough

その他コメント
・Q1に売上が落ち込むのは全社共通。テスラだけの問題ではない。でも2021年以降はテスラには当てはまらないかもしれない。
・モデル2(仮称:コンパクト・ハッチバック)の出荷は2023年くらいになるだろう。
・ザック(CFO)がプライスウォーターを説得できれば、$1.6ビリオンの繰延税金資産戻り入れ益が認められるだろう。この確率は相当に高いと思っている。
・ただこれもGAAPルールで、一度に認識することはできなくて、最大80%まで。残りの20%は次年度もしくは、次のクォーターに持ち越しとなる。
・これからFSDオプションの購入は、機能の拡張とともに、車両購入と同時になってくだろう。だから繰延収益化の比率は少なくなっていくだろう。
・米国と違ってサイバートラックのEUでの需要はそれほど大きくはないだろう。オースティンからの輸出で対応できるだろう。S & Xと同じように。
・チャイナ・オリジナルモデル、EU・オリジナルモデル、両社とも小さめのハッチバックとなるだろう。
・エナジービジネスは、バッテリー供給制約があり、オート部門のように急成長するのが難しい。どうしてもオート部門優先になってしまうからだ。
・メガパックの引き合いは莫大なものだと思うが、シンプルにセル供給がたりない。
・エネルギー事業は今年度は2桁成長はすると思うが、やはりオート事業の急成長と比べるとやや物足りなさは残る。すべてはバッテリー生産次第。バッテリー制約が解消されるまでは2~3年はかかると思う。
・ベルリンのモデルYのランプアップは相当に慎重に行われていくと思う。イーロンがカンファレンスコールでそう言っていた。4680セルや、メガキャスなど新しい試みが多いので、クリアしなければならないボトルネックが多い。
↓
他の人:メガキャスはすでにフリーモントでやってるし、4680 DBE siliconセルは、すでに多く生産されている。またQ4には、LG化学製の 4680セルも納入されるはず。ベルリンのQ4にはもっと期待していいかも。
他の人:ギガ上海は10月より、800台/日いけるので、クォーターあたり65,000台以上行けそうか?
https://twitter.com/ICannot_Enough
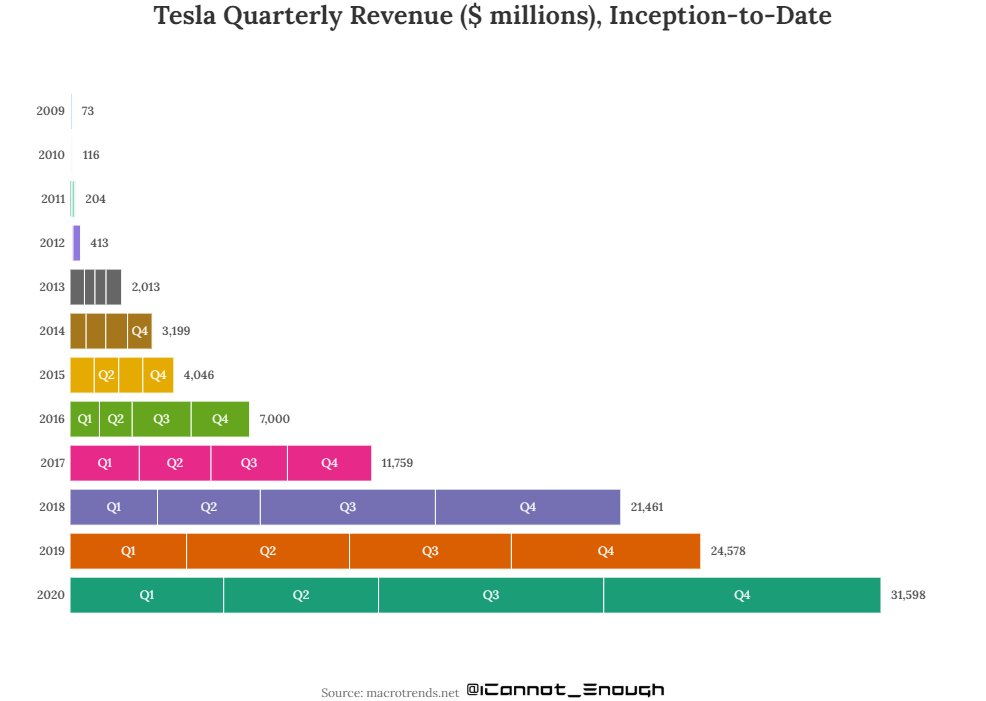
https://twitter.com/ICannot_Enough

フリーキャッシュフローの推移を見ても、2019年の後半から株価が急騰し始めた理由がよくわかる。
デイビッド・ワンさんのNIOデーツイートまとめ:NIOデーの勝者は誰か?

テスラコミュニティの反応なのでNIOには厳しい内容となっていますが、EV市場の成長に合わせてNIOの販売台数も拡大していくという前提での話です。
1/10 Quick thoughts & winner/loser prediction after watching #NIO day. Impressive event, nice sedan, wish NIO to be successful, but some concerns:
— David Wang (@DongyanWang8) 2021年1月10日
1. FSD HW from #Nvidia. HW spec does not equal good AI results. #Tesla chip is custom & optimized for Tesla only, super efficient...
①
テスラのアプロ―チである「カスタムSoCと統合ソフトウェア」という組み合わせは、Nvidiaのような汎用的なチップによるものよりも、効率的に特定の目的を達成できます。(Apple M1チップがIntelよりも優れているのと同じ)
したがって、NIOが主張する7倍の計算能力は、NIOの開発するFSDが優れたものであることを意味しません。
またNVDAのソースと、今回公表された計算能力をかけ合わせれば、消費電力はテスラの3.5倍~4倍となるでしょう。これは航続距離にマイナスの影響を与えます。
②
最も失望したのは、NIOがバッテリーとEV製造の自社工場を発表しなかったことです。独自のバッテリーと自動車製造能力がなければ、NIOの成功は大きく制限されます
③
本当に全固体電池が製品投入できるとしても、2022年第4四半期はやや遅いと思います。
ただし全固体電池として考えた場合、米国のクオンタムスケープ社よりは、素早い市場投入になります。クオンタムスケープの2025年または2027年以降のタイムラインは遅すぎます。
④
NIOのロイヤルティプログラム(車を購入するときにポイント付与、商品に使うなど)は、ある程度までしか機能しません。
ユナイテッド航空のマイレージプラスプログラムでは、多くの人がポイントを獲得するためにユナイテッドを利用していますが、他により良い選択肢があれば、乗り換えられられます
それだけでは顧客をつなぎとめることは難しいでしょう。
④
NIOデーの勝者と敗者です。
大勝者:テスラ
テクノロジー面での大きなアドバンテージが再び確認されました。
何年も前にリリースされたモデルS / Xは、いまだどのメーカーも追いついていません。
テスラのバッテリー、FSDは紛れもないリードを保っています。
勝者:#CATL 、#BYD 、#LG
もしかしたら、LGはコストの懸念のため勝者ではないかもしれない
EVレースで誰が勝ってたとしても、#CATL 、#BYDは大きな勝利を収めるでしょう。
バッテリーメーカーがEVメーカーとともに、バッテリー技術を進歩させること。
これが「EV+エネルギービジネス」の成功の鍵を握ることになります。
小さな勝者:#Nvidia
NVDAは、#Intel MobileEye 連合から勝利を収めたと思います。
NVDAは、FSDハードウェアビジネスを大きく獲得していくでしょう。
今後は、テスラ用の テスラFSDHWと、それ以外のすべてのプレイヤー向けの Nvidia FSDハードウェアという位置づけになります。(テスラは他社にライセンス供与する可能性はあります)
(ルネサスR-Carは死亡?)
短期的な敗者:NIO
NIOは、長期的には成功すると思いますが、短期から中期にかけては難しいでしょう。
テスラの3&Yは、低価格でより良い車です。
バッテリー/自動車工場と独自のFSDIPを早急に構築しないと、NIOはテスラと直接競争することはできません。
ただし、NIOは、ICE車からは勝利を得るでしょう。
NIOがバッテリー/自動車工場とFSDIPを今後構築していく場合、資本を調達するため、増資しつづける必要があります。
最大の敗者:ICE車
特にBBA(BMW、ベンツ、アウディ)は、中国で今後ますます厳しくなるでしょう。
⑤
NIOはFSDHWのみの発表でした。 アルゴリズムおよび、データ収集の発表はありませんでした。
そして、テスラのFSDウェアに対して、7Xの単純計算能力のみを強調しました。しかし FSDチップの計算能力だけではミスリーディングです。
私はAIの専門家です。優れたAIソリューションには計算能力、アルゴリズム、データが揃うことが必要でです
実証済みのFSDアルゴリズムと大量の実データがなければ意味がありません。7倍のHW計算能力だけではFSDの成功を意味しません。
さらに、NVDAの4つのチップを搭載したハードは莫大な電力を消費します。
⑥
Lidarはハードの一部分であり、FSDの成功を意味するものではありません。
多くのAI専門家、そして私もテスラのアプローチに賛同します。
つまり、コンピュータービジョン(カメラ・Rador・超音波センサー)が、FSDへの最良のアプローチだということです。
Lidar&3DHDマップはマップがない場所では使用できません。
⑦
NIOのCEOは、2022年第4四半期に150KWの全固体電池パックを搭載した車両を発売すると発表しました。
ただしNIOデー後に「NIOが固体と液体の混合バッテリーだと訂正した」と、中国メディアは報じています。
株主からマーケティング上の強いプレッシャーがあり、テスラより優れているとアピールする必要があったのかもしれません。
⑧
NIOのCEOは、NIOを「ローエンド」ではなく、BMWベンツアウディと競争するハイエンドとして位置付けています。NIOは既存のオーナー保護のために、価格を下げないといっています。
私はこの戦略が、うまくいくかどうか懐疑的です。
現代の消費者はスマートであり、派手なインテリアだけでなく、より良い車輛とを割安な価格を選好するからです。
⑨
NIOのロイヤルティプログラムは、古くからのオーナーが、新車を購入する際に、大幅値引き、FSDの月額サブスクリプションを提供するようです。
これは新規オーナーを犠牲にした販売方法です。
それとは逆にテスラオーナーは常に、過去と比べてベストな価格で最良の機能を手に入れることができます。
⑩
NIOはテスラとの競争において、途方もないプレッシャー(価格、コスト、FSD)にさらされていると思います。テスラが 3 / Yの価格を下げてきました。S / Xのアップデートもありそうです。
問題は、NIOが今後もプレミアム価格を維持できるかどうかです。
⑨
販売量の拡大、生産コストの削減を達成するまで、顧客にプレミアムカーのステータスを納得させつづけ、高価格を請求し続けることができるのか。
もしくは独自のバッテリーとファクトリーを建設するために資本を調達しつづけ、徐々に販売価格を下げていくのか。どちらも難しい戦略です。
⑩
その他の企業に関してです。CATLの高成長は長続きすると思います。EV/エネルギーという新たなゴールドラッシュにおける、シャベルとジーンズとなるでしょう。
BYDは何十年もの間バッテリー開発・製造に取り組んできました。
独自のバッテリー/自動車製造および技術スタックを所有しています。
新しい「ブレード」バッテリーが大きな注目を集めました。
車のデザインはすぐに良くなってきます。
EVバスの製造と輸出も強みです。
$TSLA、$CATL 、$BYDDYの3社は巨大なEVアダプションのメガトレンドに乗って2021年も上昇していくでしょう。
NIOは長期的には成長するでしょうが、将来の成長力から見てバリュエーションが非常に高く、リスクが高いため、慎重に検討する必要があります。
また、NIOはテスラをライバル視するのではなく、ICEカーからいかにシェアを奪っていくのか、その競争により焦点を当てるべきだと思います。
Apple + Hyundaiは良い考えだとは思いません。私はAAPLは車に関してもBYDと提携すべきだと思います。すでに提携の実績はあるのですから。
中国のEVサプライチェーンは、機能と低コストの両方ですでに確立されています。
Apple+BYDは、普及への最速ルートだと思いますが、しかしそれでもテスラの競合となることは難しいと思います。
厳しめの反応
Why didn’t Nio do their own batteries or FSD chip?
— ⚡️特拉风🦔T☰SLA mania⚡️ (@Tesla__Mania) 2021年1月10日
Because they simply don’t have the tech.
Nio is exactly like a traditional auto, buying parts from suppliers and assemble them. They are offering low tech stuff, aka “high end services”😂
Good luck selling PowerPoint slides. https://t.co/7OrjbDOIFg
Nioが独自のバッテリーやFSDチップを公表しなかったのはなぜ?
「ラグジュアリーライフスタイル」ブランドとしてポジショニングしようとしているのはなぜ?
単に実現するための技術を持っていないからです。
NIOは従来の自動車メーカーとまったく同じで、サプライヤーから部品を購入して組み立てるだけです。
NIOはローテクなものの別名すなわち「ハイエンドサービス」を提供するだけです。
パワポスライドの販売頑張ってください。
その他の人
・バッテリー交換とLiDARは無用の長物です。
・バッテリー交換ステーションの設置は、チャージングネットワークよりも、多額の資金を必要とします。
・実際は、すべての交換ステーションに人員を配置しなければいけません。
・交換バッテリーが充電中の場合、交換予定時刻までの待機時間が発生します。
・ピーク交換需要に合わせたセル数を生産しなければならず、コスト高です。
・テスラはずっと前にバッテリースワッピングを検討しましたが、計画を放棄しました。
・パックサイズが異なるモデルが混在していますが、どのように交換対応するのか、予備バッテリーを保管しておくコスト負担も大きなものになります。
〇個人的感想
NIOデーは、最初のコンサートの時点で、見る気なくしたんだよね。
コンサートを最初から持ってくる時点で「うわべの取り繕い」を感じて。
「これって既存のICEメーカーのカタログ(パワポ)エンジニアリングの手法と一緒じゃん」って。
ゼロベースで技術開発してないから「販売ネットワーク力」と「イメージ戦略」と「目くらまし多品種少量オプション戦略」で勝負するしかない。
ネーちゃん(若いとはいってない)に厚化粧さして田舎者のジジイに、そこそこの高級車売りつけるレクサスみたいな妄想戦略(元RXオーナー乙)。
カップホルダー・イノベーションというか、カタログ・エンジニアリングであるがゆえに生み出される製品の持つ、あの独特の「コレジャナイ感」ね。
別の言い方すればコレ↑みたいな。
ただ充電器につなげばいいだけなのに、大量の蓄電池コストとか、ロボットを動かす機構とか、不必要なメンテナンスとか実現する意味が全くない雰囲気技術。
「なかなか革新的なサービスじゃないか、その方向で進めたまえ」っていう言葉が目に浮かぶ会議風景というか・・・
本当に必要なものを、古いしがらみ抜きにゼロから考えていない。それゆえに生み出される、消費者を「ナメてる」感。「お前らの欲しいものなんてこの程度だろ」という見下し感。既存の枠組みの中でしか思考してないことから生み出される「コレジャナイ」感。
車内マスコットとか、マッサージ機能とか要りますか?ニオ・オーナーハウスとかホントに利用したいですか?ウーブン・シティと同じ気持ち悪さを感じません?
全てがそろっていて、至れり尽くせりです!っていって、だけど肝心な欲しいものが微妙な店屋みたいな。
プロダクトで差別化できないから、イメージで差別化する古典的なマーケティング戦略にしか見えない。
ホントに革新的なプロダクト作ってたら、あんなイメージアピールいらないから。
テスラのバッテリーデーとかオートノミーデーっては簡単なイメージビデオのあと、即座に技術説明会になったわけでしょ。
伝えたい革新的な取り組みがいくつもあるから。で株価を吊り上げることが目的じゃなくて、リクルートが目的だから。世界最高水準のエンジニアを一人でも多くテスラに呼び込みたいから。
「あなたが自分の才能をフルに発揮できる、ワクワクする、チャレンジングなフロンティアがここにありますよ!」
って猛烈にアピールしてたわけでしょ。
バッテリースワップだって、テスラの「セル・ツー・シャシー技術」で、極限までレンジ効率改善しようという試み見てたら、重量増、エネルギー密度減でしょ。コスト面、安全面考えてもお笑いのネタでしかなくない?
NVDAだって、テスラはFSDシステムメーカーとしてはとっくの昔に見捨ててる。NVDAは、あくまで優れた汎用GPUをつくるメーカーであって、専用GPUメーカーではない。NVDAの自動運転用GPUは、幅広い顧客に対応するために、チップレベルですでに余計な機能が満載されている。あれユニットあたりおそらく3千ドルはするし、しかも電気バカバカ食って航続距離犠牲にするよ。
そもそもFSDにGPUが最適なのかという根本問題もある。そこでテスラは、消費電力を喰うDRAMをチップ上から大きく減らして、SRAMを採用し、NN計算に特化させたチップを独自開発して、それにニューラルプロセッサーという名前を与えた。
NVDAのORINは、使い物になるレベルの計算させようとしたら、電気喰いまくって大幅に航続距離短くなるよ。
株価押し上げておいて、増資しまくって、その資金で研究開発費や投資をファイナンスするための、ハイプ・デーの感じがするなあ。
テスラよりチョイ安の雰囲気EVなんとか形にして、拡大するEV市場の中で一定のシェア握って、そのうちワンちゃん狙えればOK!って戦略に思えるなぁ。
EVという成長市場にいるんだから、そりゃ成長はしますけど、それだけの存在な気がする。
あと全固体(か準固体かしらんけど)電池系は、もう何年も噂や新発表ばっかり聞かされ続けて聞き飽きた。
いくらでも出せるコンセプトやプロトタイプはもういいです。
ギガワット級の供給力あって、採算のとれる可能性のある、全固体電池の量産ライン早く実際に作ってくれや。
かりに準固体でなくて全固体電池だとしたら、世界中の研究者が取り組んでいて、ラボレベルでも達成されていないブレークスルーがまだいくつもある技術。それなのに、2022年に車載用の全固体電池の量産なんか絶対にできない。
それともNIOやそのサプライヤーは、ノーベル賞級の発明できる研究者やエンジニアを、いままで一切の研究発表させずに何十人も隠して養成していて、技術開発済みで、パイロットラインも製造済みなのかい?なわけないよね。
しかも世界最高の頭脳と経験を持つエンジニアを集めまくっているテスラを差し置いて。
そもそも全固体電池は車載用には向いてないしね。
サプライヤーが「できる可能性があります!それに向けて努力します!」っていう社交辞令トークを実際の投入予定製品として発表しちゃだめよ。株価押し上げのために。
実際に開発主導してないからああいう発表ができるんだと思う。あとで全部サプライヤーのせいにすればよいから。
あとFSDに関しても、シミュレーションでは全く不十分。実データの収集と、その実車両への「シャドー・モード」によるフィードバックのループが軽視されているとしたら、それは大きな間違い。
現実をシミュレーションできるエンジニアなんて存在しないのだから。ロングテールというか、6シグマの安全性を保障するには、シミュレーションじゃ無理。実車輛との大規模なフィードバックループが絶対に必要。
テストの答え合わせを自分で採点するような環境で鍛えたって実戦で使えるものはできないよ。
AlphaGOとかにたとえるアナロジーも間違い。碁はそもそも完全情報ゲームでしょ。碁盤ひっくり返すような相手にも安全に勝つ方法なんて考える必要ないでしょ。
現実の道路では動物がいたり、看板がマチマチだったり、なんでもありですから。
個人的には今の株価からNIOはないな。だったらBYDかCATL含んでる商品に投資するな。
ウォール街のプロからの公開書簡:現役アクティブ・ファンドマネージャーの皆様へ
短期的な株価の上下はあったとしても、テスラ株はバブルではありません。
Open letter to all S&P 500 benchmarked managers:
— Gary Black (@garyblack00) 2020年12月15日
On Friday 12/18 at market close, $TSLA will enter the S&P 500 Index at an approximate 1.5% weight - the sixth largest weight in the S&P 500 index after $AAPL, $MSFT, $AMZN, $GOOGL, and $FB.
S&P 500をベンチマークとしているファンドマネージャーの皆さんへ
テスラはS&P 500指数に12月18日の終値でおよそ1.5%の比率で組み入れられます。S&P 500指数の中では、6番目の時価総額になります。
GSによると、皆さんのファンドのうち90%は、現状ではテスラ株を保有していません。またバリューを重視する皆さんは、テスラ株に興味を抱いたこともほとんどなかったことでしょう。
テスラは年初来で665%も上昇し、コンセンサスEPS予想の169倍ものPEで取引されているのですから、それも当然のことです。
皆さんには、この株価上昇をやりすごして、株価が地上まで墜落してくるのを待つという選択肢だってあります。
しかしそれは大きな間違いだと申し上げたい。
CNBCに出てくるような解説者は、テスラのこと何も調べもせず「割高だ」と喧伝します。
ロングショート系の有名人(ジム・チェノス、デイビッド・アイホーンなど)や、セルサイドのアナリストは、当然のことのようにテスラを既存の自動車メーカーと比較します。しかし彼らのテスラについての見通しは、何年ものあいだ、ずっと間違ってきたのです。
自分のことをスマートだと思っている彼らが、テスラ株の上昇し続ける理由について述べるのを聞くと、中身のない空っぽな意見だと私は感じます(ロビンフッダーによる投機的な買い上りに過ぎない!などなど)。
なぜテスラが上昇し続けるのか、そして2021年もさらに倍増しうる可能性を持っているのか、私がその理由をお教えしましょう。
(もし皆さんが、ベンチマーク上で1.5%のウエイトを占める株が1年で2倍になるのを逃したとしたら、150ベーシスのパフォーマンスを犠牲にすることになるのですから!)
まず初めに、
EVは今後急速にガソリン車に置き換わっていきます。
現状ではEVのグローバルでのSAARは3%に過ぎませんが、これが急拡大していきます。
アップルの iPhone を手にした時のように、一度でもEVに乗ってしまえば、顧客はもうガソリン車に戻ることはありません。
その結果2025年までに、EVのSAARは、グローバルで20%に達することでしょう。
ここで簡単な算数をしてみますと、
20/3 = 6.7x = 46% CAGR.
つまりEVは年率46%で急成長する市場なのです。
次に、テスラはグローバルなEV市場において、すでに圧倒的なリーダーです。
今年のグローバルでのシェアは25%に達します。
これだけ競合がいる中でテスラのシェアは減るどころか拡大し続けているのです。
(中国では100以上のEVメーカーがあるとされていますが、その中国においてさえテスラのシェアは減るどころか拡大しています。成長する市場でシェアが拡大!)
またテスラのTAMも上昇し続けています。モデルYがクロスオーバー市場に投入されたことで、テスラのUS市場における TAM は 24% から 65%まで上昇しました。サイバートラックが発売されればTAMは 86%まで上昇します。
アップルの iPhoneと同じように、内燃機関メーカーのブランドが作るEVが、ブランド力でテスラのEVの競合となることはありません。
また彼らの作るEVは、バッテリー航続距離、パワフルさ、FSDやソフトウェア、バッテリーも含めた製造コストにおいてもテスラの競合とはなりません。
また内燃機関メーカーというブランドは今後急速に色あせていきます。
7/ Valuation: This is where normally smart people get off track. With $TSLA vols and EPS growing by 50%+ per year, no portfolio mgr would put a auto mfr P/E of 8-10x on TSLA. If one looks at 2022/2023, my P/Es are 67x 2022 EPS and 43x 2023 EPS. That’s a 2022 PEG of 1.3x. pic.twitter.com/ihgFYSQrN5
— Gary Black (@garyblack00) 2020年12月15日

さらに12月15日の終値をベースに、テスラのバリュエーションを考えてみます。
上述の「自分をスマートだと思っている人々」のほとんどがここで本筋を見誤ってしまいます。
テスラの販売台数とEPSが、今後年率50%で成長していくときに、既存の内燃機関メーカーに与えられている8~10倍のPEを、テスラにも与えるファンドマネージャーはいないでしょう。
既存の内燃機関メーカーと、世界最高の純粋なEVメーカー(世界最高のFSD、バッテリー技術、BMS)とを同列に比べることはできません。
私の2022年の予想EPSを見てみれば、PEは67倍です。
(ゲーリーさんの数字は、ロボタクシーとか、エネルギー事業の拡大、保険事業の拡大とかはカウントされてないもので、テスラブルの中では控えめな数字です。販売台数も年率50%増というのも3つのギガファクトリー(上海、ベルリン、オースティン)のフル稼働を考えれば控えめな数字です)
これはPEGレシオで見れば、1.3倍に過ぎません。
2023年の予想EPSを見てみれば、PEはたった43倍です。
PEGは1倍を下回ります。
8/ There are no mega cap growth companies forecasted to grow by 50%+ per year trading at $TSLA ‘s 1.3X 2022 PEG. FB has the cheapest PEG at 1.1x; AMZN and GOOG are both at 1.3x, but all with lower growth. R1000G trades at 2x forward growth. S&P 500 trades at 3x forward growth. pic.twitter.com/bhfpPgu7mq
— Gary Black (@garyblack00) 2020年12月15日

これを他のメガキャップ・グロース株と比較してみます。上述のようにテスラが年率50%成長するならば、テスラのPEGは1.3倍に過ぎません。
この中でテスラよりも割安なPEGを与えられているのは、フェイスブックだけです。
アマゾンとグーグルはテスラと同じPEGを与えられていますが、成長率はずっと低いです。
ラッセル1000グロース指数は、2倍のPEGを与えられています。
S&P 500指数に至っては、3倍ものPEGが与えられています。
テスラが割高ならば、AAPL, NVDA, PYPL, LULUなどなど、これらはみな超割高です。
ではテスラの株価はどれくらいが妥当なのでしょうか?
2025年にEVのシェアが20%として、テスラが現状と同じ25%のシェアを実現するとしましょう。また廉価モデルの発売により、平均販売価格は下がると予想し、排出権によるクレジット収益はゼロとして考えてみます。
わたしの予想では 2025年の EPSは $24ドルです。
ここでPEを50倍(PEGは2倍を想定、すなわちEPSGは25%を想定)とするならば株価は1,200ドルとなります。
( PE 50=2×25 もしくは PEG 2=50÷25)
(PE=PEG×EPSG もしくは PEG=PE÷EPSG)
(PEG2倍は成長株では十分正当化される。)
(DCFではなくDDMを、PSRではなくPEを使うことは議論の余地がありますが、わたしはゲーリーさんの手法の方が100倍マシだと思います。PSR(4x)とか壮大なジョークだと思います。)
テスラのディスカウントレートは9.5%近辺なので、現状の理論株価は830ドルが妥当だと考えます。
もし2025年に現状と同じEPS成長を実現しているならば、PEGを2倍とすれば、理論株価はさらに倍増します。
現時点(12月15日)から12月18日のクローズまで、 S&Pインデックスファンドは、テスラ買いその他売りモードになる可能性が高いです。
そこでベンチマーカーの皆さんも同じことをされてはいかがでしょう。
ご自身のファンドの1.5%をテスラ株とすれば、ベンチマークに劣る心配をすることなく、夜もぐっすり眠ることができるのですから。
ウォール街のプロが教えるGSアップグレードの舞台裏
水曜日にGSアナリストによる71%もの目標株価のアップグレード($455→$780)を受けて、アフターで3%ほど上昇したテスラ株ですが、その舞台裏をゲーリーブラックさんが暴露してくれています。
一言でいうと、ベンチマーカー焦ってるぅ!
ベンチマーカーとは、インデックスファンドとは異なりアクティブファンドではあるものの、S&P500などのインデックスをベンチマークとして、そこからのパフォーマンスで報酬を受け取る、ファンドマネージャーのことです。
その規模はS&P500インデックスファンドに匹敵するともいわれています。ただ彼らはアクティブファンドなので、テスラをポートフォリオに入れる義務はありません。
しかし、今後ベンチマークが1.5%もの比率でテスラを組み入れるときに、その株を全く所有していない場合は、顧客に説明が必要です。また、テスラをアンダーウェイトするということは、テスラをファンドのパフォーマンス上ショートしていることになります。またルール上一銘柄あたりのショートキャップが設けられていることも多いです。
よって、テスラを組み入れないということ。これはこれでベンチマーカーにとっては大きな賭けなのですね。
ではどれほどのアクティブファンドが、すでにテスラをポートフォリオに組み入れているのでしょうか?
このブルームバーグの記事によると
Tesla’s S&P 500 Entry Takes Away Secret Weapon for Stock Pickers
”Not many of the 215 active managers with at least $500 million in assets whose funds are indexed to the equity gauge have ventured to invest in Tesla. But the 21 who have are richer for the move.”
500ミリオン以上のアセットを持つベンチマーカー215のファンドのうち、わずか21ファンドしか、テスラ株を持っていないようです。10%ですね。残りの90%のファンドはテスラを持ってません。
これは無理もない話で、彼らの眼が節穴というわけではありません。これらのファンドのほとんどはバリューオリエンティッドなので、テスラのフォワードPE見てビビッてしまうのです。
またそのPEを正当化するストーリーを手に入れるインセンティブもなかなか生まれません。なぜならS&P500に入っていなかったということは、ベンチマークの対象外であるので、その株がどのように動こうが自分の評価・報酬には影響しないので、注目する必要もなかったからです。
ところが。。。
I’ve gotten several DMs today from analysts who work for active managers asking if I could send my $TSLA model to them (I don’t). But it implies that $8T active mgrs (in addition to the $5T indexers) are trying to determine whether they want to own TSLA, given its bm 1.4% wt.
— Gary Black (@garyblack00) 2020年12月3日
ウォール街出身のプロの中ではNo,1のテスラフォロワーのゲーリーさんのところに、「ゲーリーさんのモデルをファンドマネージャーに送っていいか?」と、アナリストから複数の問い合わせが来ているようです。
つまり、アクティブポートフォリオマネージャーたちは、アナリストに(今さら)テスラの情報集めさせてる真っ最中なんですね。
でS&P500入りを含めたこの状況を、絶好のチャンスとみなしたのが、GSのアナリストのマーク・ディレニーです。彼はテスラの目標株価を外しまくってきたので、投資家の信頼は薄いのですが、ビジネスチャンスは逃さないようです。
アナリストのインセンティブは手数料です。アナリストは顧客がGSにもたらした手数料をベースに報酬を受け取ります。(また取引手数料のみならず、アクティブファンドが保有したテスラ株をショートに貸し出すことによる金利の鞘取り収入からの報酬も見込めます。)
Skeptics’ argument stupid that GS upgraded $TSLA to Buy and raised PT 71% so GS can be on the cover of new secondary. More likely, GS analyst Mark Delaney recognized that with S&P inclusion, there’d be huge interest and new commission flow from institutions currently underweight.
— Gary Black (@garyblack00) 2020年12月3日
Here’s what happens on the GS sales floor when Mark Delaney upgrades $TSLA to Buy and raises his PT from $455 to $780:
— Gary Black (@garyblack00) 2020年12月3日
1/ Each Institut’l salesperson calls their biggest commission paying clients first (Fidelity, Capital, HFS) and talks up the upgrade, and why it’s so great.
このアップグレードを受けて、営業部隊が一斉に電話をかけ始めます。まずは一番手数料を落としてくれるクライアントからです(フィデリティなど) 。でアップグレードやテスラの素晴らしさについてまくしたてます。
2/ Since most GS clients do not hold $TSLA, much of the sales pitch is that Mark and his team will help the buy side client’s research teams with models, conf calls, etc. with the goal that if the client decides to add TSLA, they trade through GS.
— Gary Black (@garyblack00) 2020年12月3日
GSのクライアントのほとんどは、テスラ株を持っていないので、意思決定に使えるレベルのテスラの情報がありません。で「バイサイドのリサーチチームの手助けします!」「モデルの作成やカンファレンスコールで手助けすします!」などなど、あれこれオファーするわけです。
でクライアントがテスラポートフォリオにを採用すると決めれば、GSを通じて取引するよう仕向けるわけです。
3/ Even at GS, Mark’s comp as a research analyst is directly related to his commission $ that come in as a result of his research. With Chinese walls between research and underwriting, Mark’s comp should not be tied to whether $TSLA uses GS to do a TSLA secondary (yeah, right).
— Gary Black (@garyblack00) 2020年12月3日
つまり、マークディレニーなどのアナリストの報酬は、彼のリサーチがもたらした手数料とダイレクトにリンクしているから、このタイミングで、このようなアップグレードが起こるのです。
ちなみにS&P500入りを目前に、テスラが増資をする可能性に賭けて、その引き受けを狙い、テスラをアップグレードしたのではないかと邪推する向きもあるのですが、ゲーリーブラックさんは、その意見を一蹴しています。
そもそもアナリスト業務と引受け業務は完全に分離されているので、アナリストのアップグレードで引受けがスムーズに進むようなインセンティブ設計ではないのです。
Last point: A call like the $TSLA upgrade is a big call for the GS sales team, because TSLA is so actively traded, and there’s plenty of upside commissions ahead from S&P inclusion. A 71% PT increase is huge. Only negative: Mark’s been wrong on TSLA so lacks credibility.
— Gary Black (@garyblack00) 2020年12月3日
このような大きなアップグレードは、GSの営業チームにとっては大号令で、みんな目の色変えて電話している真っ最中でしょう。テスラ程取引量が多い株がS&P500入りとなれば、それに伴う手数料のアップサイドは莫大です。
で結局のところベンチマーカーたちはどのくらい買ってくれるのでしょうか?
これは株価に応じて現在進行形で変わっていくのでなんともいえません。
ただ高いから買わないという選択肢がなかなか取りずらい状況にベンチマーカーたちが追い込まれているというのは事実でしょう。
フロントローディングするのか、S&P500入り後に徐々にポジションを増やしていくのか、まんべんなく買っていくのか。いずれにしてもアクティブマネージャーたちも買い出動しなくてはならなくなっています。
S&P500入りの後の「ニュースで売れ」でポジション増やしたいベンチマーカーは多いでしょうが、どうなるでしょうか。
少なくともQ4決算の前にはある程度買っておきたいベンチマーカーは多いはずです。
ちなみにブラックさんの相場観は
Reiterating my view:
— Gary Black (@garyblack00) December 4, 2020
1/ $TSLA peaks between $650-$690 the w/o 12/14-12/18 as $5T in index AUM has to buy 120M TSLA shares at mkt.
2/ In the 2 wks after inclusion, TSLA retreats 10-20%.
3/ 500K delivs for FY’20 implies 4Q delivs of 181K, a big ask (1/4).
4/ My 6-12 mo PT is $830.
S&P500インクルージョンで$650~$690で、そのあと2週間で10%~20%の調整があるというものです。
もし$700から20%調整すれば$560ですからね。
現状の株価はブラックさんによりれば、このイベントに関してはいいところまで織り込んでいるということになります。
ただ金曜日にブラックさんは目標株価を上方修正しました。
$720→$830(今後6~12か月以内の目標株価)
これはテスラの、10月までの今年のEV市場におけるシェアの上昇(17%→25%)を受けてのものです。
この株価を一気に織り込みに行くのか、徐々に織り込みに行くのか、いずれにしても要注目です。
3億が60億に?テスラのコール・オプションを買いまくった投資家:エメット・ペッパーズ
ま60億になったわけじゃなくて、ポテンシャルの話なんですけどね。ただコールオプションをUSD2.7ミリオン分買ったのは事実みたいです。
エメットさんが買ったのは、
$TSLA call JAN 15'21 $700
ですね。このオプションは1単位が、
「2021年1月15日に、テスラ株式100株を、1株あたり700ドルで買う権利」
を表しています。
しかも買ったその数なんと3,500個以上
つまりテスラの株式を35万株購入する権利を買ったわけですね。
ただ実際にオプションで、権利を行使する場合は少なく、満期の前に反対売買するのが普通です。
で、購入価格を抑えるためにコールスプレッドを組んだわけでもなく、
単純に裸単騎のド根性コール買いです。
S&P500採用が決まった翌日に、オープン前にインタラクティブ・ブローカーズ証券のブロックトレーディングデスクに電話してアシストしてもらいながら、最初の45分間で5.5ドル~6.85ドルの間で約定させました。
(日本でオプション投資するなら、IB証券が事実上の選択肢となると思います)
で当該オプションは11月24日の時点で$17の値段がついてますので、およそ2.5倍になってますね。
3ミリオンはすでに含み益が発生しています。すごいです。
そしてなんと「このトレードは20Xのポテンシャルがあると思ってエントリーしている」と冷静に語っています。2か月弱で20バガーの達成です
彼の予想通りになるならば、2.7ミリオンが54ミリオンになります(白目)。
期限を区切ってボラティリティの概念を導入することで、数百倍の利益もしくは損失というすさまじい損益の出方を可能にするのがオプションの醍醐味です。
逆に現物株をホールドしていれば、実に多彩に損失と利益の出方をコントロールできるのもオプションの素晴らしさです。
ちなみに
オプション投資には、デルタ、ガンマ、ベガ、セータのグリークスのある程度の理解が必須です。
株価の変動に対するオプション価格の微分がデルタで、デルタの微分がガンマです。
つまりデルタが速度で、ガンマが加速度ですね(高校物理www)。
ボラティリティに対する反応度がべガで、タイムディケイがセータです。
エメットさんのベットは、ディープアウトオブザマネーのコールを買ってるわけですから、先ずはある程度セータを犠牲にして、ベガをロングしてる戦略です。このケースではデルタとガンマは、当初はほとんど反応しません。
で、彼の予想が実現するためにはテスラの株価が、どれくらいの期間で、どれくらいまで到達しなければならないのでしょうか?
正確な数字は難しいですが、およそ850ドルくらいですね。しかも年末年始ぐらいまでに。年末までに、それぐらい行けばタイムディケイを考慮しても20バガー達成できると思います。
購入時点の株価がおよそ450ドルですから、1か月強で400ドル以上のアップサイドを見込んでるんですね。
彼が自分のトレードの一番の根拠に挙げているのはズバリ
「売り手の不足」です。
現在のマーケットのボリュームのほとんどはアルゴ取引がつくりだしていることは周知の事実です。
彼はもともとマーケットメーカー関連の仕事をしていたらしいのですが、その経験から、テスラなどの人気株を長期にホールドしている投資家は空中戦にはあまり参加していないとしています。マーケットのボリュームのほとんどは、アルゴとロビンフッダーが空中戦を演じていることにより、作り出されていると語っています。
だからインデクサー、ベンチマーカーたちの本気の買いがやってくるときに、実は積極的な売り手はさほどいないというのが彼の主張です。
すなわちS&P500入りで「インデクサーたちは誰から株を買うんだ問題」が発生すると。
また現在進行形で、ベンチマーカーたちも、今ここでテスラをポートフォリオに加えるかどうかの決断を迫られています。ここまで大きい時価総額のものがインデックスに組み入れられるのに、それを無視して、ベンチマークに勝とうとすると、必要のない苦労がつきまとうわけです。
そもそもベンチマークが1.34%以上の比率で組み込もうとしている株を、それ以下の比率でしか持たないということは、ベンチマーカーたちにとっては、その株を事実上ショートしているのと同じことです。
それで果たしてベンチマークに勝てるのか?という問題もさることながら、普通は1銘柄あたりのショートキャップがあると思います。今回はそれに抵触する可能性が出てきます。そうするとキャップ解消まで現物を買わなければならなくなります。
その分の買いもインデクサーほどではないにしろ、見込めると述べています。
つまりインデックス・スクイーズがゲーリーブラックさんなどの想定よりも大規模に起こると考えているわけです。
その過程で株価は800ドルも突き抜けていくだろうというシナリオにベットしているわけですね。
また、ここまで時価総額が大きくなってくると、ヘッジファンドはショートしようとしても、キャップがかかってしまって、ほとんど株価にプレッシャーを与えられないだろうとしています。ショート勢も脱落していくからその意味でも「売り手不足」との見解も持っています。
まとめると
・インデクサーの買い
・ベンチマーカーの買い
・ショーターのキャップ制約
・熱狂的な長期投資家
などが、インデックス・スクイーズを引き起こすということでしょう。
(あとデルタヘッジにもとづく事実上のロックアップフロートも面白いトピックとしてあるのですが、それはまた別エントリーで)
ま、彼は個人資産30ミリオンUSDを超えているので、2.7ミリオンのベットが可能なわけです。資産の10%未満のベットです。資産をオールインしているわけではないのです。
本人もインタビュアーもこういったタイプの取引は、マーケットがちょっとでも調整すれば全額失う可能性があると、繰り返し注意喚起しています。
それにしても12月中旬がますます楽しみになってきました!
700ドルコール今から買っても5バガーはいけるかな(ボソッ)